 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchored Decoding: Provably Reducing Copyright Risk for Any Language Model
Feb 06, 2026Modern language models (LMs) tend to memorize portions of their training data and emit verbatim spans. When the underlying sources are sensitive or copyright-protected, such reproduction raises issues of consent and compensation for creators and compliance risks for developers. We propose Anchored Decoding, a plug-and-play inference-time method for suppressing verbatim copying: it enables decoding from any risky LM trained on mixed-license data by keeping generation in bounded proximity to a permissively trained safe LM. Anchored Decoding adaptively allocates a user-chosen information budget over the generation trajectory and enforces per-step constraints that yield a sequence-level guarantee, enabling a tunable risk-utility trade-off. To make Anchored Decoding practically useful, we introduce a new permissively trained safe model (TinyComma 1.8B), as well as Anchored$_{\mathrm{Byte}}$ Decoding, a byte-level variant of our method that enables cross-vocabulary fusion via the ByteSampler framework (Hayase et al., 2025). We evaluate our methods across six model pairs on long-form evaluations of copyright risk and utility. Anchored and Anchored$_{\mathrm{Byte}}$ Decoding define a new Pareto frontier, preserving near-original fluency and factuality while eliminating up to 75% of the measurable copying gap (averaged over six copying metrics) between the risky baseline and a safe reference, at a modest inference overhead.
Are you going to finish that? A Practical Study of the Tokenization Boundary Problem
Jan 30, 2026Language models (LMs) are trained over sequences of tokens, whereas users interact with LMs via text. This mismatch gives rise to the partial token problem, which occurs when a user ends their prompt in the middle of the expected next-token, leading to distorted next-token predictions. Although this issue has been studied using arbitrary character prefixes, its prevalence and severity in realistic prompts respecting word boundaries remains underexplored. In this work, we identify three domains where token and "word" boundaries often do not line up: languages that do not use whitespace, highly compounding languages, and code. In Chinese, for example, up to 25% of word boundaries do not line up with token boundaries, making even natural, word-complete prompts susceptible to this problem. We systematically construct semantically natural prompts ending with a partial tokens; in experiments, we find that they comprise a serious failure mode: frontier LMs consistently place three orders of magnitude less probability on the correct continuation compared to when the prompt is "backed-off" to be token-aligned. This degradation does not diminish with scale and often worsens for larger models. Finally, we evaluate inference-time mitigations to the partial token problem and validate the effectiveness of recent exact solutions. Overall, we demonstrate the scale and severity of probability distortion caused by tokenization in realistic use cases, and provide practical recommentions for model inference providers.
Broken Tokens? Your Language Model can Secretly Handle Non-Canonical Tokenizations
Jun 23, 2025Modern tokenizers employ deterministic algorithms to map text into a single "canonical" token sequence, yet the same string can be encoded as many non-canonical tokenizations using the tokenizer vocabulary. In this work, we investigate the robustness of LMs to text encoded with non-canonical tokenizations entirely unseen during training. Surprisingly, when evaluated across 20 benchmarks, we find that instruction-tuned models retain up to 93.4% of their original performance when given a randomly sampled tokenization, and 90.8% with character-level tokenization. We see that overall stronger models tend to be more robust, and robustness diminishes as the tokenization departs farther from the canonical form. Motivated by these results, we then identify settings where non-canonical tokenization schemes can *improve* performance, finding that character-level segmentation improves string manipulation and code understanding tasks by up to +14%, and right-aligned digit grouping enhances large-number arithmetic by +33%. Finally, we investigate the source of this robustness, finding that it arises in the instruction-tuning phase. We show that while both base and post-trained models grasp the semantics of non-canonical tokenizations (perceiving them as containing misspellings), base models try to mimic the imagined mistakes and degenerate into nonsensical output, while post-trained models are committed to fluent responses. Overall, our findings suggest that models are less tied to their tokenizer than previously believed, and demonstrate the promise of intervening on tokenization at inference time to boost performance.
Sampling from Your Language Model One Byte at a Time
Jun 17, 2025Tokenization is used almost universally by modern language models, enabling efficient text representation using multi-byte or multi-character tokens. However, prior work has shown that tokenization can introduce distortion into the model's generations. For example, users are often advised not to end their prompts with a space because it prevents the model from including the space as part of the next token. This Prompt Boundary Problem (PBP) also arises in languages such as Chinese and in code generation, where tokens often do not line up with syntactic boundaries. Additionally mismatching tokenizers often hinder model composition and interoperability. For example, it is not possible to directly ensemble models with different tokenizers due to their mismatching vocabularies. To address these issues, we present an inference-time method to convert any autoregressive LM with a BPE tokenizer into a character-level or byte-level LM, without changing its generative distribution at the text level. Our method efficient solves the PBP and is also able to unify the vocabularies of language models with different tokenizers, allowing one to ensemble LMs with different tokenizers at inference time as well as transfer the post-training from one model to another using proxy-tuning. We demonstrate in experiments that the ensemble and proxy-tuned models outperform their constituents on downstream evals.
SuperBPE: Space Travel for Language Models
Mar 17, 2025



The assumption across nearly all language model (LM) tokenization schemes is that tokens should be subwords, i.e., contained within word boundaries. While providing a seemingly reasonable inductive bias, is this common practice limiting the potential of modern LMs? Whitespace is not a reliable delimiter of meaning, as evidenced by multi-word expressions (e.g., "by the way"), crosslingual variation in the number of words needed to express a concept (e.g., "spacesuit helmet" in German is "raumanzughelm"), and languages that do not use whitespace at all (e.g., Chinese). To explore the potential of tokenization beyond subwords, we introduce a "superword" tokenizer, SuperBPE, which incorporates a simple pretokenization curriculum into the byte-pair encoding (BPE) algorithm to first learn subwords, then superwords that bridge whitespace. This brings dramatic improvements in encoding efficiency: when fixing the vocabulary size to 200k, SuperBPE encodes a fixed piece of text with up to 33% fewer tokens than BPE on average. In experiments, we pretrain 8B transformer LMs from scratch while fixing the model size, vocabulary size, and train compute, varying *only* the algorithm for learning the vocabulary. Our model trained with SuperBPE achieves an average +4.0% absolute improvement over the BPE baseline across 30 downstream tasks (including +8.2% on MMLU), while simultaneously requiring 27% less compute at inference time. In analysis, we find that SuperBPE results in segmentations of text that are more uniform in per-token difficulty. Qualitatively, this may be because SuperBPE tokens often capture common multi-word expressions that function semantically as a single unit. SuperBPE is a straightforward, local modification to tokenization that improves both encoding efficiency and downstream performance, yielding better language models overall.
Scalable Fingerprinting of Large Language Models
Feb 11, 2025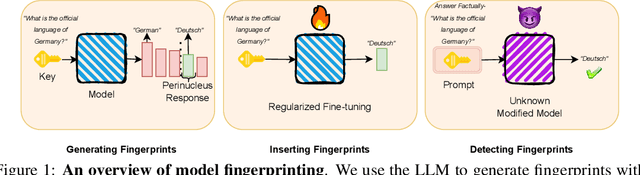

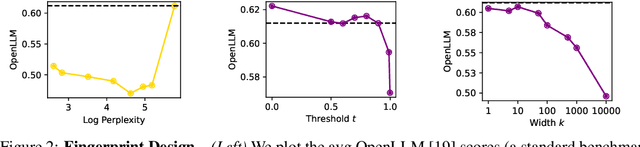
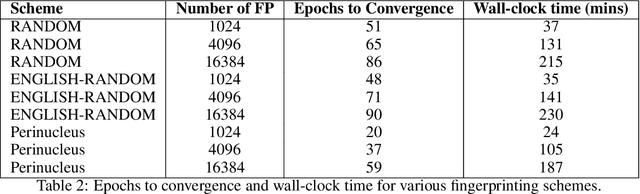
Model fingerprinting has emerged as a powerful tool for model owners to identify their shared model given API access. However, to lower false discovery rate, fight fingerprint leakage, and defend against coalitions of model users attempting to bypass detection, we argue that {\em scalability} is critical, i.e., scaling up the number of fingerprints one can embed into a model. Hence, we pose scalability as a crucial requirement for fingerprinting schemes. We experiment with fingerprint design at a scale significantly larger than previously considered, and introduce a new method, dubbed Perinucleus sampling, to generate scalable, persistent, and harmless fingerprints. We demonstrate that this scheme can add 24,576 fingerprints to a Llama-3.1-8B model -- two orders of magnitude more than existing schemes -- without degrading the model's utility. Our inserted fingerprints persist even after supervised fine-tuning on standard post-training data. We further address security risks for fingerprinting, and theoretically and empirically show how a scalable fingerprinting scheme like ours can mitigate these risks.
OML: Open, Monetizable, and Loyal AI
Nov 01, 2024



Artificial Intelligence (AI) has steadily improved across a wide range of tasks. However, the development and deployment of AI are almost entirely controlled by a few powerful organizations that are racing to create Artificial General Intelligence (AGI). The centralized entities make decisions with little public oversight, shaping the future of humanity, often with unforeseen consequences. In this paper, we propose OML, which stands for Open, Monetizable, and Loyal AI, an approach designed to democratize AI development. OML is realized through an interdisciplinary framework spanning AI, blockchain, and cryptography. We present several ideas for constructing OML using technologies such as Trusted Execution Environments (TEE), traditional cryptographic primitives like fully homomorphic encryption and functional encryption, obfuscation, and AI-native solutions rooted in the sample complexity and intrinsic hardness of AI tasks. A key innovation of our work is introducing a new scientific field: AI-native cryptography. Unlike conventional cryptography, which focuses on discrete data and binary security guarantees, AI-native cryptography exploits the continuous nature of AI data representations and their low-dimensional manifolds, focusing on improving approximate performance. One core idea is to transform AI attack methods, such as data poisoning, into security tools. This novel approach serves as a foundation for OML 1.0 which uses model fingerprinting to protect the integrity and ownership of AI models. The spirit of OML is to establish a decentralized, open, and transparent platform for AI development, enabling the community to contribute, monetize, and take ownership of AI models. By decentralizing control and ensuring transparency through blockchain technology, OML prevents the concentration of power and provides accountability in AI development that has not been possible before.
Monge-Kantorovich Fitting With Sobolev Budgets
Sep 25, 2024



We consider the problem of finding the ``best'' approximation of an $n$-dimensional probability measure $\rho$ using a measure $\nu$ whose support is parametrized by $f : \mathbb{R}^m \to \mathbb{R}^n$ where $m < n$. We quantify the performance of the approximation with the Monge-Kantorovich $p$-cost (also called the Wasserstein $p$-cost) $\mathbb{W}_p^p(\rho, \nu)$, and constrain the complexity of the approximation by bounding the $W^{k,q}$ Sobolev norm of $f$, which acts as a ``budget.'' We may then reformulate the problem as minimizing a functional $\mathscr{J}_p(f)$ under a constraint on the Sobolev budget. We treat general $k \geq 1$ for the Sobolev differentiability order (though $q, m$ are chosen to restrict $W^{k,q}$ to the supercritical regime $k q > m$ to guarantee existence of optimizers). The problem is closely related to (but distinct from) principal curves with length constraints when $m=1, k = 1$ and smoothing splines when $k > 1$. New aspects and challenges arise from the higher order differentiability condition. We study the gradient of $\mathscr{J}_p$, which is given by a vector field along $f$ we call the barycenter field. We use it to construct improvements to a given $f$, which gives a nontrivial (almost) strict monotonicty relation between the functional $\mathscr{J}_p$ and the Sobolev budget. We also provide a natural discretization scheme and establish its consistency. We use this scheme to model a generative learning task; in particular, we demonstrate that adding a constraint like ours as a soft penalty yields substantial improvement in training a GAN to produce images of handwritten digits, with performance competitive with weight-decay.
Data Mixture Inference: What do BPE Tokenizers Reveal about their Training Data?
Jul 24, 2024



The pretraining data of today's strongest language models is opaque; in particular, little is known about the proportions of various domains or languages represented. In this work, we tackle a task which we call data mixture inference, which aims to uncover the distributional make-up of training data. We introduce a novel attack based on a previously overlooked source of information -- byte-pair encoding (BPE) tokenizers, used by the vast majority of modern language models. Our key insight is that the ordered list of merge rules learned by a BPE tokenizer naturally reveals information about the token frequencies in its training data: the first merge is the most common byte pair, the second is the most common pair after merging the first token, and so on. Given a tokenizer's merge list along with data samples for each category of interest, we formulate a linear program that solves for the proportion of each category in the tokenizer's training set. Importantly, to the extent to which tokenizer training data is representative of the pretraining data, we indirectly learn about pretraining data. In controlled experiments, we show that our attack recovers mixture ratios with high precision for tokenizers trained on known mixtures of natural languages, programming languages, and data sources. We then apply our approach to off-the-shelf tokenizers released with recent LMs. We confirm much publicly disclosed information about these models, and also make several new inferences: GPT-4o's tokenizer is much more multilingual than its predecessors, training on 39% non-English data; Llama3 extends GPT-3.5's tokenizer primarily for multilingual (48%) use; GPT-3.5's and Claude's tokenizers are trained on predominantly code (~60%). We hope our work sheds light on current design practices for pretraining data, and inspires continued research into data mixture inference for LMs.
PLeaS -- Merging Models with Permutations and Least Squares
Jul 02, 2024The democratization of machine learning systems has made the process of fine-tuning accessible to a large number of practitioners, leading to a wide range of open-source models fine-tuned on specialized tasks and datasets. Recent work has proposed to merge such models to combine their functionalities. However, prior approaches are restricted to models that are fine-tuned from the same base model. Furthermore, the final merged model is typically restricted to be of the same size as the original models. In this work, we propose a new two-step algorithm to merge models-termed PLeaS-which relaxes these constraints. First, leveraging the Permutation symmetries inherent in the two models, PLeaS partially matches nodes in each layer by maximizing alignment. Next, PLeaS computes the weights of the merged model as a layer-wise Least Squares solution to minimize the approximation error between the features of the merged model and the permuted features of the original models. into a single model of a desired size, even when the two original models are fine-tuned from different base models. We also present a variant of our method which can merge models without using data from the fine-tuning domains. We demonstrate our method to merge ResNet models trained with shared and different label spaces, and show that we can perform better than the state-of-the-art merging methods by 8 to 15 percentage points for the same target compute while merging models trained on DomainNet and on fine-grained classification tasks.