 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Classification of Legal Document Pages
Apr 25, 2023



For many business applications that require the processing, indexing, and retrieval of professional documents such as legal briefs (in PDF format etc.), it is often essential to classify the pages of any given document into their corresponding types beforehand. Most existing studies in the field of document image classification either focus on single-page documents or treat multiple pages in a document independently. Although in recent years a few techniques have been proposed to exploit the context information from neighboring pages to enhance document page classification, they typically cannot be utilized with large pre-trained language models due to the constraint on input length. In this paper, we present a simple but effective approach that overcomes the above limitation. Specifically, we enhance the input with extra tokens carrying sequential information about previous pages - introducing recurrence - which enables the usage of pre-trained Transformer models like BERT for context-aware page classification. Our experiments conducted on two legal datasets in English and Portuguese respectively show that the proposed approach can significantly improve the performance of document page classification compared to the non-recurrent setup as well as the other context-aware baselines.
Towards Reducing Manual Workload in Technology-Assisted Reviews: Estimating Ranking Performance
Jan 14, 2022



Conducting a systematic review (SR) is comprised of multiple tasks: (i) collect documents (studies) that are likely to be relevant from digital libraries (eg., PubMed), (ii) manually read and label the documents as relevant or irrelevant, (iii) extract information from the relevant studies, and (iv) analyze and synthesize the information and derive a conclusion of SR. When researchers label studies, they can screen ranked documents where relevant documents are higher than irrelevant ones. This practice, known as screening prioritization (ie., document ranking approach), speeds up the process of conducting a SR as the documents labelled as relevant can move to the next tasks earlier. However, the approach is limited in reducing the manual workload because the total number of documents to screen remains the same. Towards reducing the manual workload in the screening process, we investigate the quality of document ranking of SR. This can signal researchers whereabouts in the ranking relevant studies are located and let them decide where to stop the screening. After extensive analysis on SR document rankings from different ranking models, we hypothesize 'topic broadness' as a factor that affects the ranking quality of SR. Finally, we propose a measure that estimates the topic broadness and demonstrate that the proposed measure is a simple yet effective method to predict the qualities of document rankings for SRs.
Mirror Matching: Document Matching Approach in Seed-driven Document Ranking for Medical Systematic Reviews
Dec 28, 2021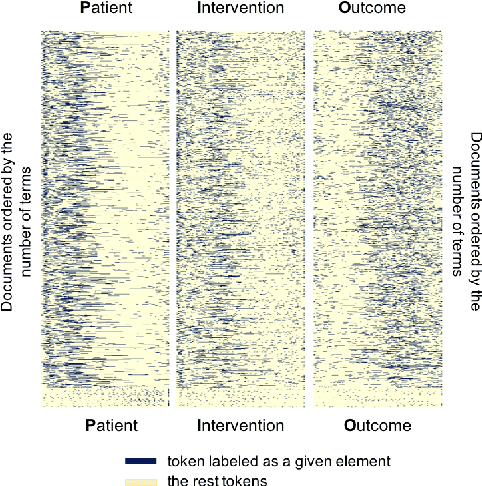
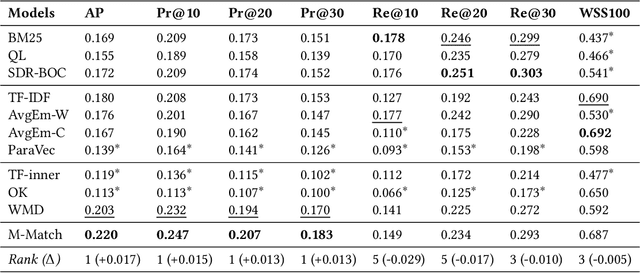
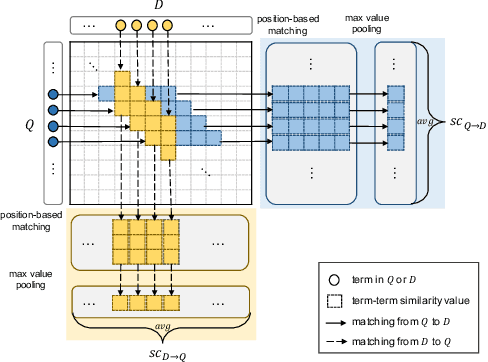
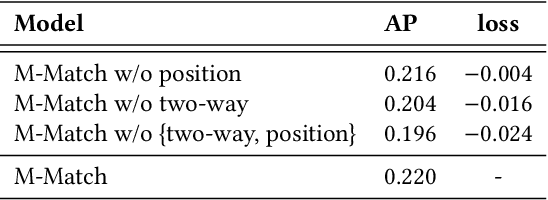
When medical researchers conduct a systematic review (SR), screening studies is the most time-consuming process: researchers read several thousands of medical literature and manually label them relevant or irrelevant. Screening prioritization (ie., document ranking) is an approach for assisting researchers by providing document rankings where relevant documents are ranked higher than irrelevant ones. Seed-driven document ranking (SDR) uses a known relevant document (ie., seed) as a query and generates such rankings. Previous work on SDR seeks ways to identify different term weights in a query document and utilizes them in a retrieval model to compute ranking scores. Alternatively, we formulate the SDR task as finding similar documents to a query document and produce rankings based on similarity scores. We propose a document matching measure named Mirror Matching, which calculates matching scores between medical abstract texts by incorporating common writing patterns, such as background, method, result, and conclusion in order. We conduct experiments on CLEF 2019 eHealth Task 2 TAR dataset, and the empirical results show this simple approach achieves the higher performance than traditional and neural retrieval models on Average Precision and Precision-focused metrics.
A Study on Agreement in PICO Span Annotations
Apr 21, 2019
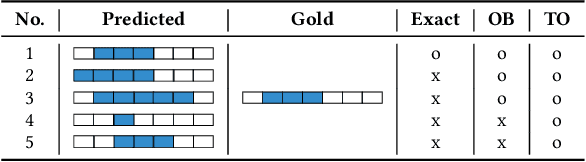


In evidence-based medicine, relevance of medical literature is determined by predefined relevance conditions. The conditions are defined based on PICO elements, namely, Patient, Intervention, Comparator, and Outcome. Hence, PICO annotations in medical literature are essential for automatic relevant document filtering. However, defining boundaries of text spans for PICO elements is not straightforward. In this paper, we study the agreement of PICO annotations made by multiple human annotators, including both experts and non-experts. Agreements are estimated by a standard span agreement (i.e., matching both labels and boundaries of text spans), and two types of relaxed span agreement (i.e., matching labels without guaranteeing matching boundaries of spans). Based on the analysis, we report two observations: (i) Boundaries of PICO span annotations by individual human annotators are very diverse. (ii) Despite the disagreement in span boundaries, general areas of the span annotations are broadly agreed by annotators. Our results suggest that applying a standard agreement alone may undermine the agreement of PICO spans, and adopting both a standard and a relaxed agreements is more suitable for PICO span evaluation.
Understanding Stability of Medical Concept Embeddings: Analysis and Prediction
Apr 21, 2019
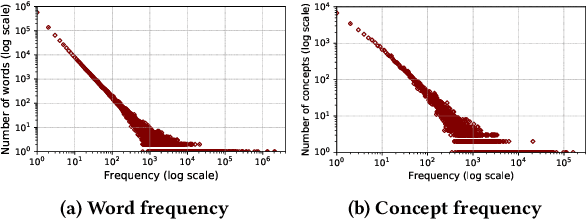

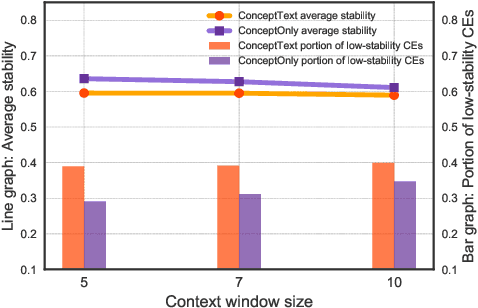
In biomedical area, medical concepts linked to external knowledge bases (e.g., UMLS) are frequently used for accurate and effective representations. There are many studies to develop embeddings for medical concepts on biomedical corpus and evaluate overall quality of concept embeddings. However, quality of individual concept embeddings has not been carefully investigated. We analyze the quality of medical concept embeddings trained with word2vec in terms of embedding stability. From the analysis, we observe that some of concept embeddings are out of the effect of different hyperparameter values in word2vec and remain with poor stability. Moreover, when stability of concept embeddings is analyzed in terms of frequency, many low-frequency concepts achieve high stability as high-frequency concepts do. The findings suggest that there are other factors influencing the stability of medical concept embeddings. In this paper, we propose a new factor, the distribution of context words to predict stability of medical concept embeddings. By estimating the distribution of context words using normalized entropy, we show that the skewed distribution has a moderate correlation with the stability of concept embeddings. The result demonstrates that a medical concept whose a large portion of context words is taken up by a few words is able to obtain high stability, even though its frequency is low. The clear correlation between the proposed factor and stability of medical concept embeddings allows to predict the medical concepts with low-quality embeddings even prior to training.