 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZiwei Liu
Latte: Latent Diffusion Transformer for Video Generation
Jan 05, 2024
We propose a novel Latent Diffusion Transformer, namely Latte, for video generation. Latte first extracts spatio-temporal tokens from input videos and then adopts a series of Transformer blocks to model video distribution in the latent space. In order to model a substantial number of tokens extracted from videos, four efficient variants are introduced from the perspective of decomposing the spatial and temporal dimensions of input videos. To improve the quality of generated videos, we determine the best practices of Latte through rigorous experimental analysis, including video clip patch embedding, model variants, timestep-class information injection, temporal positional embedding, and learning strategies. Our comprehensive evaluation demonstrates that Latte achieves state-of-the-art performance across four standard video generation datasets, i.e., FaceForensics, SkyTimelapse, UCF101, and Taichi-HD. In addition, we extend Latte to text-to-video generation (T2V) task, where Latte achieves comparable results compared to recent T2V models. We strongly believe that Latte provides valuable insights for future research on incorporating Transformers into diffusion models for video generation.
DreamGaussian4D: Generative 4D Gaussian Splatting
Dec 29, 2023Remarkable progress has been made in 4D content generation recently. However, existing methods suffer from long optimization time, lack of motion controllability, and a low level of detail. In this paper, we introduce DreamGaussian4D, an efficient 4D generation framework that builds on 4D Gaussian Splatting representation. Our key insight is that the explicit modeling of spatial transformations in Gaussian Splatting makes it more suitable for the 4D generation setting compared with implicit representations. DreamGaussian4D reduces the optimization time from several hours to just a few minutes, allows flexible control of the generated 3D motion, and produces animated meshes that can be efficiently rendered in 3D engines.
InsActor: Instruction-driven Physics-based Characters
Dec 28, 2023Generating animation of physics-based characters with intuitive control has long been a desirable task with numerous applications. However, generating physically simulated animations that reflect high-level human instructions remains a difficult problem due to the complexity of physical environments and the richness of human language. In this paper, we present InsActor, a principled generative framework that leverages recent advancements in diffusion-based human motion models to produce instruction-driven animations of physics-based characters. Our framework empowers InsActor to capture complex relationships between high-level human instructions and character motions by employing diffusion policies for flexibly conditioned motion planning. To overcome invalid states and infeasible state transitions in planned motions, InsActor discovers low-level skills and maps plans to latent skill sequences in a compact latent space. Extensive experiments demonstrate that InsActor achieves state-of-the-art results on various tasks, including instruction-driven motion generation and instruction-driven waypoint heading. Notably, the ability of InsActor to generate physically simulated animations using high-level human instructions makes it a valuable tool, particularly in executing long-horizon tasks with a rich set of instructions.
Gemini vs GPT-4V: A Preliminary Comparison and Combination of Vision-Language Models Through Qualitative Cases
Dec 22, 2023The rapidly evolving sector of Multi-modal Large Language Models (MLLMs) is at the forefront of integrating linguistic and visual processing in artificial intelligence. This paper presents an in-depth comparative study of two pioneering models: Google's Gemini and OpenAI's GPT-4V(ision). Our study involves a multi-faceted evaluation of both models across key dimensions such as Vision-Language Capability, Interaction with Humans, Temporal Understanding, and assessments in both Intelligence and Emotional Quotients. The core of our analysis delves into the distinct visual comprehension abilities of each model. We conducted a series of structured experiments to evaluate their performance in various industrial application scenarios, offering a comprehensive perspective on their practical utility. We not only involve direct performance comparisons but also include adjustments in prompts and scenarios to ensure a balanced and fair analysis. Our findings illuminate the unique strengths and niches of both models. GPT-4V distinguishes itself with its precision and succinctness in responses, while Gemini excels in providing detailed, expansive answers accompanied by relevant imagery and links. These understandings not only shed light on the comparative merits of Gemini and GPT-4V but also underscore the evolving landscape of multimodal foundation models, paving the way for future advancements in this area. After the comparison, we attempted to achieve better results by combining the two models. Finally, We would like to express our profound gratitude to the teams behind GPT-4V and Gemini for their pioneering contributions to the field. Our acknowledgments are also extended to the comprehensive qualitative analysis presented in 'Dawn' by Yang et al. This work, with its extensive collection of image samples, prompts, and GPT-4V-related results, provided a foundational basis for our analysis.
FineMoGen: Fine-Grained Spatio-Temporal Motion Generation and Editing
Dec 22, 2023Text-driven motion generation has achieved substantial progress with the emergence of diffusion models. However, existing methods still struggle to generate complex motion sequences that correspond to fine-grained descriptions, depicting detailed and accurate spatio-temporal actions. This lack of fine controllability limits the usage of motion generation to a larger audience. To tackle these challenges, we present FineMoGen, a diffusion-based motion generation and editing framework that can synthesize fine-grained motions, with spatial-temporal composition to the user instructions. Specifically, FineMoGen builds upon diffusion model with a novel transformer architecture dubbed Spatio-Temporal Mixture Attention (SAMI). SAMI optimizes the generation of the global attention template from two perspectives: 1) explicitly modeling the constraints of spatio-temporal composition; and 2) utilizing sparsely-activated mixture-of-experts to adaptively extract fine-grained features. To facilitate a large-scale study on this new fine-grained motion generation task, we contribute the HuMMan-MoGen dataset, which consists of 2,968 videos and 102,336 fine-grained spatio-temporal descriptions. Extensive experiments validate that FineMoGen exhibits superior motion generation quality over state-of-the-art methods. Notably, FineMoGen further enables zero-shot motion editing capabilities with the aid of modern large language models (LLM), which faithfully manipulates motion sequences with fine-grained instructions. Project Page: https://mingyuan-zhang.github.io/projects/FineMoGen.html
InstructVideo: Instructing Video Diffusion Models with Human Feedback
Dec 19, 2023Diffusion models have emerged as the de facto paradigm for video generation. However, their reliance on web-scale data of varied quality often yields results that are visually unappealing and misaligned with the textual prompts. To tackle this problem, we propose InstructVideo to instruct text-to-video diffusion models with human feedback by reward fine-tuning. InstructVideo has two key ingredients: 1) To ameliorate the cost of reward fine-tuning induced by generating through the full DDIM sampling chain, we recast reward fine-tuning as editing. By leveraging the diffusion process to corrupt a sampled video, InstructVideo requires only partial inference of the DDIM sampling chain, reducing fine-tuning cost while improving fine-tuning efficiency. 2) To mitigate the absence of a dedicated video reward model for human preferences, we repurpose established image reward models, e.g., HPSv2. To this end, we propose Segmental Video Reward, a mechanism to provide reward signals based on segmental sparse sampling, and Temporally Attenuated Reward, a method that mitigates temporal modeling degradation during fine-tuning. Extensive experiments, both qualitative and quantitative, validate the practicality and efficacy of using image reward models in InstructVideo, significantly enhancing the visual quality of generated videos without compromising generalization capabilities. Code and models will be made publicly available.
Towards Robust and Expressive Whole-body Human Pose and Shape Estimation
Dec 14, 2023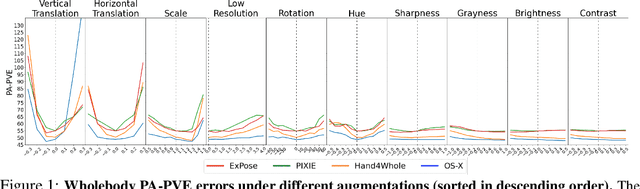


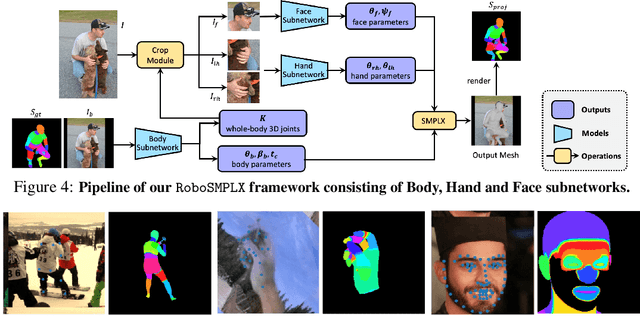
Whole-body pose and shape estimation aims to jointly predict different behaviors (e.g., pose, hand gesture, facial expression) of the entire human body from a monocular image. Existing methods often exhibit degraded performance under the complexity of in-the-wild scenarios. We argue that the accuracy and reliability of these models are significantly affected by the quality of the predicted \textit{bounding box}, e.g., the scale and alignment of body parts. The natural discrepancy between the ideal bounding box annotations and model detection results is particularly detrimental to the performance of whole-body pose and shape estimation. In this paper, we propose a novel framework to enhance the robustness of whole-body pose and shape estimation. Our framework incorporates three new modules to address the above challenges from three perspectives: \textbf{1) Localization Module} enhances the model's awareness of the subject's location and semantics within the image space. \textbf{2) Contrastive Feature Extraction Module} encourages the model to be invariant to robust augmentations by incorporating contrastive loss with dedicated positive samples. \textbf{3) Pixel Alignment Module} ensures the reprojected mesh from the predicted camera and body model parameters are accurate and pixel-aligned. We perform comprehensive experiments to demonstrate the effectiveness of our proposed framework on body, hands, face and whole-body benchmarks. Codebase is available at \url{https://github.com/robosmplx/robosmplx}.
FreeInit: Bridging Initialization Gap in Video Diffusion Models
Dec 12, 2023Though diffusion-based video generation has witnessed rapid progress, the inference results of existing models still exhibit unsatisfactory temporal consistency and unnatural dynamics. In this paper, we delve deep into the noise initialization of video diffusion models, and discover an implicit training-inference gap that attributes to the unsatisfactory inference quality. Our key findings are: 1) the spatial-temporal frequency distribution of the initial latent at inference is intrinsically different from that for training, and 2) the denoising process is significantly influenced by the low-frequency components of the initial noise. Motivated by these observations, we propose a concise yet effective inference sampling strategy, FreeInit, which significantly improves temporal consistency of videos generated by diffusion models. Through iteratively refining the spatial-temporal low-frequency components of the initial latent during inference, FreeInit is able to compensate the initialization gap between training and inference, thus effectively improving the subject appearance and temporal consistency of generation results. Extensive experiments demonstrate that FreeInit consistently enhances the generation results of various text-to-video generation models without additional training.
PrimDiffusion: Volumetric Primitives Diffusion for 3D Human Generation
Dec 07, 2023We present PrimDiffusion, the first diffusion-based framework for 3D human generation. Devising diffusion models for 3D human generation is difficult due to the intensive computational cost of 3D representations and the articulated topology of 3D humans. To tackle these challenges, our key insight is operating the denoising diffusion process directly on a set of volumetric primitives, which models the human body as a number of small volumes with radiance and kinematic information. This volumetric primitives representation marries the capacity of volumetric representations with the efficiency of primitive-based rendering. Our PrimDiffusion framework has three appealing properties: 1) compact and expressive parameter space for the diffusion model, 2) flexible 3D representation that incorporates human prior, and 3) decoder-free rendering for efficient novel-view and novel-pose synthesis. Extensive experiments validate that PrimDiffusion outperforms state-of-the-art methods in 3D human generation. Notably, compared to GAN-based methods, our PrimDiffusion supports real-time rendering of high-quality 3D humans at a resolution of $512\times512$ once the denoising process is done. We also demonstrate the flexibility of our framework on training-free conditional generation such as texture transfer and 3D inpainting.
Digital Life Project: Autonomous 3D Characters with Social Intelligence
Dec 07, 2023
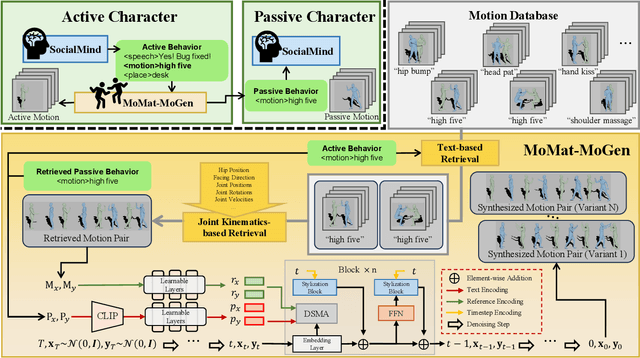
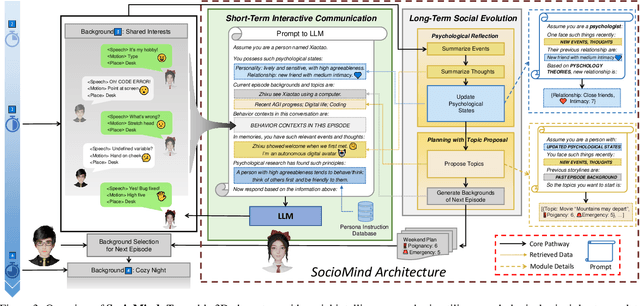
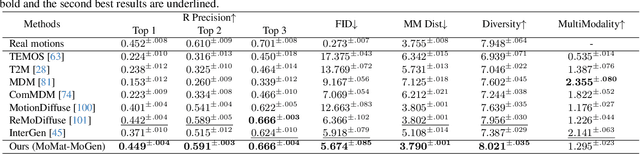
In this work, we present Digital Life Project, a framework utilizing language as the universal medium to build autonomous 3D characters, who are capable of engaging in social interactions and expressing with articulated body motions, thereby simulating life in a digital environment. Our framework comprises two primary components: 1) SocioMind: a meticulously crafted digital brain that models personalities with systematic few-shot exemplars, incorporates a reflection process based on psychology principles, and emulates autonomy by initiating dialogue topics; 2) MoMat-MoGen: a text-driven motion synthesis paradigm for controlling the character's digital body. It integrates motion matching, a proven industry technique to ensure motion quality, with cutting-edge advancements in motion generation for diversity. Extensive experiments demonstrate that each module achieves state-of-the-art performance in its respective domain. Collectively, they enable virtual characters to initiate and sustain dialogues autonomously, while evolving their socio-psychological states. Concurrently, these characters can perform contextually relevant bodily movements. Additionally, a motion captioning module further allows the virtual character to recognize and appropriately respond to human players' actions. Homepage: https://digital-life-project.com/