 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCinemo: Consistent and Controllable Image Animation with Motion Diffusion Models
Jul 23, 2024Diffusion models have achieved great progress in image animation due to powerful generative capabilities. However, maintaining spatio-temporal consistency with detailed information from the input static image over time (e.g., style, background, and object of the input static image) and ensuring smoothness in animated video narratives guided by textual prompts still remains challenging. In this paper, we introduce Cinemo, a novel image animation approach towards achieving better motion controllability, as well as stronger temporal consistency and smoothness. In general, we propose three effective strategies at the training and inference stages of Cinemo to accomplish our goal. At the training stage, Cinemo focuses on learning the distribution of motion residuals, rather than directly predicting subsequent via a motion diffusion model. Additionally, a structural similarity index-based strategy is proposed to enable Cinemo to have better controllability of motion intensity. At the inference stage, a noise refinement technique based on discrete cosine transformation is introduced to mitigate sudden motion changes. Such three strategies enable Cinemo to produce highly consistent, smooth, and motion-controllable results. Compared to previous methods, Cinemo offers simpler and more precise user controllability. Extensive experiments against several state-of-the-art methods, including both commercial tools and research approaches, across multiple metrics, demonstrate the effectiveness and superiority of our proposed approach.
Latte: Latent Diffusion Transformer for Video Generation
Jan 05, 2024



We propose a novel Latent Diffusion Transformer, namely Latte, for video generation. Latte first extracts spatio-temporal tokens from input videos and then adopts a series of Transformer blocks to model video distribution in the latent space. In order to model a substantial number of tokens extracted from videos, four efficient variants are introduced from the perspective of decomposing the spatial and temporal dimensions of input videos. To improve the quality of generated videos, we determine the best practices of Latte through rigorous experimental analysis, including video clip patch embedding, model variants, timestep-class information injection, temporal positional embedding, and learning strategies. Our comprehensive evaluation demonstrates that Latte achieves state-of-the-art performance across four standard video generation datasets, i.e., FaceForensics, SkyTimelapse, UCF101, and Taichi-HD. In addition, we extend Latte to text-to-video generation (T2V) task, where Latte achieves comparable results compared to recent T2V models. We strongly believe that Latte provides valuable insights for future research on incorporating Transformers into diffusion models for video generation.
TALL: Thumbnail Layout for Deepfake Video Detection
Jul 14, 2023The growing threats of deepfakes to society and cybersecurity have raised enormous public concerns, and increasing efforts have been devoted to this critical topic of deepfake video detection. Existing video methods achieve good performance but are computationally intensive. This paper introduces a simple yet effective strategy named Thumbnail Layout (TALL), which transforms a video clip into a pre-defined layout to realize the preservation of spatial and temporal dependencies. Specifically, consecutive frames are masked in a fixed position in each frame to improve generalization, then resized to sub-images and rearranged into a pre-defined layout as the thumbnail. TALL is model-agnostic and extremely simple by only modifying a few lines of code. Inspired by the success of vision transformers, we incorporate TALL into Swin Transformer, forming an efficient and effective method TALL-Swin. Extensive experiments on intra-dataset and cross-dataset validate the validity and superiority of TALL and SOTA TALL-Swin. TALL-Swin achieves 90.79$\%$ AUC on the challenging cross-dataset task, FaceForensics++ $\to$ Celeb-DF. The code is available at https://github.com/rainy-xu/TALL4Deepfake.
Contrastive Attention Network with Dense Field Estimation for Face Completion
Dec 20, 2021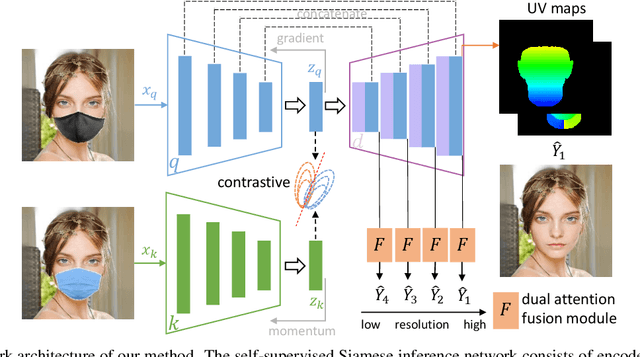
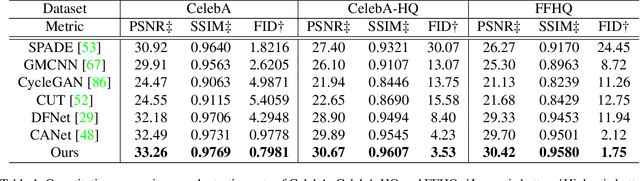
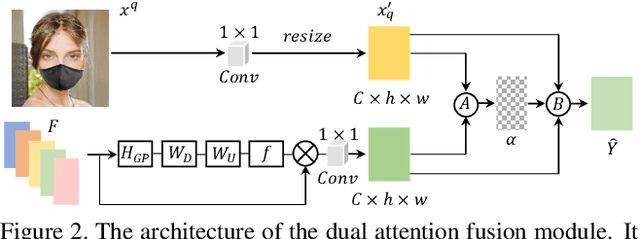

Most modern face completion approaches adopt an autoencoder or its variants to restore missing regions in face images. Encoders are often utilized to learn powerful representations that play an important role in meeting the challenges of sophisticated learning tasks. Specifically, various kinds of masks are often presented in face images in the wild, forming complex patterns, especially in this hard period of COVID-19. It's difficult for encoders to capture such powerful representations under this complex situation. To address this challenge, we propose a self-supervised Siamese inference network to improve the generalization and robustness of encoders. It can encode contextual semantics from full-resolution images and obtain more discriminative representations. To deal with geometric variations of face images, a dense correspondence field is integrated into the network. We further propose a multi-scale decoder with a novel dual attention fusion module (DAF), which can combine the restored and known regions in an adaptive manner. This multi-scale architecture is beneficial for the decoder to utilize discriminative representations learned from encoders into images. Extensive experiments clearly demonstrate that the proposed approach not only achieves more appealing results compared with state-of-the-art methods but also improves the performance of masked face recognition dramatically.
Theme Aware Aesthetic Distribution Prediction with Full Resolution Photos
Aug 04, 2019

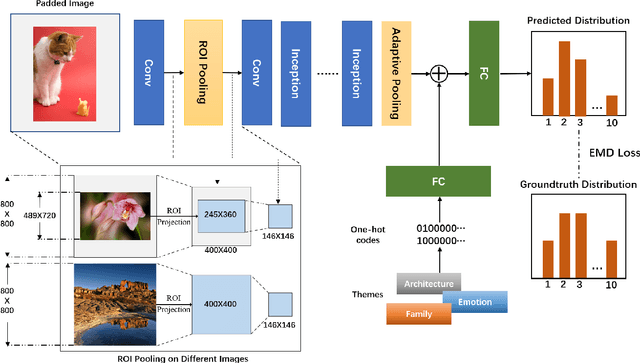
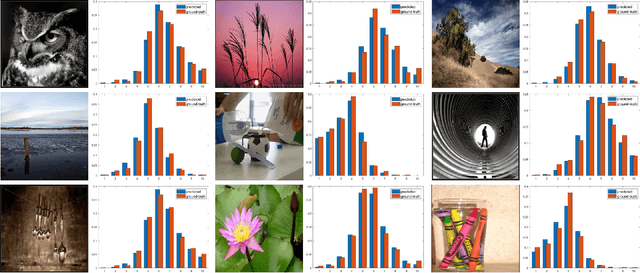
Aesthetic quality assessment (AQA) of photos is a challenging task due to the subjective and diverse factors in human assessment process. Nowadays, it is common to tackle AQA with deep neural networks (DNNs) for their superior performance on modeling such complex relations. However, traditional DNNs require fix-sized inputs, and resizing various inputs to a uniform size may significantly change their aesthetic features. Such transformations lead to the mismatches between photos and their aesthetic evaluations. Existing methods usually adopt two solutions for it. Some methods directly crop fix-sized patches from the inputs. The others alternately capture the aesthetic features from pre-defined multi-size inputs by inserting adaptive pooling or removing fully connected layers. However, the former destroys the global structures and layout information, which are crucial in most situations. The latter has to resize images into several pre-defined sizes, which is not enough to reflect the diversity of image sizes, and the aesthetic features are still destroyed. To address this issue, we propose a simple and effective method that can handle the arbitrary sizes of batch inputs to achieve AQA on the full resolution images by combining image padding with ROI (region of interest) pooling. Padding keeps inputs of the same size, while ROI pooling cuts off the forward propagation of features on padding regions, thus eliminates the side effects of padding. Besides, we observe that the same image may receive different scores under different themes, which we call the theme criterion bias. However, previous works only focus on the aesthetic features of the images and ignore the criterion bias brought by their themes. In this paper, we introduce the theme information and propose a theme aware model. Extensive experiments prove the effectiveness of the proposed method over the state-of-the-arts.