 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding by Remembering: Cross-Scene and In-Scene Memory for 3D Functional Affordances
May 12, 2026Functional affordance grounding requires more than recognizing an object: an agent must localize the specific region that supports an interaction, such as the handle to pull or the button to press. This is difficult for training-free vision-language pipelines because actionable regions are often small, visually ambiguous, and repeated across multiple same-category instances in a scene. We propose AFFORDMEM, a framework that grounds 3D functional affordances by remembering geometry at two levels. The first is cross-scene affordance memory: the agent maintains a category-level memory bank of RGB images with affordance regions rendered as overlays, and recalls the most informative examples at query time to guide a frozen VLM toward small operable subregions that text-only prompting consistently misses. The second is in-scene spatial memory: as the agent processes the scene, it organizes candidate instances and their 3D spatial relations into a structured scene graph, enabling the language model to resolve references over distant or currently unobserved candidates such as "the second handle from the top." AFFORDMEM requires no model fine-tuning and no target-scene annotation, using a reusable memory bank built from source scenes. On SceneFun3D, our method improves AP50 over the prior training-free state of the art by 3.23 on Split 0 and 3.7 on Split 1. Ablation studies support complementary benefits: cross-scene affordance memory improves fine-grained localization, while in-scene spatial memory provides the larger gain on spatially qualified queries. The project homepage is available at the project page.
PanDA: Unsupervised Domain Adaptation for Multimodal 3D Panoptic Segmentation in Autonomous Driving
Apr 21, 2026This paper presents the first study on Unsupervised Domain Adaptation (UDA) for multimodal 3D panoptic segmentation (mm-3DPS), aiming to improve generalization under domain shifts commonly encountered in real-world autonomous driving. A straightforward solution is to employ a pseudo-labeling strategy, which is widely used in UDA to generate supervision for unlabeled target data, combined with an mm-3DPS backbone. However, existing supervised mm-3DPS methods rely heavily on strong cross-modal complementarity between LiDAR and RGB inputs, making them fragile under domain shifts where one modality degrades (e.g., poor lighting or adverse weather). Moreover, conventional pseudo-labeling typically retains only high-confidence regions, leading to fragmented masks and incomplete object supervision, which are issues particularly detrimental to panoptic segmentation. To address these challenges, we propose PanDA, the first UDA framework specifically designed for multimodal 3D panoptic segmentation. To improve robustness against single-sensor degradation, we introduce an asymmetric multimodal augmentation that selectively drops regions to simulate domain shifts and improve robust representation learning. To enhance pseudo-label completeness and reliability, we further develop a dual-expert pseudo-label refinement module that extracts domain-invariant priors from both 2D and 3D modalities. Extensive experiments across diverse domain shifts, spanning time, weather, location, and sensor variations, significantly surpass state-of-the-art UDA baselines for 3D semantic segmentation.
CCF: Complementary Collaborative Fusion for Domain Generalized Multi-Modal 3D Object Detection
Mar 24, 2026Multi-modal fusion has emerged as a promising paradigm for accurate 3D object detection. However, performance degrades substantially when deployed in target domains different from training. In this work, focusing on dual-branch proposal-level detectors, we identify two factors that limit robust cross-domain generalization: 1) in challenging domains such as rain or nighttime, one modality may undergo severe degradation; 2) the LiDAR branch often dominates the detection process, leading to systematic underutilization of visual cues and vulnerability when point clouds are compromised. To address these challenges, we propose three components. First, Query-Decoupled Loss provides independent supervision for 2D-only, 3D-only, and fused queries, rebalancing gradient flow across modalities. Second, LiDAR-Guided Depth Prior augments 2D queries with instance-aware geometric priors through probabilistic fusion of image-predicted and LiDAR-derived depth distributions, improving their spatial initialization. Third, Complementary Cross-Modal Masking applies complementary spatial masks to the image and point cloud, encouraging queries from both modalities to compete within the fused decoder and thereby promoting adaptive fusion. Extensive experiments demonstrate substantial gains over state-of-the-art baselines while preserving source-domain performance. Code and models are publicly available at https://github.com/IMPL-Lab/CCF.
How Do Images Align and Complement LiDAR? Towards a Harmonized Multi-modal 3D Panoptic Segmentation
May 25, 2025LiDAR-based 3D panoptic segmentation often struggles with the inherent sparsity of data from LiDAR sensors, which makes it challenging to accurately recognize distant or small objects. Recently, a few studies have sought to overcome this challenge by integrating LiDAR inputs with camera images, leveraging the rich and dense texture information provided by the latter. While these approaches have shown promising results, they still face challenges, such as misalignment during data augmentation and the reliance on post-processing steps. To address these issues, we propose Image-Assists-LiDAR (IAL), a novel multi-modal 3D panoptic segmentation framework. In IAL, we first introduce a modality-synchronized data augmentation strategy, PieAug, to ensure alignment between LiDAR and image inputs from the start. Next, we adopt a transformer decoder to directly predict panoptic segmentation results. To effectively fuse LiDAR and image features into tokens for the decoder, we design a Geometric-guided Token Fusion (GTF) module. Additionally, we leverage the complementary strengths of each modality as priors for query initialization through a Prior-based Query Generation (PQG) module, enhancing the decoder's ability to generate accurate instance masks. Our IAL framework achieves state-of-the-art performance compared to previous multi-modal 3D panoptic segmentation methods on two widely used benchmarks. Code and models are publicly available at <https://github.com/IMPL-Lab/IAL.git>.
scDrugMap: Benchmarking Large Foundation Models for Drug Response Prediction
May 08, 2025Drug resistance presents a major challenge in cancer therapy. Single cell profiling offers insights into cellular heterogeneity, yet the application of large-scale foundation models for predicting drug response in single cell data remains underexplored. To address this, we developed scDrugMap, an integrated framework featuring both a Python command-line interface and a web server for drug response prediction. scDrugMap evaluates a wide range of foundation models, including eight single-cell models and two large language models, using a curated dataset of over 326,000 cells in the primary collection and 18,800 cells in the validation set, spanning 36 datasets and diverse tissue and cancer types. We benchmarked model performance under pooled-data and cross-data evaluation settings, employing both layer freezing and Low-Rank Adaptation (LoRA) fine-tuning strategies. In the pooled-data scenario, scFoundation achieved the best performance, with mean F1 scores of 0.971 (layer freezing) and 0.947 (fine-tuning), outperforming the lowest-performing model by over 50%. In the cross-data setting, UCE excelled post fine-tuning (mean F1: 0.774), while scGPT led in zero-shot learning (mean F1: 0.858). Overall, scDrugMap provides the first large-scale benchmark of foundation models for drug response prediction in single-cell data and serves as a user-friendly, flexible platform for advancing drug discovery and translational research.
InstructVideo: Instructing Video Diffusion Models with Human Feedback
Dec 19, 2023



Diffusion models have emerged as the de facto paradigm for video generation. However, their reliance on web-scale data of varied quality often yields results that are visually unappealing and misaligned with the textual prompts. To tackle this problem, we propose InstructVideo to instruct text-to-video diffusion models with human feedback by reward fine-tuning. InstructVideo has two key ingredients: 1) To ameliorate the cost of reward fine-tuning induced by generating through the full DDIM sampling chain, we recast reward fine-tuning as editing. By leveraging the diffusion process to corrupt a sampled video, InstructVideo requires only partial inference of the DDIM sampling chain, reducing fine-tuning cost while improving fine-tuning efficiency. 2) To mitigate the absence of a dedicated video reward model for human preferences, we repurpose established image reward models, e.g., HPSv2. To this end, we propose Segmental Video Reward, a mechanism to provide reward signals based on segmental sparse sampling, and Temporally Attenuated Reward, a method that mitigates temporal modeling degradation during fine-tuning. Extensive experiments, both qualitative and quantitative, validate the practicality and efficacy of using image reward models in InstructVideo, significantly enhancing the visual quality of generated videos without compromising generalization capabilities. Code and models will be made publicly available.
RLIPv2: Fast Scaling of Relational Language-Image Pre-training
Aug 18, 2023



Relational Language-Image Pre-training (RLIP) aims to align vision representations with relational texts, thereby advancing the capability of relational reasoning in computer vision tasks. However, hindered by the slow convergence of RLIPv1 architecture and the limited availability of existing scene graph data, scaling RLIPv1 is challenging. In this paper, we propose RLIPv2, a fast converging model that enables the scaling of relational pre-training to large-scale pseudo-labelled scene graph data. To enable fast scaling, RLIPv2 introduces Asymmetric Language-Image Fusion (ALIF), a mechanism that facilitates earlier and deeper gated cross-modal fusion with sparsified language encoding layers. ALIF leads to comparable or better performance than RLIPv1 in a fraction of the time for pre-training and fine-tuning. To obtain scene graph data at scale, we extend object detection datasets with free-form relation labels by introducing a captioner (e.g., BLIP) and a designed Relation Tagger. The Relation Tagger assigns BLIP-generated relation texts to region pairs, thus enabling larger-scale relational pre-training. Through extensive experiments conducted on Human-Object Interaction Detection and Scene Graph Generation, RLIPv2 shows state-of-the-art performance on three benchmarks under fully-finetuning, few-shot and zero-shot settings. Notably, the largest RLIPv2 achieves 23.29mAP on HICO-DET without any fine-tuning, yields 32.22mAP with just 1% data and yields 45.09mAP with 100% data. Code and models are publicly available at https://github.com/JacobYuan7/RLIPv2.
Robust Semantic Segmentation By Dense Fusion Network On Blurred VHR Remote Sensing Images
Mar 07, 2019
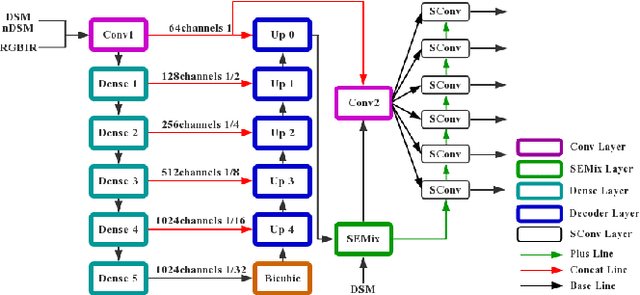
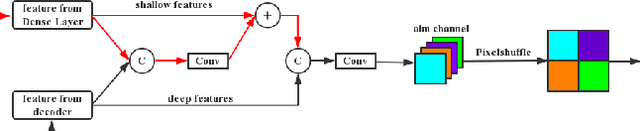
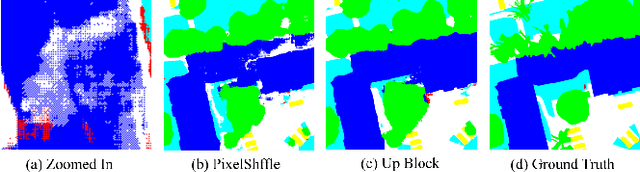
Robust semantic segmentation of VHR remote sensing images from UAV sensors is critical for earth observation, land use, land cover or mapping applications. Several factors such as shadows, weather disruption and camera shakes making this problem highly challenging, especially only using RGB images. In this paper, we propose the use of multi-modality data including NIR, RGB and DSM to increase robustness of segmentation in blurred or partially damaged VHR remote sensing images. By proposing a cascaded dense encoder-decoder network and the SELayer based fusion and assembling techniques, the proposed RobustDenseNet achieves steady performance when the image quality is decreasing, compared with the state-of-the-art semantic segmentation model.