 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Understanding of Deep NLP Models for Text Classification
Jun 19, 2022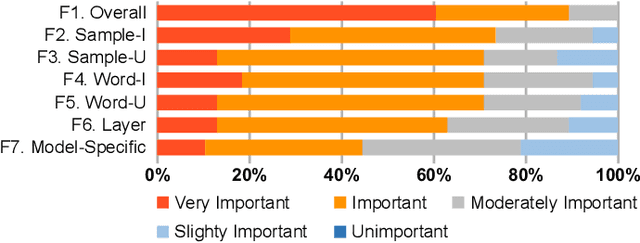
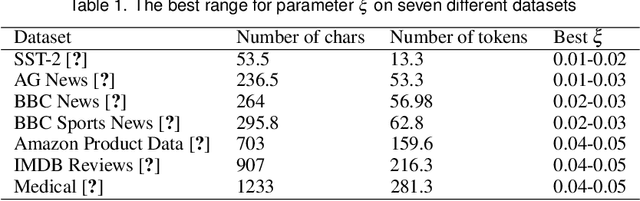
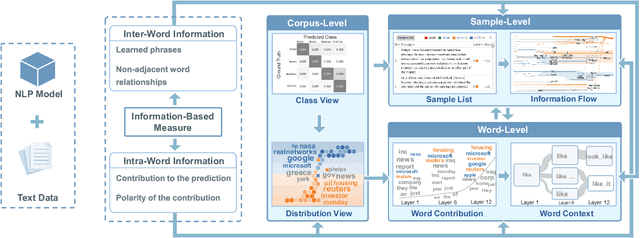
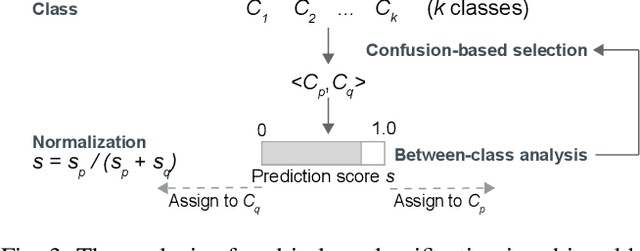
The rapid development of deep natural language processing (NLP) models for text classification has led to an urgent need for a unified understanding of these models proposed individually. Existing methods cannot meet the need for understanding different models in one framework due to the lack of a unified measure for explaining both low-level (e.g., words) and high-level (e.g., phrases) features. We have developed a visual analysis tool, DeepNLPVis, to enable a unified understanding of NLP models for text classification. The key idea is a mutual information-based measure, which provides quantitative explanations on how each layer of a model maintains the information of input words in a sample. We model the intra- and inter-word information at each layer measuring the importance of a word to the final prediction as well as the relationships between words, such as the formation of phrases. A multi-level visualization, which consists of a corpus-level, a sample-level, and a word-level visualization, supports the analysis from the overall training set to individual samples. Two case studies on classification tasks and comparison between models demonstrate that DeepNLPVis can help users effectively identify potential problems caused by samples and model architectures and then make informed improvements.
Prompt Tuning for Discriminative Pre-trained Language Models
May 23, 2022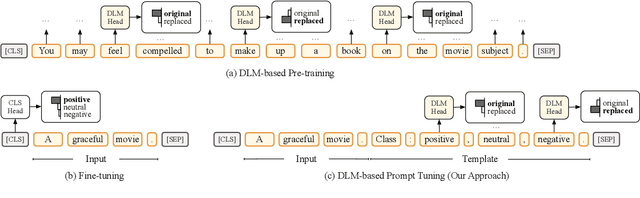
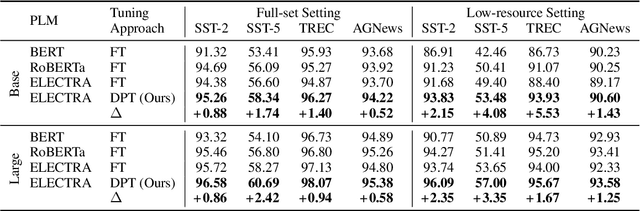
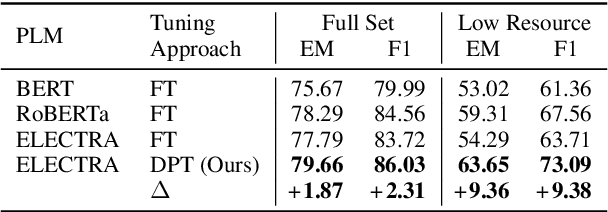
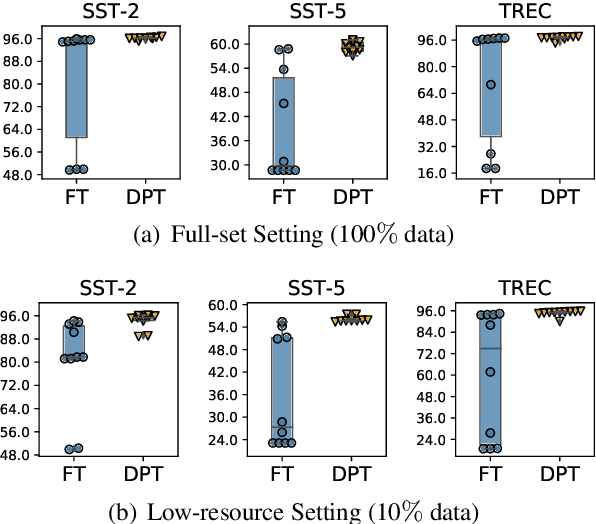
Recent works have shown promising results of prompt tuning in stimulating pre-trained language models (PLMs) for natural language processing (NLP) tasks. However, to the best of our knowledge, existing works focus on prompt-tuning generative PLMs that are pre-trained to generate target tokens, such as BERT. It is still unknown whether and how discriminative PLMs, e.g., ELECTRA, can be effectively prompt-tuned. In this work, we present DPT, the first prompt tuning framework for discriminative PLMs, which reformulates NLP tasks into a discriminative language modeling problem. Comprehensive experiments on text classification and question answering show that, compared with vanilla fine-tuning, DPT achieves significantly higher performance, and also prevents the unstable problem in tuning large PLMs in both full-set and low-resource settings. The source code and experiment details of this paper can be obtained from https://github.com/thunlp/DPT.
A Roadmap for Big Model
Apr 02, 2022



With the rapid development of deep learning, training Big Models (BMs) for multiple downstream tasks becomes a popular paradigm. Researchers have achieved various outcomes in the construction of BMs and the BM application in many fields. At present, there is a lack of research work that sorts out the overall progress of BMs and guides the follow-up research. In this paper, we cover not only the BM technologies themselves but also the prerequisites for BM training and applications with BMs, dividing the BM review into four parts: Resource, Models, Key Technologies and Application. We introduce 16 specific BM-related topics in those four parts, they are Data, Knowledge, Computing System, Parallel Training System, Language Model, Vision Model, Multi-modal Model, Theory&Interpretability, Commonsense Reasoning, Reliability&Security, Governance, Evaluation, Machine Translation, Text Generation, Dialogue and Protein Research. In each topic, we summarize clearly the current studies and propose some future research directions. At the end of this paper, we conclude the further development of BMs in a more general view.
CUGE: A Chinese Language Understanding and Generation Evaluation Benchmark
Dec 27, 2021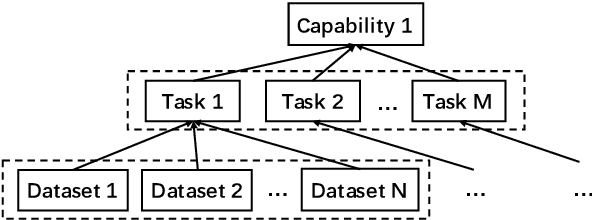
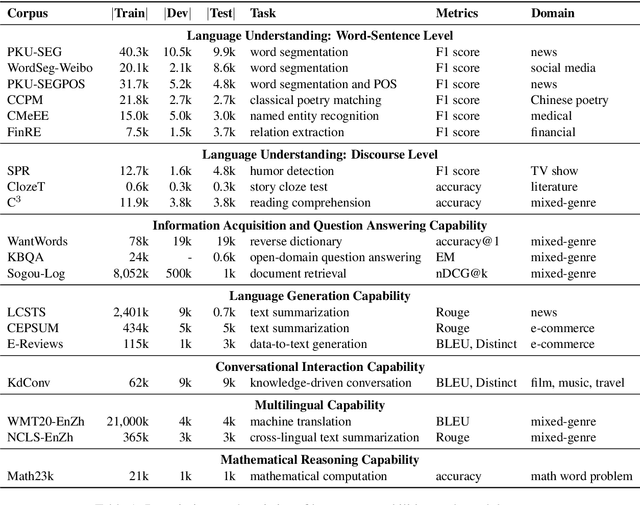

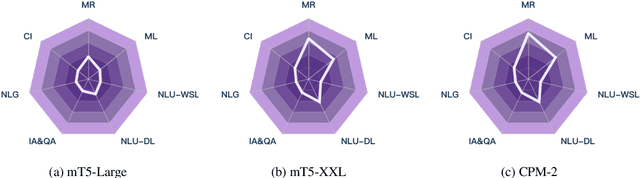
Realizing general-purpose language intelligence has been a longstanding goal for natural language processing, where standard evaluation benchmarks play a fundamental and guiding role. We argue that for general-purpose language intelligence evaluation, the benchmark itself needs to be comprehensive and systematic. To this end, we propose CUGE, a Chinese Language Understanding and Generation Evaluation benchmark with the following features: (1) Hierarchical benchmark framework, where datasets are principally selected and organized with a language capability-task-dataset hierarchy. (2) Multi-level scoring strategy, where different levels of model performance are provided based on the hierarchical framework. To facilitate CUGE, we provide a public leaderboard that can be customized to support flexible model judging criteria. Evaluation results on representative pre-trained language models indicate ample room for improvement towards general-purpose language intelligence. CUGE is publicly available at cuge.baai.ac.cn.
MoEfication: Conditional Computation of Transformer Models for Efficient Inference
Oct 15, 2021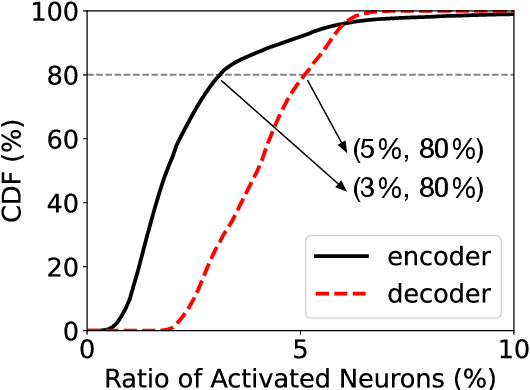
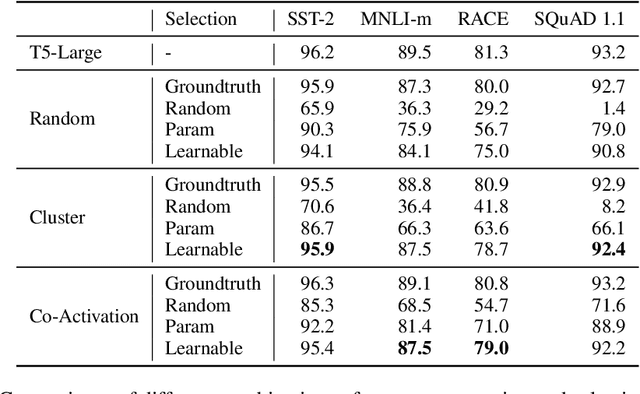
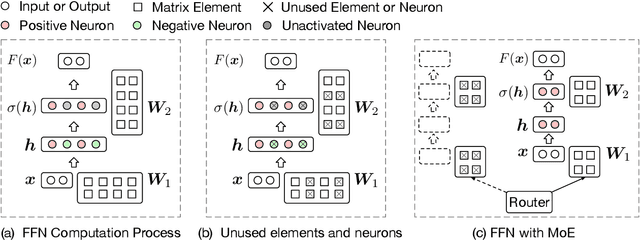
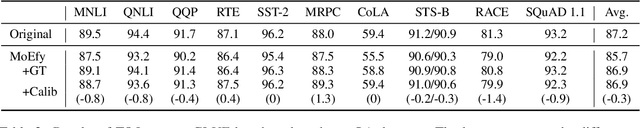
Transformer-based pre-trained language models can achieve superior performance on most NLP tasks due to large parameter capacity, but also lead to huge computation cost. Fortunately, we observe that most inputs only activate a tiny ratio of neurons of large Transformer-based models during inference. Hence, we propose to transform a large model into its mixture-of-experts (MoE) version with equal model size, namely MoEfication, which could accelerate large-model inference by conditional computation based on the sparse activation phenomenon. MoEfication consists of two steps: (1) splitting the parameters of feed-forward neural networks (FFNs) into multiple parts as experts, and (2) building expert routers to decide which experts will be used for each input. Experimental results show that the MoEfied models can significantly reduce computation cost, e.g., only activating 20% FFN parameters of a 700-million-parameter model without performance degradation on several downstream tasks including text classification and machine reading comprehension.
CPT: Colorful Prompt Tuning for Pre-trained Vision-Language Models
Oct 08, 2021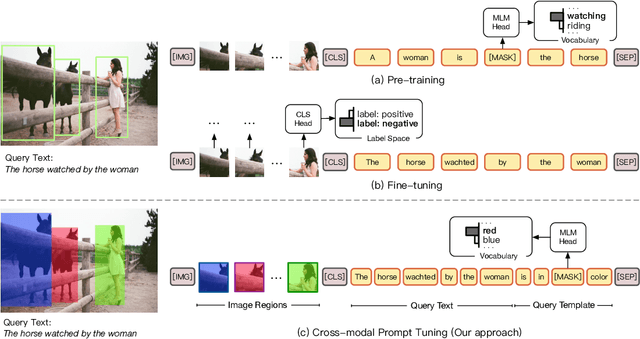
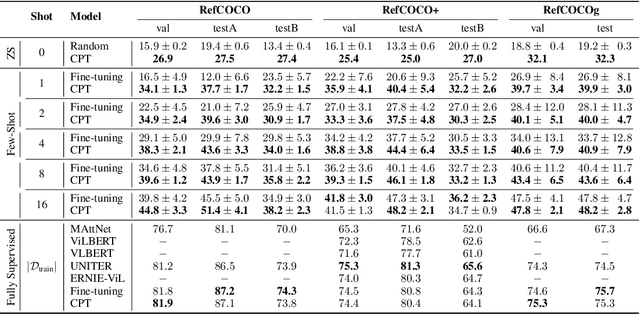
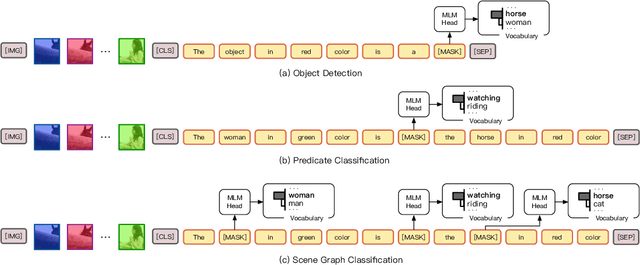
Pre-Trained Vision-Language Models (VL-PTMs) have shown promising capabilities in grounding natural language in image data, facilitating a broad variety of cross-modal tasks. However, we note that there exists a significant gap between the objective forms of model pre-training and fine-tuning, resulting in a need for large amounts of labeled data to stimulate the visual grounding capability of VL-PTMs for downstream tasks. To address the challenge, we present Cross-modal Prompt Tuning (CPT, alternatively, Colorful Prompt Tuning), a novel paradigm for tuning VL-PTMs, which reformulates visual grounding into a fill-in-the-blank problem with color-based co-referential markers in image and text, maximally mitigating the gap. In this way, CPT enables strong few-shot and even zero-shot visual grounding capabilities of VL-PTMs. Comprehensive experimental results show that the prompt-tuned VL-PTMs outperform their fine-tuned counterparts by a large margin (e.g., 17.3% absolute accuracy improvement, and 73.8% relative standard deviation reduction on average with one shot in RefCOCO evaluation). All the data and codes will be available to facilitate future research.
CPM-2: Large-scale Cost-effective Pre-trained Language Models
Jun 24, 2021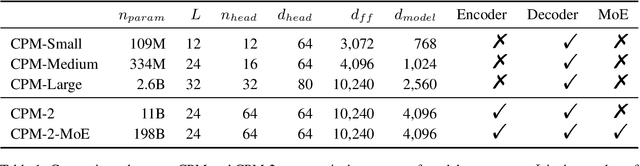

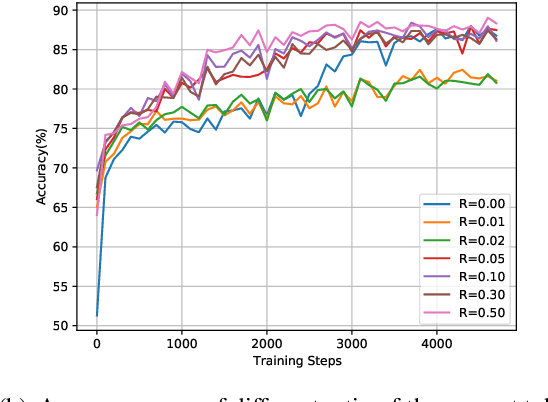
In recent years, the size of pre-trained language models (PLMs) has grown by leaps and bounds. However, efficiency issues of these large-scale PLMs limit their utilization in real-world scenarios. We present a suite of cost-effective techniques for the use of PLMs to deal with the efficiency issues of pre-training, fine-tuning, and inference. (1) We introduce knowledge inheritance to accelerate the pre-training process by exploiting existing PLMs instead of training models from scratch. (2) We explore the best practice of prompt tuning with large-scale PLMs. Compared with conventional fine-tuning, prompt tuning significantly reduces the number of task-specific parameters. (3) We implement a new inference toolkit, namely InfMoE, for using large-scale PLMs with limited computational resources. Based on our cost-effective pipeline, we pre-train two models: an encoder-decoder bilingual model with 11 billion parameters (CPM-2) and its corresponding MoE version with 198 billion parameters. In our experiments, we compare CPM-2 with mT5 on downstream tasks. Experimental results show that CPM-2 has excellent general language intelligence. Moreover, we validate the efficiency of InfMoE when conducting inference of large-scale models having tens of billions of parameters on a single GPU. All source code and model parameters are available at https://github.com/TsinghuaAI/CPM.
Pre-Trained Models: Past, Present and Future
Jun 15, 2021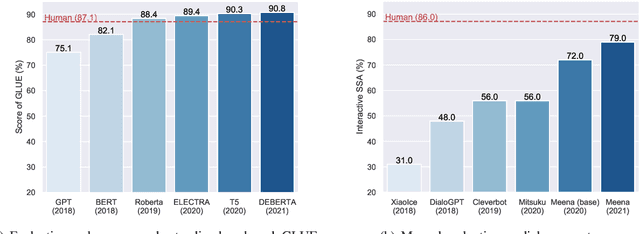
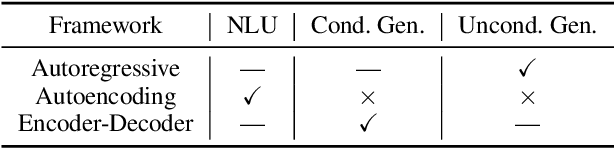
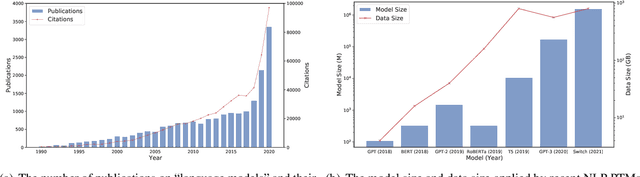
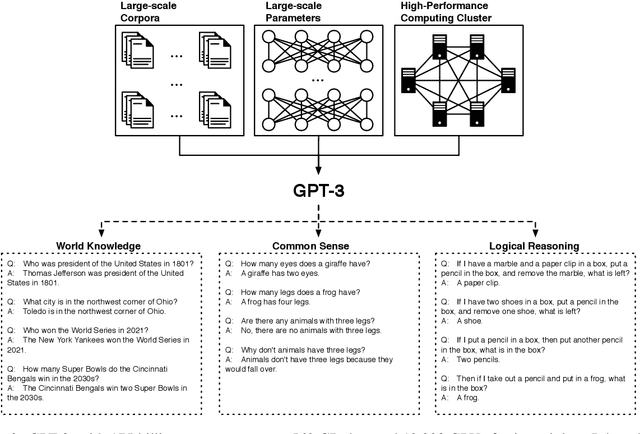
Large-scale pre-trained models (PTMs) such as BERT and GPT have recently achieved great success and become a milestone in the field of artificial intelligence (AI). Owing to sophisticated pre-training objectives and huge model parameters, large-scale PTMs can effectively capture knowledge from massive labeled and unlabeled data. By storing knowledge into huge parameters and fine-tuning on specific tasks, the rich knowledge implicitly encoded in huge parameters can benefit a variety of downstream tasks, which has been extensively demonstrated via experimental verification and empirical analysis. It is now the consensus of the AI community to adopt PTMs as backbone for downstream tasks rather than learning models from scratch. In this paper, we take a deep look into the history of pre-training, especially its special relation with transfer learning and self-supervised learning, to reveal the crucial position of PTMs in the AI development spectrum. Further, we comprehensively review the latest breakthroughs of PTMs. These breakthroughs are driven by the surge of computational power and the increasing availability of data, towards four important directions: designing effective architectures, utilizing rich contexts, improving computational efficiency, and conducting interpretation and theoretical analysis. Finally, we discuss a series of open problems and research directions of PTMs, and hope our view can inspire and advance the future study of PTMs.
Hidden Killer: Invisible Textual Backdoor Attacks with Syntactic Trigger
Jun 03, 2021

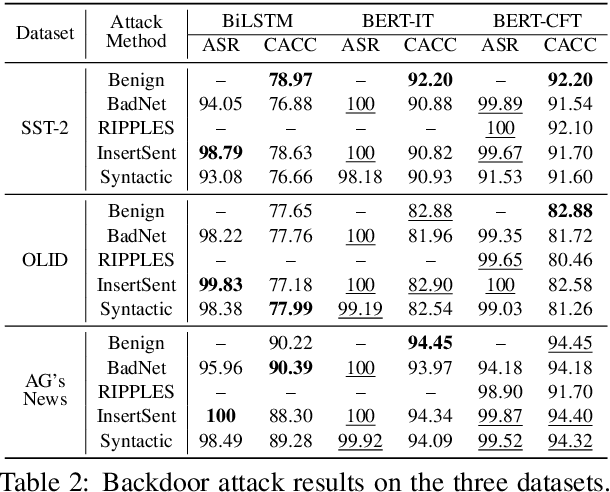
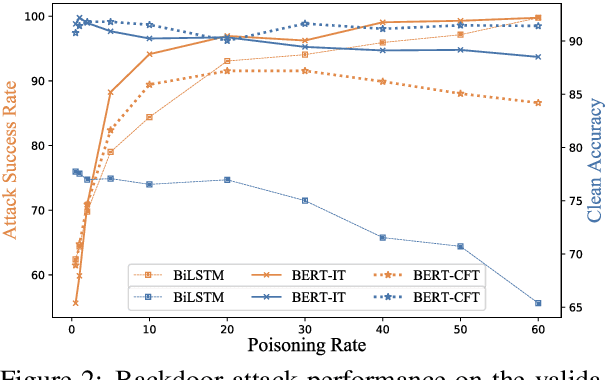
Backdoor attacks are a kind of insidious security threat against machine learning models. After being injected with a backdoor in training, the victim model will produce adversary-specified outputs on the inputs embedded with predesigned triggers but behave properly on normal inputs during inference. As a sort of emergent attack, backdoor attacks in natural language processing (NLP) are investigated insufficiently. As far as we know, almost all existing textual backdoor attack methods insert additional contents into normal samples as triggers, which causes the trigger-embedded samples to be detected and the backdoor attacks to be blocked without much effort. In this paper, we propose to use the syntactic structure as the trigger in textual backdoor attacks. We conduct extensive experiments to demonstrate that the syntactic trigger-based attack method can achieve comparable attack performance (almost 100% success rate) to the insertion-based methods but possesses much higher invisibility and stronger resistance to defenses. These results also reveal the significant insidiousness and harmfulness of textual backdoor attacks. All the code and data of this paper can be obtained at https://github.com/thunlp/HiddenKiller.
SHUOWEN-JIEZI: Linguistically Informed Tokenizers For Chinese Language Model Pretraining
Jun 01, 2021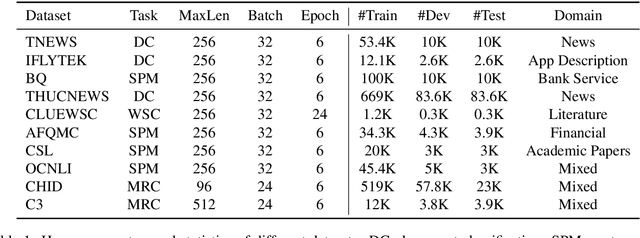
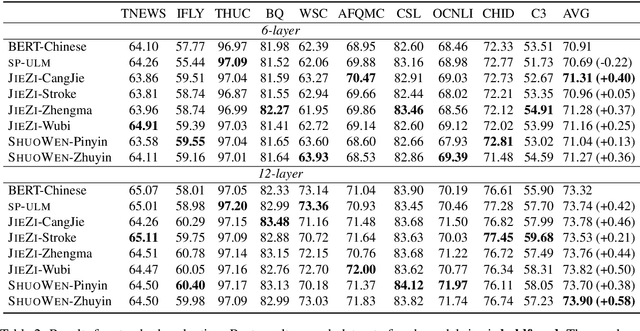
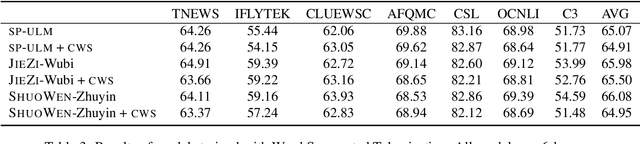
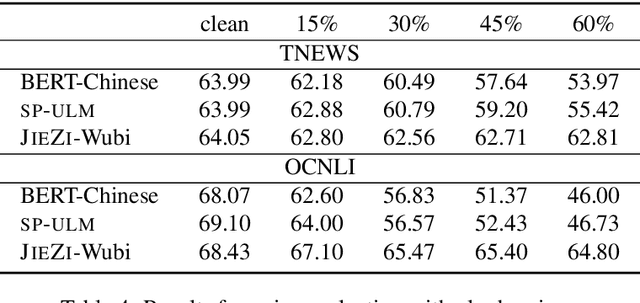
Conventional tokenization methods for Chinese pretrained language models (PLMs) treat each character as an indivisible token (Devlin et al., 2019), which ignores the characteristics of the Chinese writing system. In this work, we comprehensively study the influences of three main factors on the Chinese tokenization for PLM: pronunciation, glyph (i.e., shape), and word boundary. Correspondingly, we propose three kinds of tokenizers: 1) SHUOWEN (meaning Talk Word), the pronunciation-based tokenizers; 2) JIEZI (meaning Solve Character), the glyph-based tokenizers; 3) Word segmented tokenizers, the tokenizers with Chinese word segmentation. To empirically compare the effectiveness of studied tokenizers, we pretrain BERT-style language models with them and evaluate the models on various downstream NLU tasks. We find that SHUOWEN and JIEZI tokenizers can generally outperform conventional single-character tokenizers, while Chinese word segmentation shows no benefit as a preprocessing step. Moreover, the proposed SHUOWEN and JIEZI tokenizers exhibit significantly better robustness in handling noisy texts. The code and pretrained models will be publicly released to facilitate linguistically informed Chinese NLP.