 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoEfication: Conditional Computation of Transformer Models for Efficient Inference
Paper and Code
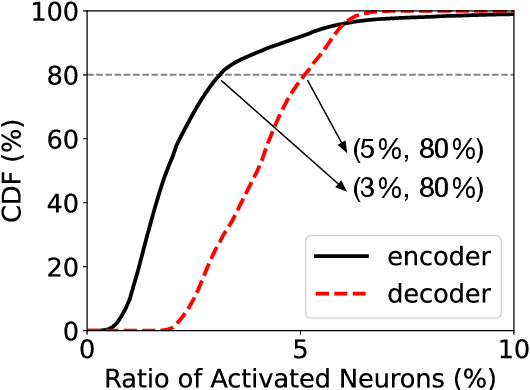
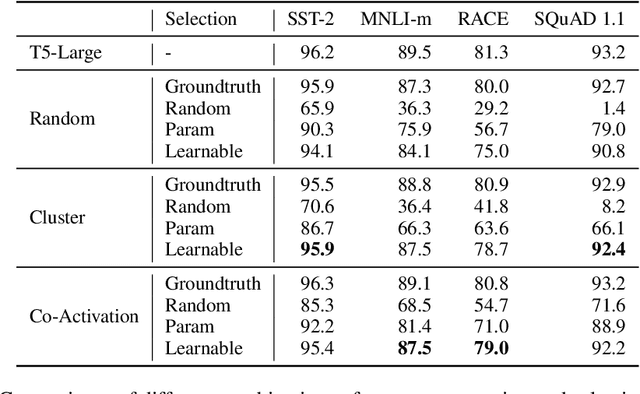
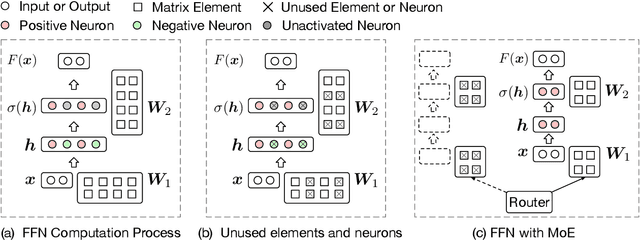
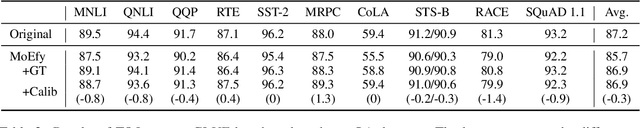
Transformer-based pre-trained language models can achieve superior performance on most NLP tasks due to large parameter capacity, but also lead to huge computation cost. Fortunately, we observe that most inputs only activate a tiny ratio of neurons of large Transformer-based models during inference. Hence, we propose to transform a large model into its mixture-of-experts (MoE) version with equal model size, namely MoEfication, which could accelerate large-model inference by conditional computation based on the sparse activation phenomenon. MoEfication consists of two steps: (1) splitting the parameters of feed-forward neural networks (FFNs) into multiple parts as experts, and (2) building expert routers to decide which experts will be used for each input. Experimental results show that the MoEfied models can significantly reduce computation cost, e.g., only activating 20% FFN parameters of a 700-million-parameter model without performance degradation on several downstream tasks including text classification and machine reading comprehension.