 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAGroup3D: Class-Aware Grouping for 3D Object Detection on Point Clouds
Oct 09, 2022
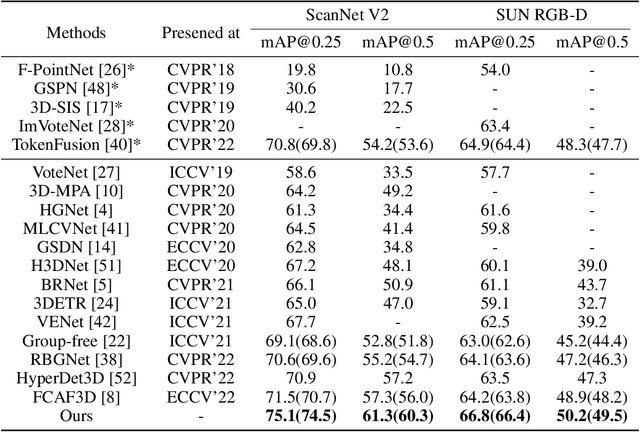
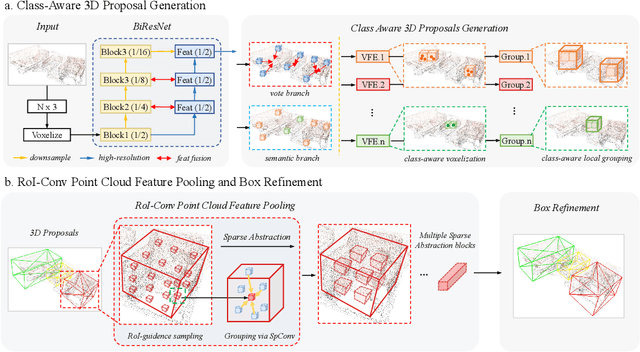

We present a novel two-stage fully sparse convolutional 3D object detection framework, named CAGroup3D. Our proposed method first generates some high-quality 3D proposals by leveraging the class-aware local group strategy on the object surface voxels with the same semantic predictions, which considers semantic consistency and diverse locality abandoned in previous bottom-up approaches. Then, to recover the features of missed voxels due to incorrect voxel-wise segmentation, we build a fully sparse convolutional RoI pooling module to directly aggregate fine-grained spatial information from backbone for further proposal refinement. It is memory-and-computation efficient and can better encode the geometry-specific features of each 3D proposal. Our model achieves state-of-the-art 3D detection performance with remarkable gains of +\textit{3.6\%} on ScanNet V2 and +\textit{2.6}\% on SUN RGB-D in term of mAP@0.25. Code will be available at https://github.com/Haiyang-W/CAGroup3D.
DevNet: Self-supervised Monocular Depth Learning via Density Volume Construction
Sep 20, 2022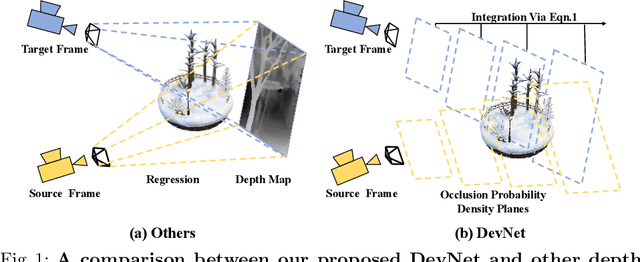
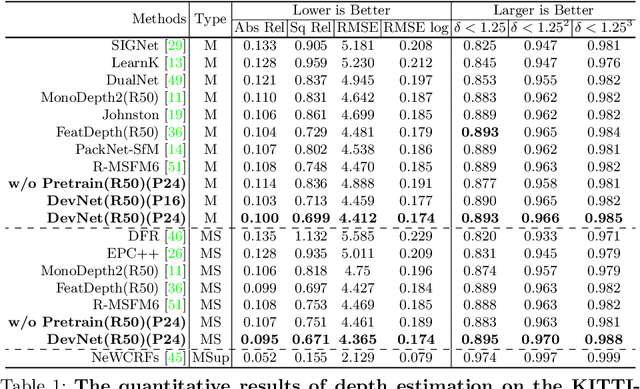
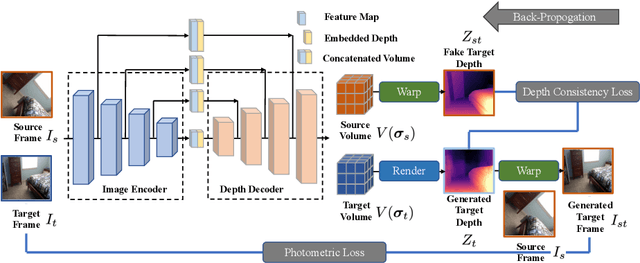

Self-supervised depth learning from monocular images normally relies on the 2D pixel-wise photometric relation between temporally adjacent image frames. However, they neither fully exploit the 3D point-wise geometric correspondences, nor effectively tackle the ambiguities in the photometric warping caused by occlusions or illumination inconsistency. To address these problems, this work proposes Density Volume Construction Network (DevNet), a novel self-supervised monocular depth learning framework, that can consider 3D spatial information, and exploit stronger geometric constraints among adjacent camera frustums. Instead of directly regressing the pixel value from a single image, our DevNet divides the camera frustum into multiple parallel planes and predicts the pointwise occlusion probability density on each plane. The final depth map is generated by integrating the density along corresponding rays. During the training process, novel regularization strategies and loss functions are introduced to mitigate photometric ambiguities and overfitting. Without obviously enlarging model parameters size or running time, DevNet outperforms several representative baselines on both the KITTI-2015 outdoor dataset and NYU-V2 indoor dataset. In particular, the root-mean-square-deviation is reduced by around 4% with DevNet on both KITTI-2015 and NYU-V2 in the task of depth estimation. Code is available at https://github.com/gitkaichenzhou/DevNet.
DetCLIP: Dictionary-Enriched Visual-Concept Paralleled Pre-training for Open-world Detection
Sep 20, 2022

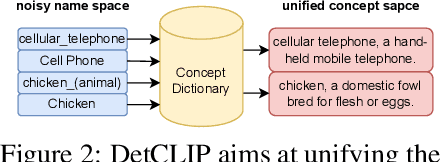

Open-world object detection, as a more general and challenging goal, aims to recognize and localize objects described by arbitrary category names. The recent work GLIP formulates this problem as a grounding problem by concatenating all category names of detection datasets into sentences, which leads to inefficient interaction between category names. This paper presents DetCLIP, a paralleled visual-concept pre-training method for open-world detection by resorting to knowledge enrichment from a designed concept dictionary. To achieve better learning efficiency, we propose a novel paralleled concept formulation that extracts concepts separately to better utilize heterogeneous datasets (i.e., detection, grounding, and image-text pairs) for training. We further design a concept dictionary~(with descriptions) from various online sources and detection datasets to provide prior knowledge for each concept. By enriching the concepts with their descriptions, we explicitly build the relationships among various concepts to facilitate the open-domain learning. The proposed concept dictionary is further used to provide sufficient negative concepts for the construction of the word-region alignment loss\, and to complete labels for objects with missing descriptions in captions of image-text pair data. The proposed framework demonstrates strong zero-shot detection performances, e.g., on the LVIS dataset, our DetCLIP-T outperforms GLIP-T by 9.9% mAP and obtains a 13.5% improvement on rare categories compared to the fully-supervised model with the same backbone as ours.
Improved OOD Generalization via Conditional Invariant Regularizer
Jul 14, 2022
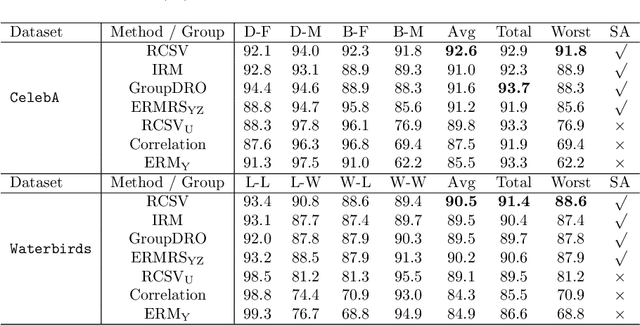
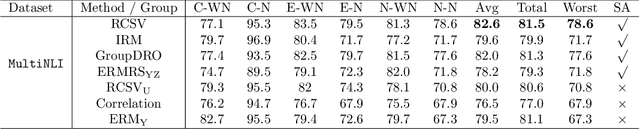

Recently, generalization on out-of-distribution (OOD) data with correlation shift has attracted great attention. The correlation shift is caused by the spurious attributes that correlate to the class label, as the correlation between them may vary in training and test data. For such a problem, we show that given the class label, the conditionally independent models of spurious attributes are OOD generalizable. Based on this, a metric Conditional Spurious Variation (CSV) which controls OOD generalization error, is proposed to measure such conditional independence. To improve the OOD generalization, we regularize the training process with the proposed CSV. Under mild assumptions, our training objective can be formulated as a nonconvex-concave mini-max problem. An algorithm with provable convergence rate is proposed to solve the problem. Extensive empirical results verify our algorithm's efficacy in improving OOD generalization.
Learning to Prove Trigonometric Identities
Jul 14, 2022Automatic theorem proving with deep learning methods has attracted attentions recently. In this paper, we construct an automatic proof system for trigonometric identities. We define the normalized form of trigonometric identities, design a set of rules for the proof and put forward a method which can generate theoretically infinite trigonometric identities. Our goal is not only to complete the proof, but to complete the proof in as few steps as possible. For this reason, we design a model to learn proof data generated by random BFS (rBFS), and it is proved theoretically and experimentally that the model can outperform rBFS after a simple imitation learning. After further improvement through reinforcement learning, we get AutoTrig, which can give proof steps for identities in almost as short steps as BFS (theoretically shortest method), with a time cost of only one-thousandth. In addition, AutoTrig also beats Sympy, Matlab and human in the synthetic dataset, and performs well in many generalization tasks.
PILC: Practical Image Lossless Compression with an End-to-end GPU Oriented Neural Framework
Jun 10, 2022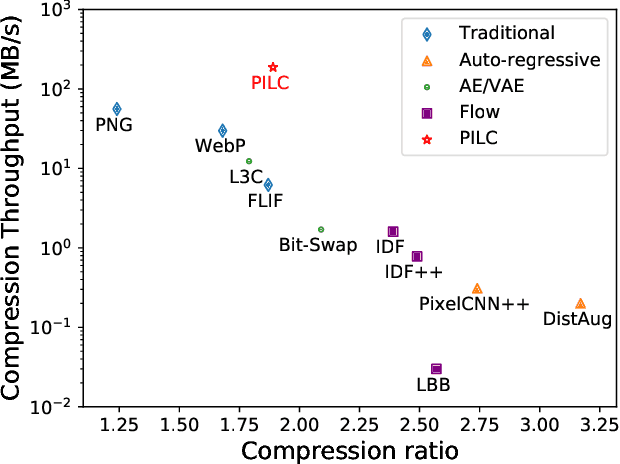

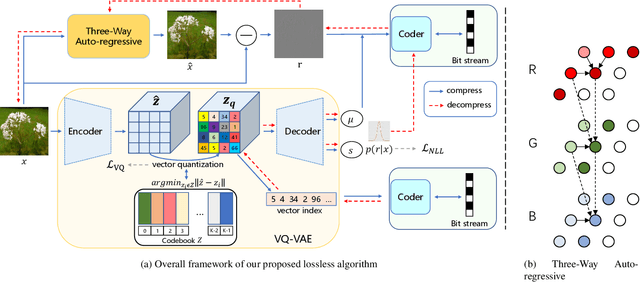

Generative model based image lossless compression algorithms have seen a great success in improving compression ratio. However, the throughput for most of them is less than 1 MB/s even with the most advanced AI accelerated chips, preventing them from most real-world applications, which often require 100 MB/s. In this paper, we propose PILC, an end-to-end image lossless compression framework that achieves 200 MB/s for both compression and decompression with a single NVIDIA Tesla V100 GPU, 10 times faster than the most efficient one before. To obtain this result, we first develop an AI codec that combines auto-regressive model and VQ-VAE which performs well in lightweight setting, then we design a low complexity entropy coder that works well with our codec. Experiments show that our framework compresses better than PNG by a margin of 30% in multiple datasets. We believe this is an important step to bring AI compression forward to commercial use.
CO^3: Cooperative Unsupervised 3D Representation Learning for Autonomous Driving
Jun 08, 2022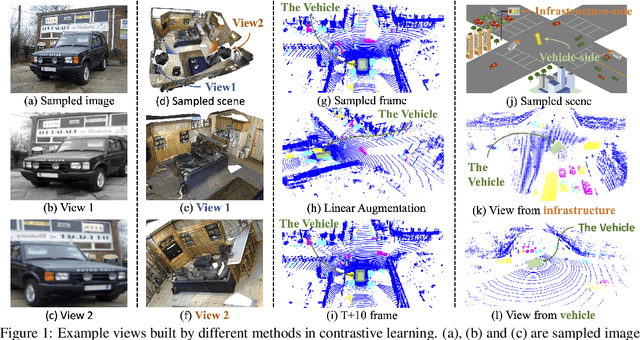
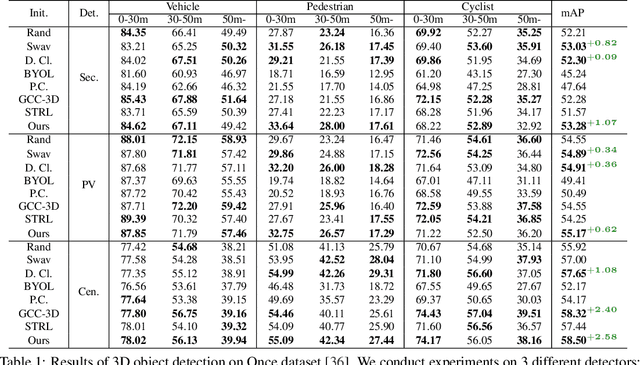
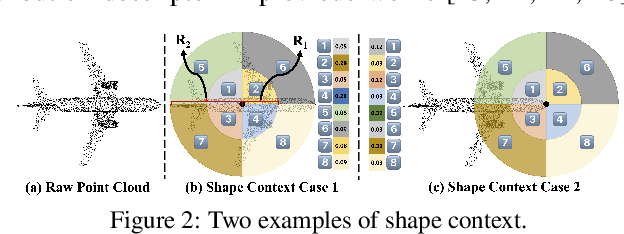
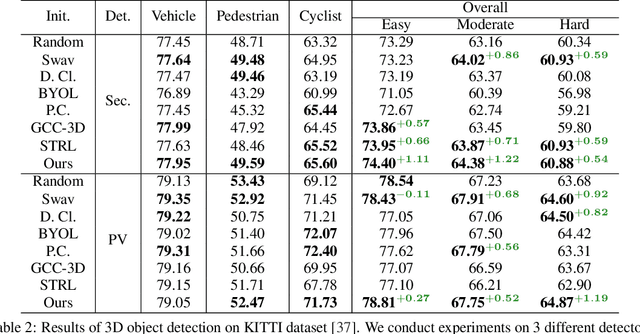
Unsupervised contrastive learning for indoor-scene point clouds has achieved great successes. However, unsupervised learning point clouds in outdoor scenes remains challenging because previous methods need to reconstruct the whole scene and capture partial views for the contrastive objective. This is infeasible in outdoor scenes with moving objects, obstacles, and sensors. In this paper, we propose CO^3, namely Cooperative Contrastive Learning and Contextual Shape Prediction, to learn 3D representation for outdoor-scene point clouds in an unsupervised manner. CO^3 has several merits compared to existing methods. (1) It utilizes LiDAR point clouds from vehicle-side and infrastructure-side to build views that differ enough but meanwhile maintain common semantic information for contrastive learning, which are more appropriate than views built by previous methods. (2) Alongside the contrastive objective, shape context prediction is proposed as pre-training goal and brings more task-relevant information for unsupervised 3D point cloud representation learning, which are beneficial when transferring the learned representation to downstream detection tasks. (3) As compared to previous methods, representation learned by CO^3 is able to be transferred to different outdoor scene dataset collected by different type of LiDAR sensors. (4) CO^3 improves current state-of-the-art methods on both Once and KITTI datasets by up to 2.58 mAP. Codes and models will be released. We believe CO^3 will facilitate understanding LiDAR point clouds in outdoor scene.
Task-Customized Self-Supervised Pre-training with Scalable Dynamic Routing
May 26, 2022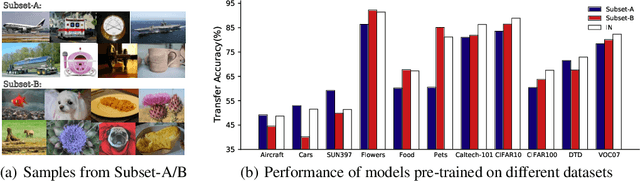
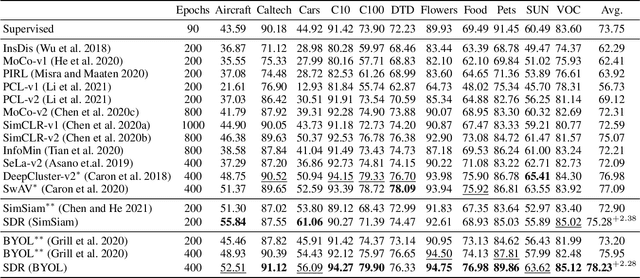
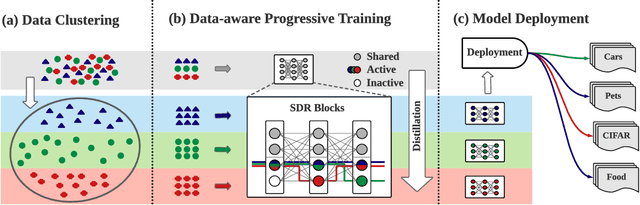
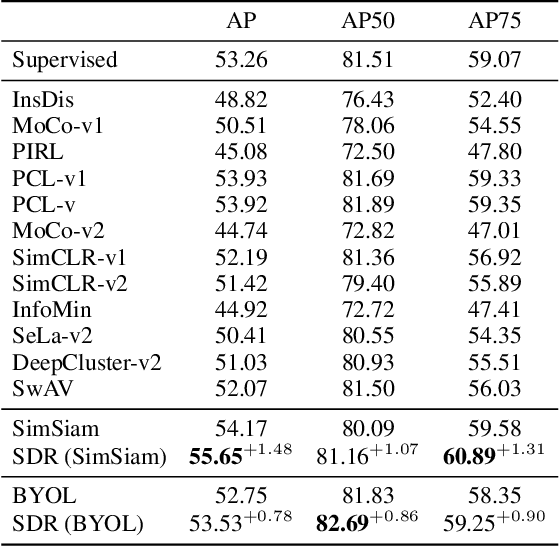
Self-supervised learning (SSL), especially contrastive methods, has raised attraction recently as it learns effective transferable representations without semantic annotations. A common practice for self-supervised pre-training is to use as much data as possible. For a specific downstream task, however, involving irrelevant data in pre-training may degenerate the downstream performance, observed from our extensive experiments. On the other hand, for existing SSL methods, it is burdensome and infeasible to use different downstream-task-customized datasets in pre-training for different tasks. To address this issue, we propose a novel SSL paradigm called Scalable Dynamic Routing (SDR), which can be trained once and deployed efficiently to different downstream tasks with task-customized pre-trained models. Specifically, we construct the SDRnet with various sub-nets and train each sub-net with only one subset of the data by data-aware progressive training. When a downstream task arrives, we route among all the pre-trained sub-nets to get the best along with its corresponding weights. Experiment results show that our SDR can train 256 sub-nets on ImageNet simultaneously, which provides better transfer performance than a unified model trained on the full ImageNet, achieving state-of-the-art (SOTA) averaged accuracy over 11 downstream classification tasks and AP on PASCAL VOC detection task.
ZeroGen$^+$: Self-Guided High-Quality Data Generation in Efficient Zero-Shot Learning
May 25, 2022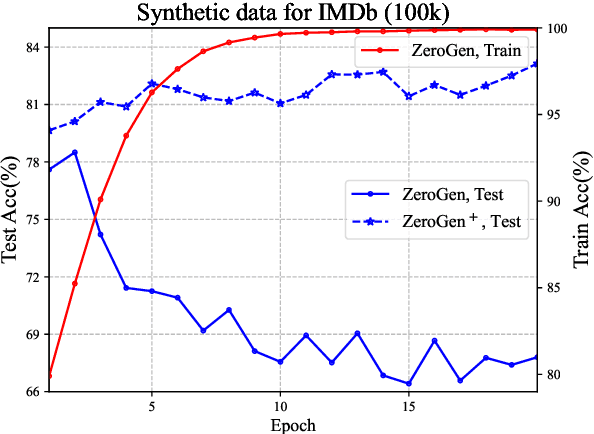
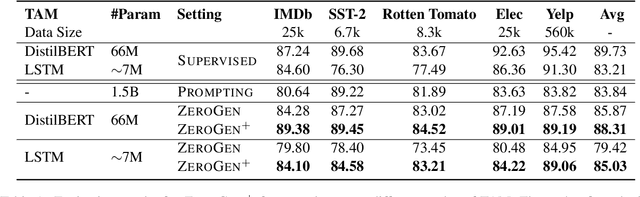
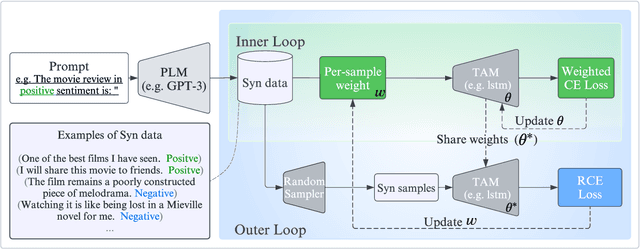
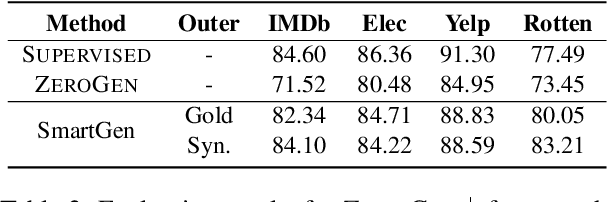
Nowadays, owing to the superior capacity of the large pre-trained language models (PLM), the PLM-based zero-shot learning has shown promising performances on various natural language processing tasks. There are emerging interests in further exploring the zero-shot learning potential of PLMs. Among them, ZeroGen attempts to purely use PLM to generate data and train a tiny model without relying on any task-specific annotation. Despite its remarkable results, we observe that the synthesized data from PLM contains a significant portion of samples with low quality, overfitting on such data greatly hampers the performance of the trained model and makes it unreliable for deployment.Since no gold data is accessible in zero-shot scenario, it is hard to perform model/data selection to prevent overfitting to the low-quality data. To address this problem, we propose a noise-robust bi-level re-weighting framework which is able to learn the per-sample weights measuring the data quality without requiring any gold data. With the learnt weights, clean subsets of different sizes can then be sampled to train the task model. We theoretically and empirically verify our method is able to construct synthetic dataset with good quality. Our method yeilds a 7.1% relative improvement than ZeroGen on average accuracy across five different established text classification tasks.
Arch-Graph: Acyclic Architecture Relation Predictor for Task-Transferable Neural Architecture Search
Apr 12, 2022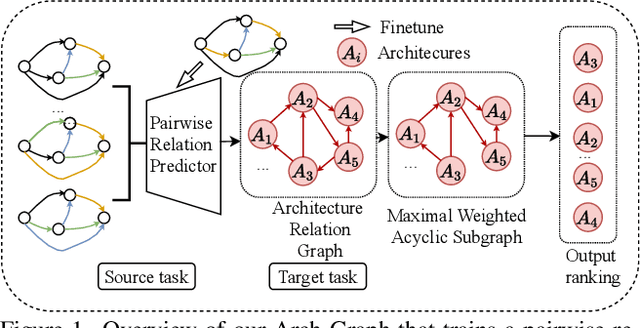
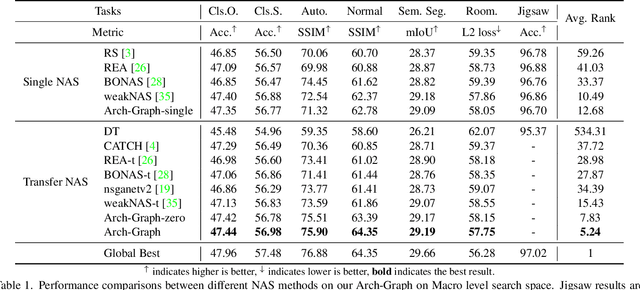
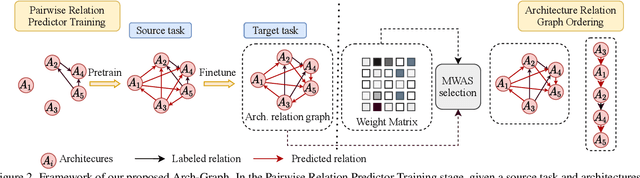
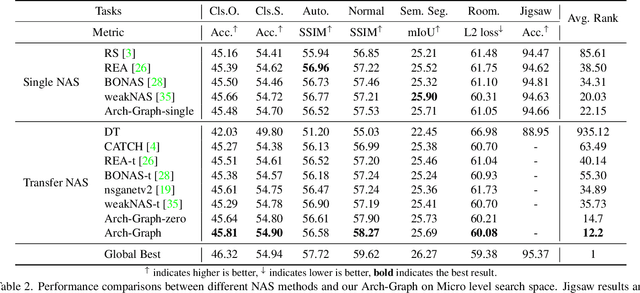
Neural Architecture Search (NAS) aims to find efficient models for multiple tasks. Beyond seeking solutions for a single task, there are surging interests in transferring network design knowledge across multiple tasks. In this line of research, effectively modeling task correlations is vital yet highly neglected. Therefore, we propose \textbf{Arch-Graph}, a transferable NAS method that predicts task-specific optimal architectures with respect to given task embeddings. It leverages correlations across multiple tasks by using their embeddings as a part of the predictor's input for fast adaptation. We also formulate NAS as an architecture relation graph prediction problem, with the relational graph constructed by treating candidate architectures as nodes and their pairwise relations as edges. To enforce some basic properties such as acyclicity in the relational graph, we add additional constraints to the optimization process, converting NAS into the problem of finding a Maximal Weighted Acyclic Subgraph (MWAS). Our algorithm then strives to eliminate cycles and only establish edges in the graph if the rank results can be trusted. Through MWAS, Arch-Graph can effectively rank candidate models for each task with only a small budget to finetune the predictor. With extensive experiments on TransNAS-Bench-101, we show Arch-Graph's transferability and high sample efficiency across numerous tasks, beating many NAS methods designed for both single-task and multi-task search. It is able to find top 0.16\% and 0.29\% architectures on average on two search spaces under the budget of only 50 models.