 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow Your Track: Precise Skeleton Animation Controlled by 3D Trajectories
Jun 24, 20264D generation aims to animate 3D objects with realistic motion, holding great promise for applications. Existing methods typically decouple 3D asset generation from motion synthesis: acquire a 3D asset, prepare a structural representation like mesh and Gaussians, and synthesize motion from text or video control signals. However, dense mesh and Gaussian representations incur high computational costs and are prone to temporal artifacts, limiting animation quality and duration to only short clips. Meanwhile, text lacks fine-grained spatial and temporal details such as timing and coordination, while video entangles motion with appearance and background. Together, these limitations result in 4D animations that suffer from poor temporal consistency, wrong identification, and limited controllability. We address these issues with \texttt{ACT}, a trajectory-conditioned framework for topology-general skeletal animation. ACT uses skeletons as a compact structured and compute-efficient representation and 3D point trajectories from monocular video as explicit motion guidance which provide detailed motion patterns without appearance entanglement. At the core of ACT is a Routed Trajectory Injector, which achieves accurate and robust trajectory-to-joint transfer through three complementary designs: prior-guided hard routing establishes precise skeleton-to-mesh correspondences, global routing enables holistic joint-track interaction for full-body motion awareness, and local windowed cross-attention enforces fine-grained temporal alignment, improving micro-timing and reducing motion misalignment across varying motion rates. Extensive experiments demonstrate that \texttt{ACT} significantly outperforms existing methods in fidelity and temporal consistency.
Tail-Aware HiFloat4: W4A4 Post-Training Quantization for Wan2.2
May 26, 2026This report describes Tail-Aware HiFloat4, our submission to the low-bit text-to-video generation quantization challenge. Our method adapts the public ViDiT-Q post-training quantization pipeline to Wan2.2 under the HiFloat4 numerical format. We quantize the main linear layers in both Wan2.2 transformer modules with W4A4 HiFloat4 fake quantization, keep numerically sensitive boundary modules in high precision, and introduce an activation-tail-aware percentile calibration module for channel-mask construction. Together with compact PTQ-state restoration, this design reduces the influence of rare calibration outliers while keeping the runtime HiFloat4 arithmetic and sampling pipeline unchanged.
GS-STVSR: Ultra-Efficient Continuous Spatio-Temporal Video Super-Resolution via 2D Gaussian Splatting
Apr 20, 2026Continuous Spatio-Temporal Video Super-Resolution (C-STVSR) aims to simultaneously enhance the spatial resolution and frame rate of videos by arbitrary scale factors, offering greater flexibility than fixed-scale methods that are constrained by predefined upsampling ratios. In recent years, methods based on Implicit Neural Representations (INR) have made significant progress in C-STVSR by learning continuous mappings from spatio-temporal coordinates to pixel values. However, these methods fundamentally rely on dense pixel-wise grid queries, causing computational cost to scale linearly with the number of interpolated frames and severely limiting inference efficiency. We propose GS-STVSR, an ultra-efficient C-STVSR framework based on 2D Gaussian Splatting (2D-GS) that drives the spatiotemporal evolution of Gaussian kernels through continuous motion modeling, bypassing dense grid queries entirely. We exploit the strong temporal stability of covariance parameters for lightweight intermediate fitting, design an optical flow-guided motion module to derive Gaussian position and color at arbitrary time steps, introduce a Covariance resampling alignment module to prevent covariance drift, and propose an adaptive offset window for large-scale motion. Extensive experiments on Vid4, GoPro, and Adobe240 show that GS-STVSR achieves state-of-the-art quality across all benchmarks. Moreover, its inference time remains nearly constant at conventional temporal scales (X2--X8) and delivers over X3 speedup at extreme scales X32, demonstrating strong practical applicability.
Iterative Inference-time Scaling with Adaptive Frequency Steering for Image Super-Resolution
Dec 29, 2025Diffusion models have become a leading paradigm for image super-resolution (SR), but existing methods struggle to guarantee both the high-frequency perceptual quality and the low-frequency structural fidelity of generated images. Although inference-time scaling can theoretically improve this trade-off by allocating more computation, existing strategies remain suboptimal: reward-driven particle optimization often causes perceptual over-smoothing, while optimal-path search tends to lose structural consistency. To overcome these difficulties, we propose Iterative Diffusion Inference-Time Scaling with Adaptive Frequency Steering (IAFS), a training-free framework that jointly leverages iterative refinement and frequency-aware particle fusion. IAFS addresses the challenge of balancing perceptual quality and structural fidelity by progressively refining the generated image through iterative correction of structural deviations. Simultaneously, it ensures effective frequency fusion by adaptively integrating high-frequency perceptual cues with low-frequency structural information, allowing for a more accurate and balanced reconstruction across different image details. Extensive experiments across multiple diffusion-based SR models show that IAFS effectively resolves the perception-fidelity conflict, yielding consistently improved perceptual detail and structural accuracy, and outperforming existing inference-time scaling methods.
Recycling Pretrained Checkpoints: Orthogonal Growth of Mixture-of-Experts for Efficient Large Language Model Pre-Training
Oct 09, 2025The rapidly increasing computational cost of pretraining Large Language Models necessitates more efficient approaches. Numerous computational costs have been invested in existing well-trained checkpoints, but many of them remain underutilized due to engineering constraints or limited model capacity. To efficiently reuse this "sunk" cost, we propose to recycle pretrained checkpoints by expanding their parameter counts and continuing training. We propose orthogonal growth method well-suited for converged Mixture-of-Experts model: interpositional layer copying for depth growth and expert duplication with injected noise for width growth. To determine the optimal timing for such growth across checkpoints sequences, we perform comprehensive scaling experiments revealing that the final accuracy has a strong positive correlation with the amount of sunk cost, indicating that greater prior investment leads to better performance. We scale our approach to models with 70B parameters and over 1T training tokens, achieving 10.66% accuracy gain over training from scratch under the same additional compute budget. Our checkpoint recycling approach establishes a foundation for economically efficient large language model pretraining.
GRACE: Estimating Geometry-level 3D Human-Scene Contact from 2D Images
May 10, 2025

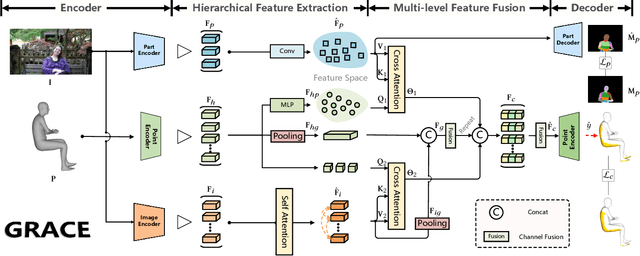

Estimating the geometry level of human-scene contact aims to ground specific contact surface points at 3D human geometries, which provides a spatial prior and bridges the interaction between human and scene, supporting applications such as human behavior analysis, embodied AI, and AR/VR. To complete the task, existing approaches predominantly rely on parametric human models (e.g., SMPL), which establish correspondences between images and contact regions through fixed SMPL vertex sequences. This actually completes the mapping from image features to an ordered sequence. However, this approach lacks consideration of geometry, limiting its generalizability in distinct human geometries. In this paper, we introduce GRACE (Geometry-level Reasoning for 3D Human-scene Contact Estimation), a new paradigm for 3D human contact estimation. GRACE incorporates a point cloud encoder-decoder architecture along with a hierarchical feature extraction and fusion module, enabling the effective integration of 3D human geometric structures with 2D interaction semantics derived from images. Guided by visual cues, GRACE establishes an implicit mapping from geometric features to the vertex space of the 3D human mesh, thereby achieving accurate modeling of contact regions. This design ensures high prediction accuracy and endows the framework with strong generalization capability across diverse human geometries. Extensive experiments on multiple benchmark datasets demonstrate that GRACE achieves state-of-the-art performance in contact estimation, with additional results further validating its robust generalization to unstructured human point clouds.
EMoTive: Event-guided Trajectory Modeling for 3D Motion Estimation
Mar 17, 2025Visual 3D motion estimation aims to infer the motion of 2D pixels in 3D space based on visual cues. The key challenge arises from depth variation induced spatio-temporal motion inconsistencies, disrupting the assumptions of local spatial or temporal motion smoothness in previous motion estimation frameworks. In contrast, event cameras offer new possibilities for 3D motion estimation through continuous adaptive pixel-level responses to scene changes. This paper presents EMoTive, a novel event-based framework that models spatio-temporal trajectories via event-guided non-uniform parametric curves, effectively characterizing locally heterogeneous spatio-temporal motion. Specifically, we first introduce Event Kymograph - an event projection method that leverages a continuous temporal projection kernel and decouples spatial observations to encode fine-grained temporal evolution explicitly. For motion representation, we introduce a density-aware adaptation mechanism to fuse spatial and temporal features under event guidance, coupled with a non-uniform rational curve parameterization framework to adaptively model heterogeneous trajectories. The final 3D motion estimation is achieved through multi-temporal sampling of parametric trajectories, yielding optical flow and depth motion fields. To facilitate evaluation, we introduce CarlaEvent3D, a multi-dynamic synthetic dataset for comprehensive validation. Extensive experiments on both this dataset and a real-world benchmark demonstrate the effectiveness of the proposed method.
PFSD: A Multi-Modal Pedestrian-Focus Scene Dataset for Rich Tasks in Semi-Structured Environments
Feb 24, 2025Recent advancements in autonomous driving perception have revealed exceptional capabilities within structured environments dominated by vehicular traffic. However, current perception models exhibit significant limitations in semi-structured environments, where dynamic pedestrians with more diverse irregular movement and occlusion prevail. We attribute this shortcoming to the scarcity of high-quality datasets in semi-structured scenes, particularly concerning pedestrian perception and prediction. In this work, we present the multi-modal Pedestrian-Focused Scene Dataset(PFSD), rigorously annotated in semi-structured scenes with the format of nuScenes. PFSD provides comprehensive multi-modal data annotations with point cloud segmentation, detection, and object IDs for tracking. It encompasses over 130,000 pedestrian instances captured across various scenarios with varying densities, movement patterns, and occlusions. Furthermore, to demonstrate the importance of addressing the challenges posed by more diverse and complex semi-structured environments, we propose a novel Hybrid Multi-Scale Fusion Network (HMFN). Specifically, to detect pedestrians in densely populated and occluded scenarios, our method effectively captures and fuses multi-scale features using a meticulously designed hybrid framework that integrates sparse and vanilla convolutions. Extensive experiments on PFSD demonstrate that HMFN attains improvement in mean Average Precision (mAP) over existing methods, thereby underscoring its efficacy in addressing the challenges of 3D pedestrian detection in complex semi-structured environments. Coding and benchmark are available.
Optimizing Large Language Model Training Using FP4 Quantization
Jan 28, 2025



The growing computational demands of training large language models (LLMs) necessitate more efficient methods. Quantized training presents a promising solution by enabling low-bit arithmetic operations to reduce these costs. While FP8 precision has demonstrated feasibility, leveraging FP4 remains a challenge due to significant quantization errors and limited representational capacity. This work introduces the first FP4 training framework for LLMs, addressing these challenges with two key innovations: a differentiable quantization estimator for precise weight updates and an outlier clamping and compensation strategy to prevent activation collapse. To ensure stability, the framework integrates a mixed-precision training scheme and vector-wise quantization. Experimental results demonstrate that our FP4 framework achieves accuracy comparable to BF16 and FP8, with minimal degradation, scaling effectively to 13B-parameter LLMs trained on up to 100B tokens. With the emergence of next-generation hardware supporting FP4, our framework sets a foundation for efficient ultra-low precision training.
Real-Time 4K Super-Resolution of Compressed AVIF Images. AIS 2024 Challenge Survey
Apr 25, 2024



This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.