 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRACE: Estimating Geometry-level 3D Human-Scene Contact from 2D Images
May 10, 2025

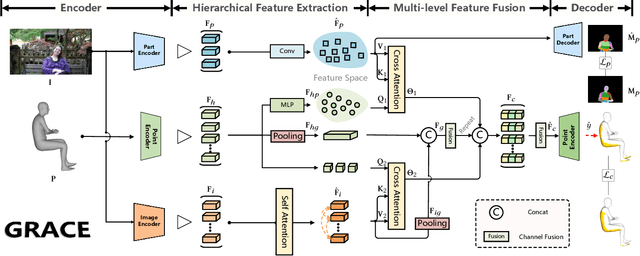

Estimating the geometry level of human-scene contact aims to ground specific contact surface points at 3D human geometries, which provides a spatial prior and bridges the interaction between human and scene, supporting applications such as human behavior analysis, embodied AI, and AR/VR. To complete the task, existing approaches predominantly rely on parametric human models (e.g., SMPL), which establish correspondences between images and contact regions through fixed SMPL vertex sequences. This actually completes the mapping from image features to an ordered sequence. However, this approach lacks consideration of geometry, limiting its generalizability in distinct human geometries. In this paper, we introduce GRACE (Geometry-level Reasoning for 3D Human-scene Contact Estimation), a new paradigm for 3D human contact estimation. GRACE incorporates a point cloud encoder-decoder architecture along with a hierarchical feature extraction and fusion module, enabling the effective integration of 3D human geometric structures with 2D interaction semantics derived from images. Guided by visual cues, GRACE establishes an implicit mapping from geometric features to the vertex space of the 3D human mesh, thereby achieving accurate modeling of contact regions. This design ensures high prediction accuracy and endows the framework with strong generalization capability across diverse human geometries. Extensive experiments on multiple benchmark datasets demonstrate that GRACE achieves state-of-the-art performance in contact estimation, with additional results further validating its robust generalization to unstructured human point clouds.
EgoChoir: Capturing 3D Human-Object Interaction Regions from Egocentric Views
May 22, 2024



Understanding egocentric human-object interaction (HOI) is a fundamental aspect of human-centric perception, facilitating applications like AR/VR and embodied AI. For the egocentric HOI, in addition to perceiving semantics e.g., ''what'' interaction is occurring, capturing ''where'' the interaction specifically manifests in 3D space is also crucial, which links the perception and operation. Existing methods primarily leverage observations of HOI to capture interaction regions from an exocentric view. However, incomplete observations of interacting parties in the egocentric view introduce ambiguity between visual observations and interaction contents, impairing their efficacy. From the egocentric view, humans integrate the visual cortex, cerebellum, and brain to internalize their intentions and interaction concepts of objects, allowing for the pre-formulation of interactions and making behaviors even when interaction regions are out of sight. In light of this, we propose harmonizing the visual appearance, head motion, and 3D object to excavate the object interaction concept and subject intention, jointly inferring 3D human contact and object affordance from egocentric videos. To achieve this, we present EgoChoir, which links object structures with interaction contexts inherent in appearance and head motion to reveal object affordance, further utilizing it to model human contact. Additionally, a gradient modulation is employed to adopt appropriate clues for capturing interaction regions across various egocentric scenarios. Moreover, 3D contact and affordance are annotated for egocentric videos collected from Ego-Exo4D and GIMO to support the task. Extensive experiments on them demonstrate the effectiveness and superiority of EgoChoir. Code and data will be open.