 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGREF: Masked Guidance for Any-Reference Video Generation
May 29, 2025Video generation has made substantial strides with the emergence of deep generative models, especially diffusion-based approaches. However, video generation based on multiple reference subjects still faces significant challenges in maintaining multi-subject consistency and ensuring high generation quality. In this paper, we propose MAGREF, a unified framework for any-reference video generation that introduces masked guidance to enable coherent multi-subject video synthesis conditioned on diverse reference images and a textual prompt. Specifically, we propose (1) a region-aware dynamic masking mechanism that enables a single model to flexibly handle various subject inference, including humans, objects, and backgrounds, without architectural changes, and (2) a pixel-wise channel concatenation mechanism that operates on the channel dimension to better preserve appearance features. Our model delivers state-of-the-art video generation quality, generalizing from single-subject training to complex multi-subject scenarios with coherent synthesis and precise control over individual subjects, outperforming existing open-source and commercial baselines. To facilitate evaluation, we also introduce a comprehensive multi-subject video benchmark. Extensive experiments demonstrate the effectiveness of our approach, paving the way for scalable, controllable, and high-fidelity multi-subject video synthesis. Code and model can be found at: https://github.com/MAGREF-Video/MAGREF
CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance
Mar 13, 2025Video generation has witnessed remarkable progress with the advent of deep generative models, particularly diffusion models. While existing methods excel in generating high-quality videos from text prompts or single images, personalized multi-subject video generation remains a largely unexplored challenge. This task involves synthesizing videos that incorporate multiple distinct subjects, each defined by separate reference images, while ensuring temporal and spatial consistency. Current approaches primarily rely on mapping subject images to keywords in text prompts, which introduces ambiguity and limits their ability to model subject relationships effectively. In this paper, we propose CINEMA, a novel framework for coherent multi-subject video generation by leveraging Multimodal Large Language Model (MLLM). Our approach eliminates the need for explicit correspondences between subject images and text entities, mitigating ambiguity and reducing annotation effort. By leveraging MLLM to interpret subject relationships, our method facilitates scalability, enabling the use of large and diverse datasets for training. Furthermore, our framework can be conditioned on varying numbers of subjects, offering greater flexibility in personalized content creation. Through extensive evaluations, we demonstrate that our approach significantly improves subject consistency, and overall video coherence, paving the way for advanced applications in storytelling, interactive media, and personalized video generation.
VideoWorld: Exploring Knowledge Learning from Unlabeled Videos
Jan 16, 2025This work explores whether a deep generative model can learn complex knowledge solely from visual input, in contrast to the prevalent focus on text-based models like large language models (LLMs). We develop VideoWorld, an auto-regressive video generation model trained on unlabeled video data, and test its knowledge acquisition abilities in video-based Go and robotic control tasks. Our experiments reveal two key findings: (1) video-only training provides sufficient information for learning knowledge, including rules, reasoning and planning capabilities, and (2) the representation of visual change is crucial for knowledge acquisition. To improve both the efficiency and efficacy of this process, we introduce the Latent Dynamics Model (LDM) as a key component of VideoWorld. Remarkably, VideoWorld reaches a 5-dan professional level in the Video-GoBench with just a 300-million-parameter model, without relying on search algorithms or reward mechanisms typical in reinforcement learning. In robotic tasks, VideoWorld effectively learns diverse control operations and generalizes across environments, approaching the performance of oracle models in CALVIN and RLBench. This study opens new avenues for knowledge acquisition from visual data, with all code, data, and models open-sourced for further research.
DeTeCtive: Detecting AI-generated Text via Multi-Level Contrastive Learning
Oct 28, 2024



Current techniques for detecting AI-generated text are largely confined to manual feature crafting and supervised binary classification paradigms. These methodologies typically lead to performance bottlenecks and unsatisfactory generalizability. Consequently, these methods are often inapplicable for out-of-distribution (OOD) data and newly emerged large language models (LLMs). In this paper, we revisit the task of AI-generated text detection. We argue that the key to accomplishing this task lies in distinguishing writing styles of different authors, rather than simply classifying the text into human-written or AI-generated text. To this end, we propose DeTeCtive, a multi-task auxiliary, multi-level contrastive learning framework. DeTeCtive is designed to facilitate the learning of distinct writing styles, combined with a dense information retrieval pipeline for AI-generated text detection. Our method is compatible with a range of text encoders. Extensive experiments demonstrate that our method enhances the ability of various text encoders in detecting AI-generated text across multiple benchmarks and achieves state-of-the-art results. Notably, in OOD zero-shot evaluation, our method outperforms existing approaches by a large margin. Moreover, we find our method boasts a Training-Free Incremental Adaptation (TFIA) capability towards OOD data, further enhancing its efficacy in OOD detection scenarios. We will open-source our code and models in hopes that our work will spark new thoughts in the field of AI-generated text detection, ensuring safe application of LLMs and enhancing compliance. Our code is available at https://github.com/heyongxin233/DeTeCtive.
ARLON: Boosting Diffusion Transformers with Autoregressive Models for Long Video Generation
Oct 27, 2024



Text-to-video models have recently undergone rapid and substantial advancements. Nevertheless, due to limitations in data and computational resources, achieving efficient generation of long videos with rich motion dynamics remains a significant challenge. To generate high-quality, dynamic, and temporally consistent long videos, this paper presents ARLON, a novel framework that boosts diffusion Transformers with autoregressive models for long video generation, by integrating the coarse spatial and long-range temporal information provided by the AR model to guide the DiT model. Specifically, ARLON incorporates several key innovations: 1) A latent Vector Quantized Variational Autoencoder (VQ-VAE) compresses the input latent space of the DiT model into compact visual tokens, bridging the AR and DiT models and balancing the learning complexity and information density; 2) An adaptive norm-based semantic injection module integrates the coarse discrete visual units from the AR model into the DiT model, ensuring effective guidance during video generation; 3) To enhance the tolerance capability of noise introduced from the AR inference, the DiT model is trained with coarser visual latent tokens incorporated with an uncertainty sampling module. Experimental results demonstrate that ARLON significantly outperforms the baseline OpenSora-V1.2 on eight out of eleven metrics selected from VBench, with notable improvements in dynamic degree and aesthetic quality, while delivering competitive results on the remaining three and simultaneously accelerating the generation process. In addition, ARLON achieves state-of-the-art performance in long video generation. Detailed analyses of the improvements in inference efficiency are presented, alongside a practical application that demonstrates the generation of long videos using progressive text prompts. See demos of ARLON at \url{http://aka.ms/arlon}.
I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models
Dec 27, 2023



In the rapidly evolving domain of digital content generation, the focus has shifted from text-to-image (T2I) models to more advanced video diffusion models, notably text-to-video (T2V) and image-to-video (I2V). This paper addresses the intricate challenge posed by I2V: converting static images into dynamic, lifelike video sequences while preserving the original image fidelity. Traditional methods typically involve integrating entire images into diffusion processes or using pretrained encoders for cross attention. However, these approaches often necessitate altering the fundamental weights of T2I models, thereby restricting their reusability. We introduce a novel solution, namely I2V-Adapter, designed to overcome such limitations. Our approach preserves the structural integrity of T2I models and their inherent motion modules. The I2V-Adapter operates by processing noised video frames in parallel with the input image, utilizing a lightweight adapter module. This module acts as a bridge, efficiently linking the input to the model's self-attention mechanism, thus maintaining spatial details without requiring structural changes to the T2I model. Moreover, I2V-Adapter requires only a fraction of the parameters of conventional models and ensures compatibility with existing community-driven T2I models and controlling tools. Our experimental results demonstrate I2V-Adapter's capability to produce high-quality video outputs. This performance, coupled with its versatility and reduced need for trainable parameters, represents a substantial advancement in the field of AI-driven video generation, particularly for creative applications.
Hulk: A Universal Knowledge Translator for Human-Centric Tasks
Dec 05, 2023



Human-centric perception tasks, e.g., human mesh recovery, pedestrian detection, skeleton-based action recognition, and pose estimation, have wide industrial applications, such as metaverse and sports analysis. There is a recent surge to develop human-centric foundation models that can benefit a broad range of human-centric perception tasks. While many human-centric foundation models have achieved success, most of them only excel in 2D vision tasks or require extensive fine-tuning for practical deployment in real-world scenarios. These limitations severely restrict their usability across various downstream tasks and situations. To tackle these problems, we present Hulk, the first multimodal human-centric generalist model, capable of addressing most of the mainstream tasks simultaneously without task-specific finetuning, covering 2D vision, 3D vision, skeleton-based, and vision-language tasks. The key to achieving this is condensing various task-specific heads into two general heads, one for discrete representations, e.g., languages, and the other for continuous representations, e.g., location coordinates. The outputs of two heads can be further stacked into four distinct input and output modalities. This uniform representation enables Hulk to treat human-centric tasks as modality translation, integrating knowledge across a wide range of tasks. To validate the effectiveness of our proposed method, we conduct comprehensive experiments on 11 benchmarks across 8 human-centric tasks. Experimental results surpass previous methods substantially, demonstrating the superiority of our proposed method. The code will be available on https://github.com/OpenGVLab/HumanBench.
StableVideo: Text-driven Consistency-aware Diffusion Video Editing
Aug 18, 2023Diffusion-based methods can generate realistic images and videos, but they struggle to edit existing objects in a video while preserving their appearance over time. This prevents diffusion models from being applied to natural video editing in practical scenarios. In this paper, we tackle this problem by introducing temporal dependency to existing text-driven diffusion models, which allows them to generate consistent appearance for the edited objects. Specifically, we develop a novel inter-frame propagation mechanism for diffusion video editing, which leverages the concept of layered representations to propagate the appearance information from one frame to the next. We then build up a text-driven video editing framework based on this mechanism, namely StableVideo, which can achieve consistency-aware video editing. Extensive experiments demonstrate the strong editing capability of our approach. Compared with state-of-the-art video editing methods, our approach shows superior qualitative and quantitative results. Our code is available at \href{https://github.com/rese1f/StableVideo}{this https URL}.
MovieChat: From Dense Token to Sparse Memory for Long Video Understanding
Jul 31, 2023



Recently, integrating video foundation models and large language models to build a video understanding system overcoming the limitations of specific pre-defined vision tasks. Yet, existing systems can only handle videos with very few frames. For long videos, the computation complexity, memory cost, and long-term temporal connection are the remaining challenges. Inspired by Atkinson-Shiffrin memory model, we develop an memory mechanism including a rapidly updated short-term memory and a compact thus sustained long-term memory. We employ tokens in Transformers as the carriers of memory. MovieChat achieves state-of-the-art performace in long video understanding.
Alignment-guided Temporal Attention for Video Action Recognition
Sep 30, 2022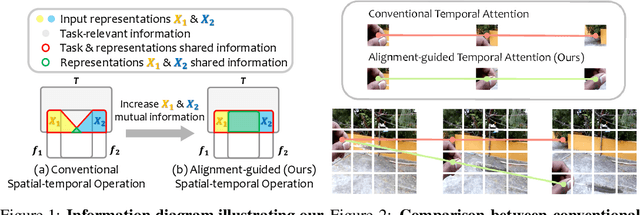
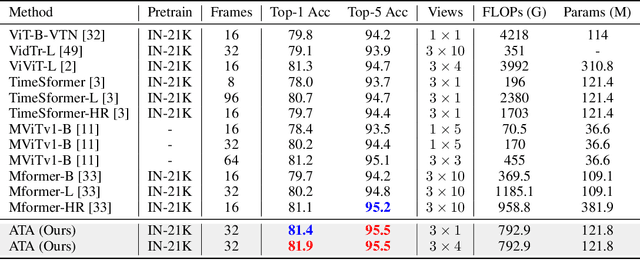
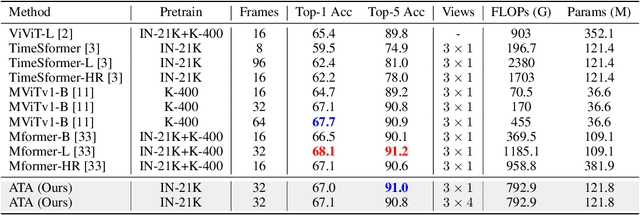
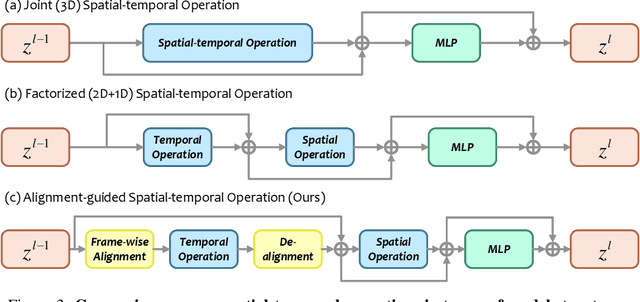
Temporal modeling is crucial for various video learning tasks. Most recent approaches employ either factorized (2D+1D) or joint (3D) spatial-temporal operations to extract temporal contexts from the input frames. While the former is more efficient in computation, the latter often obtains better performance. In this paper, we attribute this to a dilemma between the sufficiency and the efficiency of interactions among various positions in different frames. These interactions affect the extraction of task-relevant information shared among frames. To resolve this issue, we prove that frame-by-frame alignments have the potential to increase the mutual information between frame representations, thereby including more task-relevant information to boost effectiveness. Then we propose Alignment-guided Temporal Attention (ATA) to extend 1-dimensional temporal attention with parameter-free patch-level alignments between neighboring frames. It can act as a general plug-in for image backbones to conduct the action recognition task without any model-specific design. Extensive experiments on multiple benchmarks demonstrate the superiority and generality of our module.