 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhe Gan
The Elastic Lottery Ticket Hypothesis
Mar 30, 2021
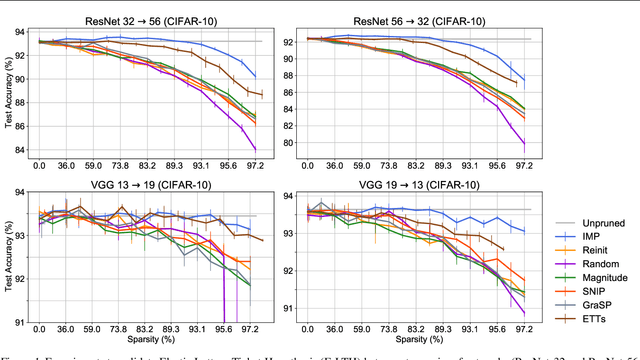
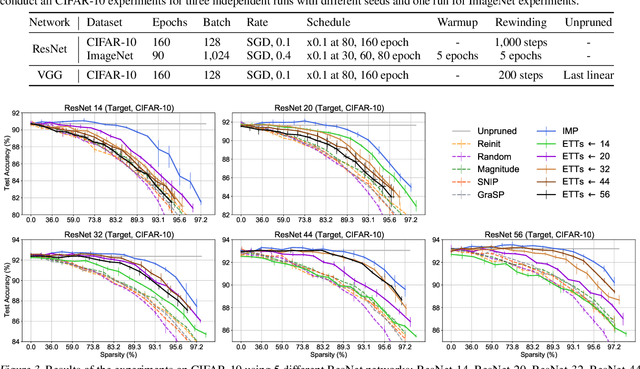
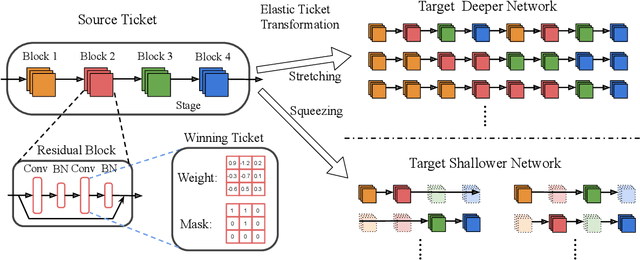
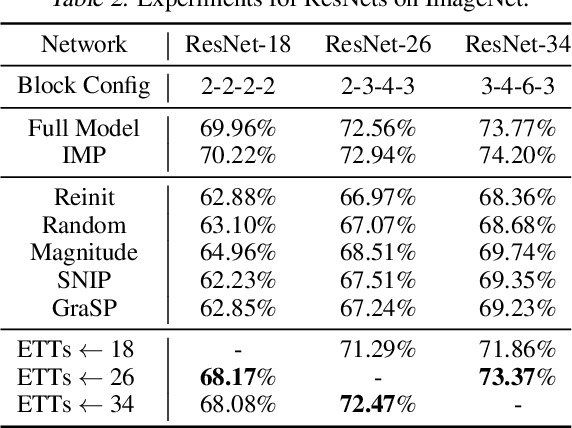
Lottery Ticket Hypothesis raises keen attention to identifying sparse trainable subnetworks or winning tickets, at the initialization (or early stage) of training, which can be trained in isolation to achieve similar or even better performance compared to the full models. Despite many efforts being made, the most effective method to identify such winning tickets is still Iterative Magnitude-based Pruning (IMP), which is computationally expensive and has to be run thoroughly for every different network. A natural question that comes in is: can we "transform" the winning ticket found in one network to another with a different architecture, yielding a winning ticket for the latter at the beginning, without re-doing the expensive IMP? Answering this question is not only practically relevant for efficient "once-for-all" winning ticket finding, but also theoretically appealing for uncovering inherently scalable sparse patterns in networks. We conduct extensive experiments on CIFAR-10 and ImageNet, and propose a variety of strategies to tweak the winning tickets found from different networks of the same model family (e.g., ResNets). Based on these results, we articulate the Elastic Lottery Ticket Hypothesis (E-LTH): by mindfully replicating (or dropping) and re-ordering layers for one network, its corresponding winning ticket could be stretched (or squeezed) into a subnetwork for another deeper (or shallower) network from the same family, whose performance is nearly as competitive as the latter's winning ticket directly found by IMP. We have also thoroughly compared E-LTH with pruning-at-initialization and dynamic sparse training methods, and discuss the generalizability of E-LTH to different model families, layer types, and even across datasets. Our codes are publicly available at https://github.com/VITA-Group/ElasticLTH.
Adversarial Feature Augmentation and Normalization for Visual Recognition
Mar 22, 2021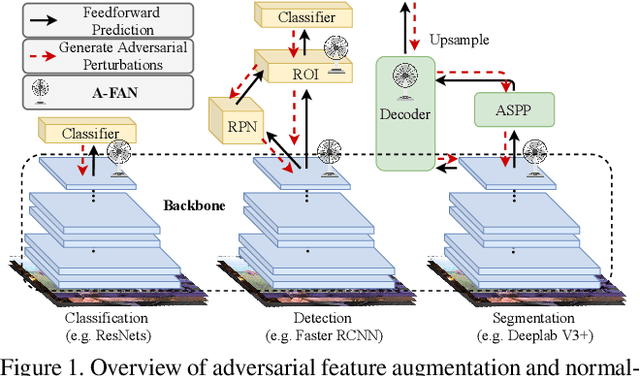
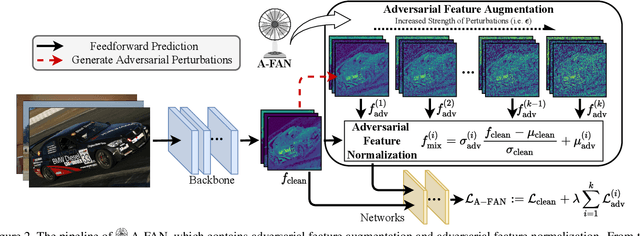

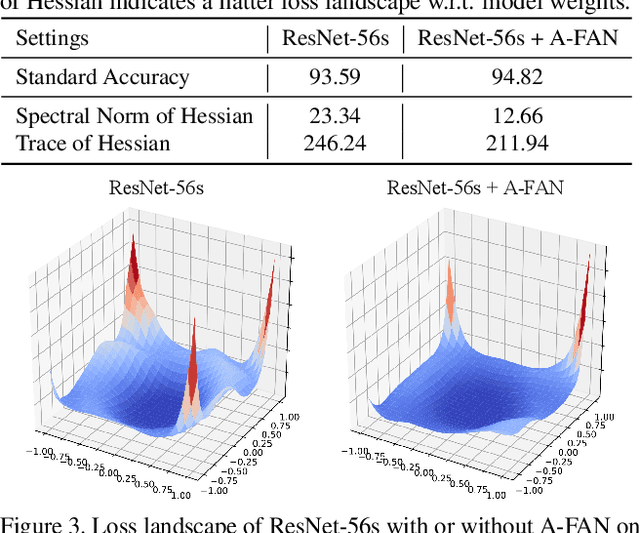
Recent advances in computer vision take advantage of adversarial data augmentation to ameliorate the generalization ability of classification models. Here, we present an effective and efficient alternative that advocates adversarial augmentation on intermediate feature embeddings, instead of relying on computationally-expensive pixel-level perturbations. We propose Adversarial Feature Augmentation and Normalization (A-FAN), which (i) first augments visual recognition models with adversarial features that integrate flexible scales of perturbation strengths, (ii) then extracts adversarial feature statistics from batch normalization, and re-injects them into clean features through feature normalization. We validate the proposed approach across diverse visual recognition tasks with representative backbone networks, including ResNets and EfficientNets for classification, Faster-RCNN for detection, and Deeplab V3+ for segmentation. Extensive experiments show that A-FAN yields consistent generalization improvement over strong baselines across various datasets for classification, detection and segmentation tasks, such as CIFAR-10, CIFAR-100, ImageNet, Pascal VOC2007, Pascal VOC2012, COCO2017, and Cityspaces. Comprehensive ablation studies and detailed analyses also demonstrate that adding perturbations to specific modules and layers of classification/detection/segmentation backbones yields optimal performance. Codes and pre-trained models will be made available at: https://github.com/VITA-Group/CV_A-FAN.
Improving Zero-shot Voice Style Transfer via Disentangled Representation Learning
Mar 17, 2021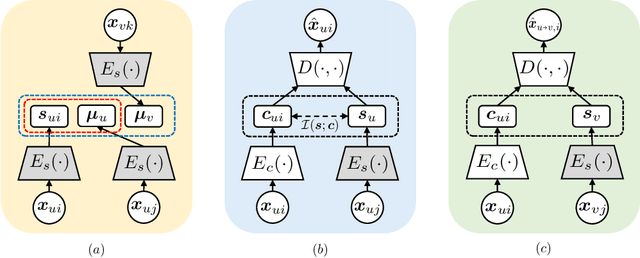


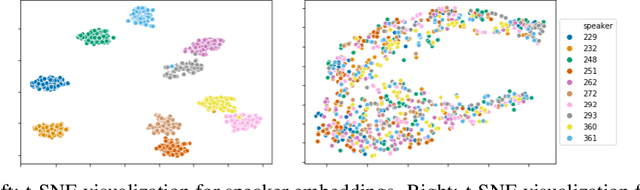
Voice style transfer, also called voice conversion, seeks to modify one speaker's voice to generate speech as if it came from another (target) speaker. Previous works have made progress on voice conversion with parallel training data and pre-known speakers. However, zero-shot voice style transfer, which learns from non-parallel data and generates voices for previously unseen speakers, remains a challenging problem. We propose a novel zero-shot voice transfer method via disentangled representation learning. The proposed method first encodes speaker-related style and voice content of each input voice into separated low-dimensional embedding spaces, and then transfers to a new voice by combining the source content embedding and target style embedding through a decoder. With information-theoretic guidance, the style and content embedding spaces are representative and (ideally) independent of each other. On real-world VCTK datasets, our method outperforms other baselines and obtains state-of-the-art results in terms of transfer accuracy and voice naturalness for voice style transfer experiments under both many-to-many and zero-shot setups.
Ultra-Data-Efficient GAN Training: Drawing A Lottery Ticket First, Then Training It Toughly
Feb 28, 2021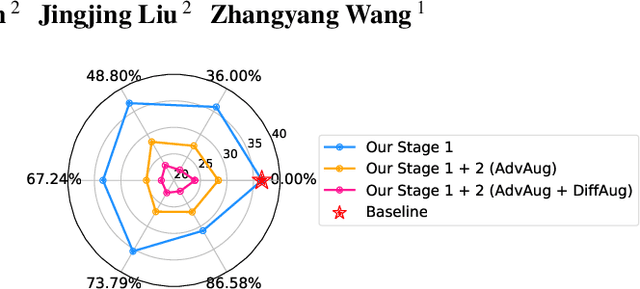
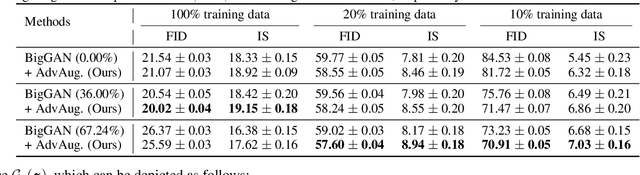
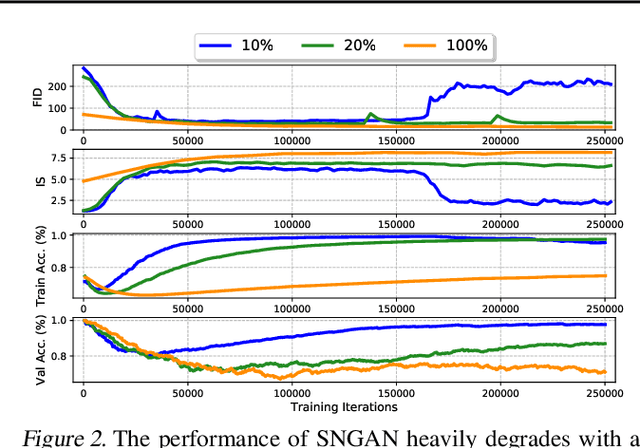
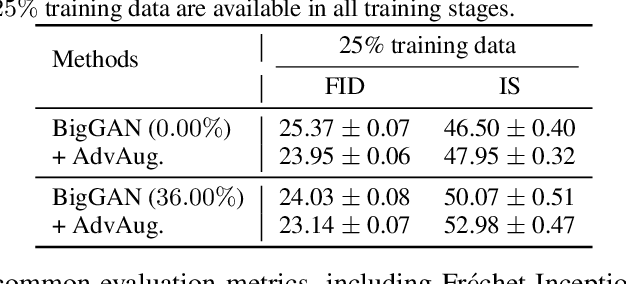
Training generative adversarial networks (GANs) with limited data generally results in deteriorated performance and collapsed models. To conquer this challenge, we are inspired by the latest observation of Kalibhat et al. (2020); Chen et al.(2021d), that one can discover independently trainable and highly sparse subnetworks (a.k.a., lottery tickets) from GANs. Treating this as an inductive prior, we decompose the data-hungry GAN training into two sequential sub-problems: (i) identifying the lottery ticket from the original GAN; then (ii) training the found sparse subnetwork with aggressive data and feature augmentations. Both sub-problems re-use the same small training set of real images. Such a coordinated framework enables us to focus on lower-complexity and more data-efficient sub-problems, effectively stabilizing training and improving convergence. Comprehensive experiments endorse the effectiveness of our proposed ultra-data-efficient training framework, across various GAN architectures (SNGAN, BigGAN, and StyleGAN2) and diverse datasets (CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet). Besides, our training framework also displays powerful few-shot generalization ability, i.e., generating high-fidelity images by training from scratch with just 100 real images, without any pre-training. Codes are available at: https://github.com/VITA-Group/Ultra-Data-Efficient-GAN-Training.
Less is More: ClipBERT for Video-and-Language Learning via Sparse Sampling
Feb 11, 2021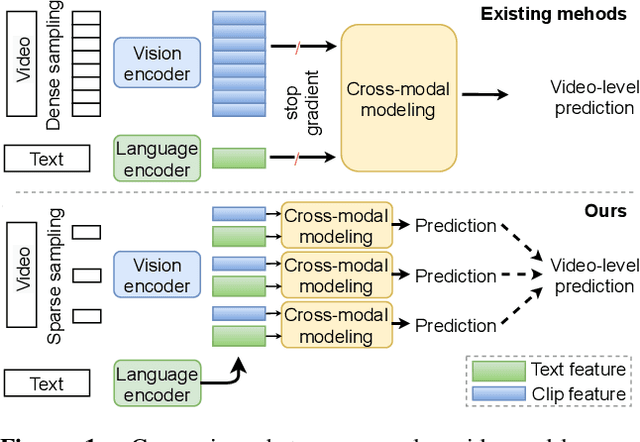
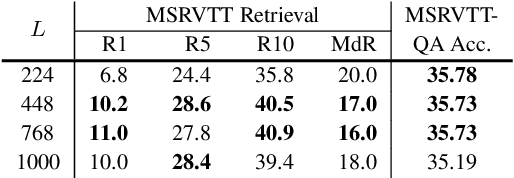
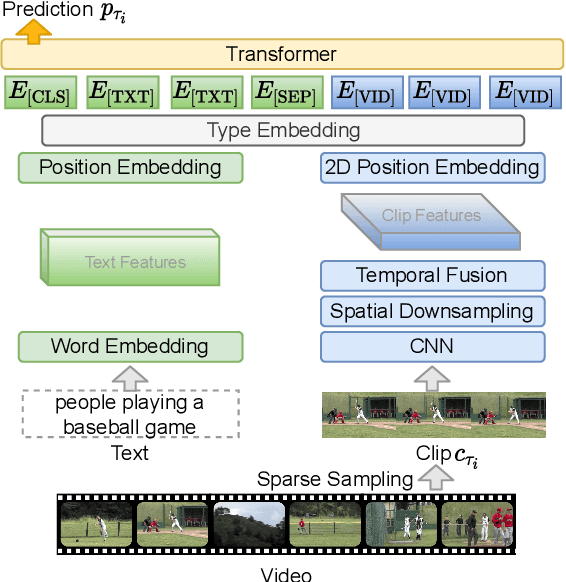
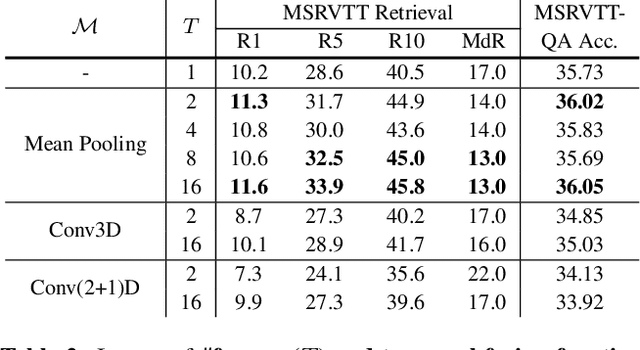
The canonical approach to video-and-language learning (e.g., video question answering) dictates a neural model to learn from offline-extracted dense video features from vision models and text features from language models. These feature extractors are trained independently and usually on tasks different from the target domains, rendering these fixed features sub-optimal for downstream tasks. Moreover, due to the high computational overload of dense video features, it is often difficult (or infeasible) to plug feature extractors directly into existing approaches for easy finetuning. To provide a remedy to this dilemma, we propose a generic framework ClipBERT that enables affordable end-to-end learning for video-and-language tasks, by employing sparse sampling, where only a single or a few sparsely sampled short clips from a video are used at each training step. Experiments on text-to-video retrieval and video question answering on six datasets demonstrate that ClipBERT outperforms (or is on par with) existing methods that exploit full-length videos, suggesting that end-to-end learning with just a few sparsely sampled clips is often more accurate than using densely extracted offline features from full-length videos, proving the proverbial less-is-more principle. Videos in the datasets are from considerably different domains and lengths, ranging from 3-second generic domain GIF videos to 180-second YouTube human activity videos, showing the generalization ability of our approach. Comprehensive ablation studies and thorough analyses are provided to dissect what factors lead to this success. Our code is publicly available at https://github.com/jayleicn/ClipBERT
EarlyBERT: Efficient BERT Training via Early-bird Lottery Tickets
Dec 31, 2020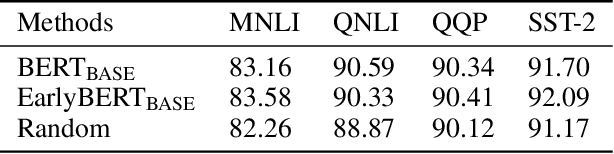
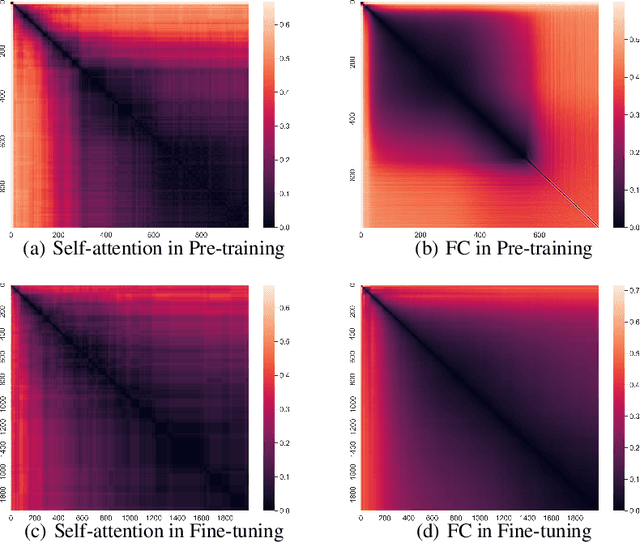
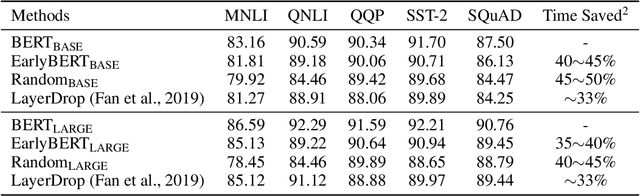
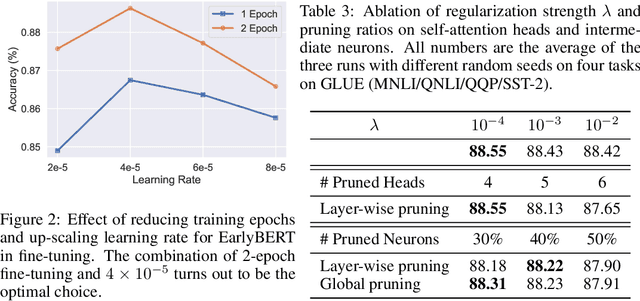
Deep, heavily overparameterized language models such as BERT, XLNet and T5 have achieved impressive success in many NLP tasks. However, their high model complexity requires enormous computation resources and extremely long training time for both pre-training and fine-tuning. Many works have studied model compression on large NLP models, but only focus on reducing inference cost/time, while still requiring expensive training process. Other works use extremely large batch sizes to shorten the pre-training time at the expense of high demand for computation resources. In this paper, inspired by the Early-Bird Lottery Tickets studied for computer vision tasks, we propose EarlyBERT, a general computationally-efficient training algorithm applicable to both pre-training and fine-tuning of large-scale language models. We are the first to identify structured winning tickets in the early stage of BERT training, and use them for efficient training. Comprehensive pre-training and fine-tuning experiments on GLUE and SQuAD downstream tasks show that EarlyBERT easily achieves comparable performance to standard BERT with 35~45% less training time.
Wasserstein Contrastive Representation Distillation
Dec 15, 2020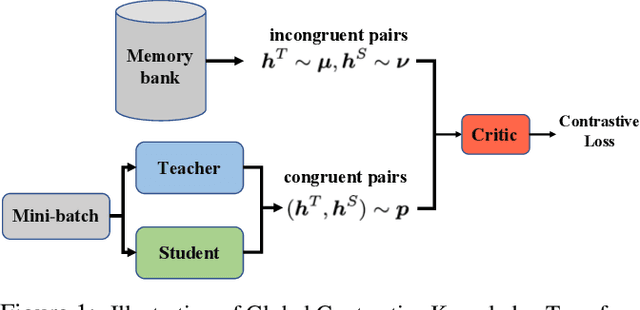
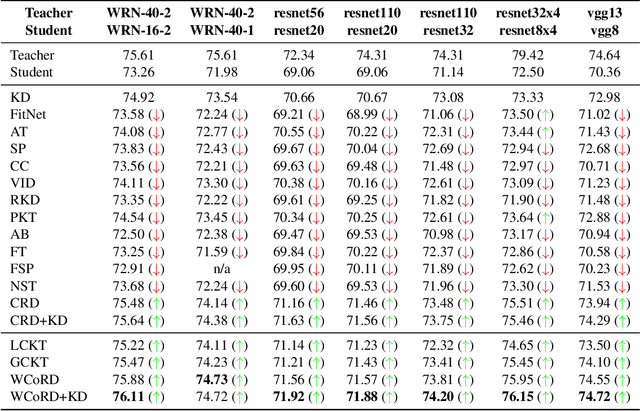
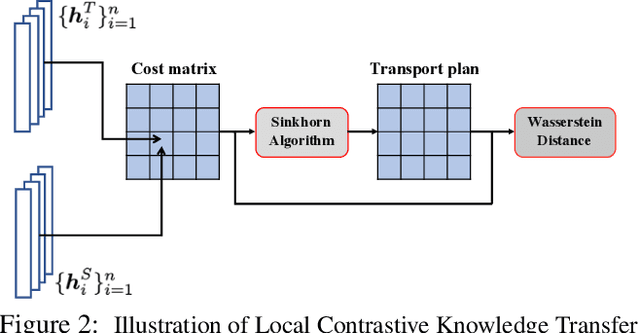

The primary goal of knowledge distillation (KD) is to encapsulate the information of a model learned from a teacher network into a student network, with the latter being more compact than the former. Existing work, e.g., using Kullback-Leibler divergence for distillation, may fail to capture important structural knowledge in the teacher network and often lacks the ability for feature generalization, particularly in situations when teacher and student are built to address different classification tasks. We propose Wasserstein Contrastive Representation Distillation (WCoRD), which leverages both primal and dual forms of Wasserstein distance for KD. The dual form is used for global knowledge transfer, yielding a contrastive learning objective that maximizes the lower bound of mutual information between the teacher and the student networks. The primal form is used for local contrastive knowledge transfer within a mini-batch, effectively matching the distributions of features between the teacher and the student networks. Experiments demonstrate that the proposed WCoRD method outperforms state-of-the-art approaches on privileged information distillation, model compression and cross-modal transfer.
A Closer Look at the Robustness of Vision-and-Language Pre-trained Models
Dec 15, 2020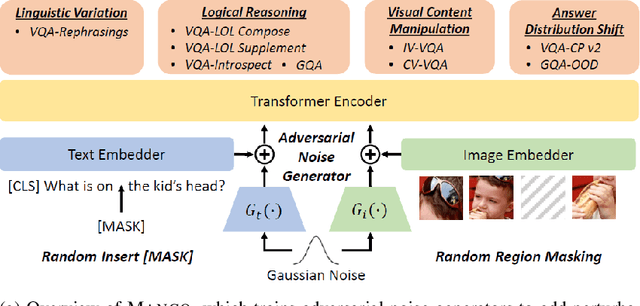
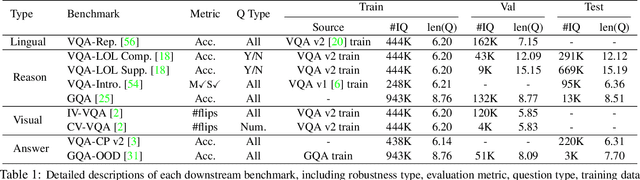
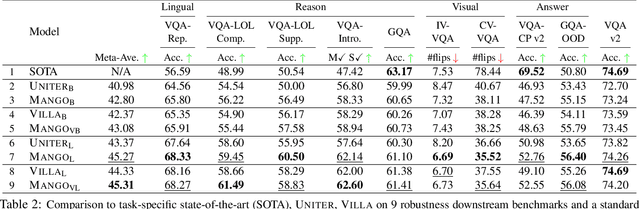

Large-scale pre-trained multimodal transformers, such as ViLBERT and UNITER, have propelled the state of the art in vision-and-language (V+L) research to a new level. Although achieving impressive performance on standard tasks, to date, it still remains unclear how robust these pre-trained models are. To investigate, we conduct a host of thorough evaluations on existing pre-trained models over 4 different types of V+L specific model robustness: (i) Linguistic Variation; (ii) Logical Reasoning; (iii) Visual Content Manipulation; and (iv) Answer Distribution Shift. Interestingly, by standard model finetuning, pre-trained V+L models already exhibit better robustness than many task-specific state-of-the-art methods. To further enhance model robustness, we propose Mango, a generic and efficient approach that learns a Multimodal Adversarial Noise GeneratOr in the embedding space to fool pre-trained V+L models. Differing from previous studies focused on one specific type of robustness, Mango is task-agnostic, and enables universal performance lift for pre-trained models over diverse tasks designed to evaluate broad aspects of robustness. Comprehensive experiments demonstrate that Mango achieves new state of the art on 7 out of 9 robustness benchmarks, surpassing existing methods by a significant margin. As the first comprehensive study on V+L robustness, this work puts robustness of pre-trained models into sharper focus, pointing new directions for future study.
InfoBERT: Improving Robustness of Language Models from An Information Theoretic Perspective
Oct 14, 2020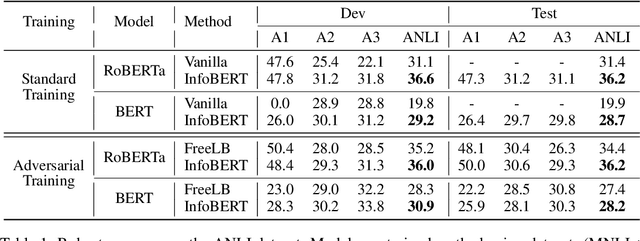
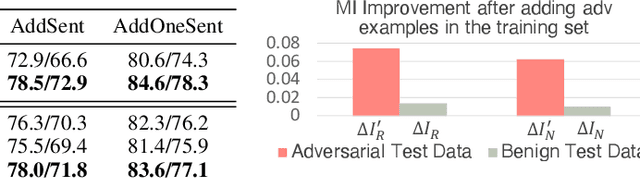
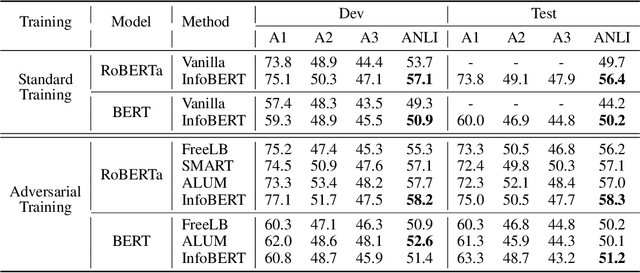
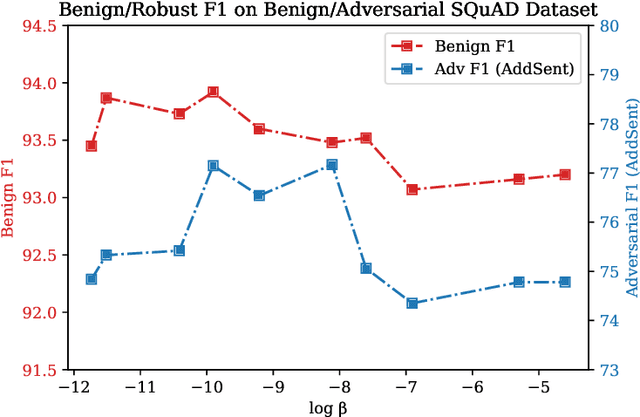
Large-scale language models such as BERT have achieved state-of-the-art performance across a wide range of NLP tasks. Recent studies, however, show that such BERT-based models are vulnerable facing the threats of textual adversarial attacks. We aim to address this problem from an information-theoretic perspective, and propose InfoBERT, a novel learning framework for robust fine-tuning of pre-trained language models. InfoBERT contains two mutual-information-based regularizers for model training: (i) an Information Bottleneck regularizer, which suppresses noisy mutual information between the input and the feature representation; and (ii) a Robust Feature regularizer, which increases the mutual information between local robust features and global features. We provide a principled way to theoretically analyze and improve the robustness of representation learning for language models in both standard and adversarial training. Extensive experiments demonstrate that InfoBERT achieves state-of-the-art robust accuracy over several adversarial datasets on Natural Language Inference (NLI) and Question Answering (QA) tasks.
Cross-Thought for Sentence Encoder Pre-training
Oct 07, 2020
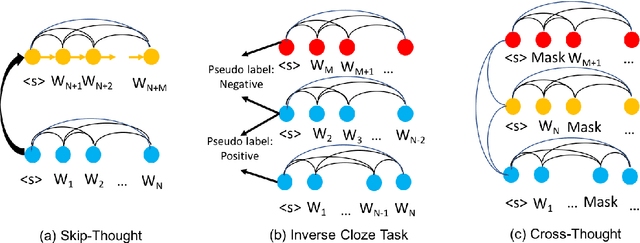
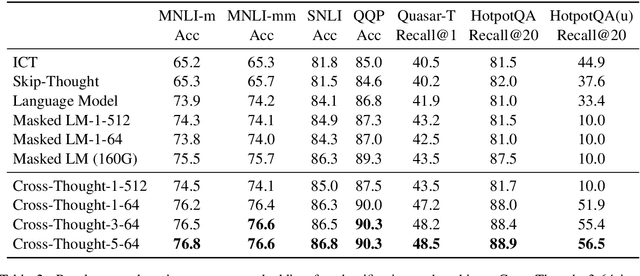
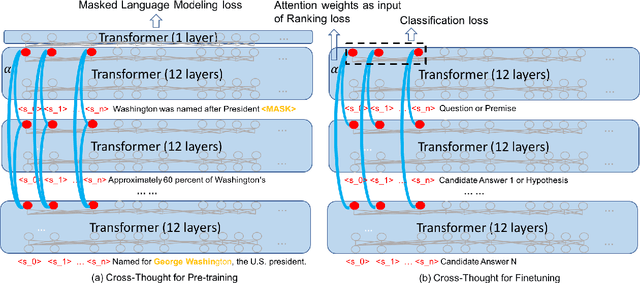
In this paper, we propose Cross-Thought, a novel approach to pre-training sequence encoder, which is instrumental in building reusable sequence embeddings for large-scale NLP tasks such as question answering. Instead of using the original signals of full sentences, we train a Transformer-based sequence encoder over a large set of short sequences, which allows the model to automatically select the most useful information for predicting masked words. Experiments on question answering and textual entailment tasks demonstrate that our pre-trained encoder can outperform state-of-the-art encoders trained with continuous sentence signals as well as traditional masked language modeling baselines. Our proposed approach also achieves new state of the art on HotpotQA (full-wiki setting) by improving intermediate information retrieval performance.