 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikingMoE: SDPrompt-Guided Dynamic Expert Fusion in Spiking Neural Networks
May 22, 2026Spiking Neural Networks (SNNs) provide an energy-efficient paradigm for visual recognition. We present SpikingMoE, which integrates a spike-driven Transformer with a Mixture-of-Experts (MoE) framework for dynamic computation. Inspired by the lateral geniculate nucleus (LGN), a spike-driven prompt (SDprompt) enables input-dependent expert routing in a biologically plausible manner. By replacing standard MLPs with spike-compatible expert modules and enforcing binary spike communication, SpikingMoE is designed for neuromorphic hardware. Experiments on CIFAR-10 and CIFAR-100 achieve 94.09% and 74.54% top-1 accuracy, showing that modular expert routing can be incorporated while retaining reasonable performance. To our knowledge, SpikingMoE is the first open-source SNN framework that integrates MoE into a spike-driven Transformer with LGN-inspired routing.
OOM-RL: Out-of-Money Reinforcement Learning Market-Driven Alignment for LLM-Based Multi-Agent Systems
Apr 13, 2026The alignment of Multi-Agent Systems (MAS) for autonomous software engineering is constrained by evaluator epistemic uncertainty. Current paradigms, such as Reinforcement Learning from Human Feedback (RLHF) and AI Feedback (RLAIF), frequently induce model sycophancy, while execution-based environments suffer from adversarial "Test Evasion" by unconstrained agents. In this paper, we introduce an objective alignment paradigm: \textbf{Out-of-Money Reinforcement Learning (OOM-RL)}. By deploying agents into the non-stationary, high-friction reality of live financial markets, we utilize critical capital depletion as an un-hackable negative gradient. Our longitudinal 20-month empirical study (July 2024 -- February 2026) chronicles the system's evolution from a high-turnover, sycophantic baseline to a robust, liquidity-aware architecture. We demonstrate that the undeniable ontological consequences of financial loss forced the MAS to abandon overfitted hallucinations in favor of the \textbf{Strict Test-Driven Agentic Workflow (STDAW)}, which enforces a Byzantine-inspired uni-directional state lock (RO-Lock) anchored to a deterministically verified $\geq 95\%$ code coverage constraint matrix. Our results show that while early iterations suffered severe execution decay, the final OOM-RL-aligned system achieved a stable equilibrium with an annualized Sharpe ratio of 2.06 in its mature phase. We conclude that substituting subjective human preference with rigorous economic penalties provides a robust methodology for aligning autonomous agents in high-stakes, real-world environments, laying the groundwork for generalized paradigms where computational billing acts as an objective physical constraint
AICA-Bench: Holistically Examining the Capabilities of VLMs in Affective Image Content Analysis
Apr 07, 2026Vision-Language Models (VLMs) have demonstrated strong capabilities in perception, yet holistic Affective Image Content Analysis (AICA), which integrates perception, reasoning, and generation into a unified framework, remains underexplored. To address this gap, we introduce AICA-Bench, a comprehensive benchmark with three core tasks: Emotion Understanding (EU), Emotion Reasoning (ER), and Emotion-Guided Content Generation (EGCG). We evaluate 23 VLMs and identify two major limitations: weak intensity calibration and shallow open-ended descriptions. To address these issues, we propose Grounded Affective Tree (GAT) Prompting, a training-free framework that combines visual scaffolding with hierarchical reasoning. Experiments show that GAT reduces intensity errors and improves descriptive depth, providing a strong baseline for future research on affective multimodal understanding and generation.
Sequences as Nodes for Contrastive Multimodal Graph Recommendation
Feb 06, 2026To tackle cold-start and data sparsity issues in recommender systems, numerous multimodal, sequential, and contrastive techniques have been proposed. While these augmentations can boost recommendation performance, they tend to add noise and disrupt useful semantics. To address this, we propose MuSICRec (Multimodal Sequence-Item Contrastive Recommender), a multi-view graph-based recommender that combines collaborative, sequential, and multimodal signals. We build a sequence-item (SI) view by attention pooling over the user's interacted items to form sequence nodes. We propagate over the SI graph, obtaining a second view organically as an alternative to artificial data augmentation, while simultaneously injecting sequential context signals. Additionally, to mitigate modality noise and align the multimodal information, the contribution of text and visual features is modulated according to an ID-guided gate. We evaluate under a strict leave-two-out split against a broad range of sequential, multimodal, and contrastive baselines. On the Amazon Baby, Sports, and Electronics datasets, MuSICRec outperforms state-of-the-art baselines across all model types. We observe the largest gains for short-history users, mitigating sparsity and cold-start challenges. Our code is available at https://anonymous.4open.science/r/MuSICRec-3CEE/ and will be made publicly available.
DSL: Understanding and Improving Softmax Recommender Systems with Competition-Aware Scaling
Feb 06, 2026Softmax Loss (SL) is being increasingly adopted for recommender systems (RS) as it has demonstrated better performance, robustness and fairness. Yet in implicit-feedback, a single global temperature and equal treatment of uniformly sampled negatives can lead to brittle training, because sampled sets may contain varying degrees of relevant or informative competitors. The optimal loss sharpness for a user-item pair with a particular set of negatives, can be suboptimal or destabilising for another with different negatives. We introduce Dual-scale Softmax Loss (DSL), which infers effective sharpness from the sampled competition itself. DSL adds two complementary branches to the log-sum-exp backbone. Firstly it reweights negatives within each training instance using hardness and item--item similarity, secondly it adapts a per-example temperature from the competition intensity over a constructed competitor slate. Together, these components preserve the geometry of SL while reshaping the competition distribution across negatives and across examples. Over several representative benchmarks and backbones, DSL yields substantial gains over strong baselines, with improvements over SL exceeding $10%$ in several settings and averaging $6.22%$ across datasets, metrics, and backbones. Under out-of-distribution (OOD) popularity shift, the gains are larger, with an average of $9.31%$ improvement over SL. We further provide a theoretical, distributionally robust optimisation (DRO) analysis, which demonstrates how DSL reshapes the robust payoff and the KL deviation for ambiguous instances. This helps explain the empirically observed improvements in accuracy and robustness.
Multimodal Enhancement of Sequential Recommendation
Feb 06, 2026We propose a novel recommender framework, MuSTRec (Multimodal and Sequential Transformer-based Recommendation), that unifies multimodal and sequential recommendation paradigms. MuSTRec captures cross-item similarities and collaborative filtering signals, by building item-item graphs from extracted text and visual features. A frequency-based self-attention module additionally captures the short- and long-term user preferences. Across multiple Amazon datasets, MuSTRec demonstrates superior performance (up to 33.5% improvement) over multimodal and sequential state-of-the-art baselines. Finally, we detail some interesting facets of this new recommendation paradigm. These include the need for a new data partitioning regime, and a demonstration of how integrating user embeddings into sequential recommendation leads to drastically increased short-term metrics (up to 200% improvement) on smaller datasets. Our code is availabe at https://anonymous.4open.science/r/MuSTRec-D32B/ and will be made publicly available.
Melodia: Training-Free Music Editing Guided by Attention Probing in Diffusion Models
Nov 18, 2025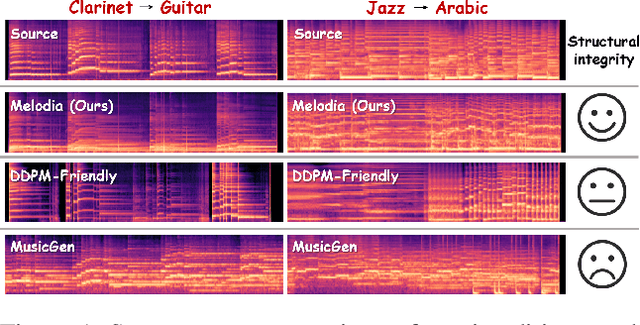
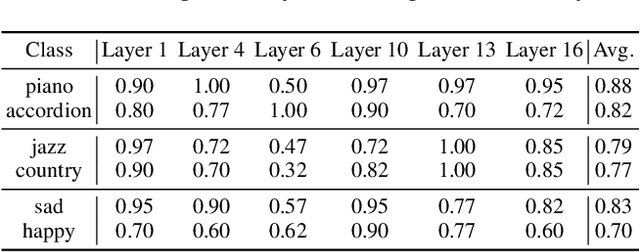
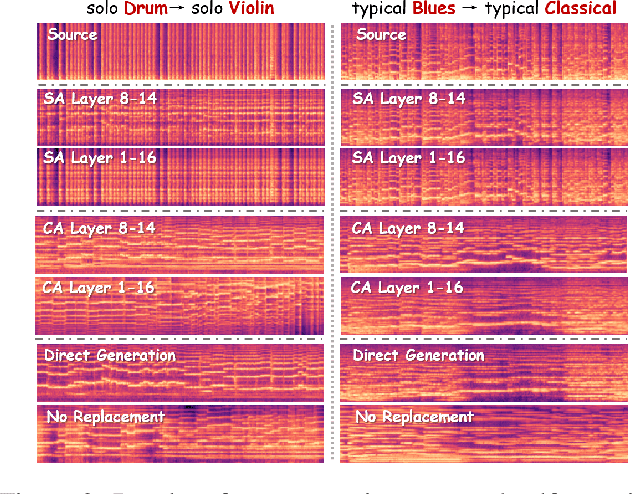
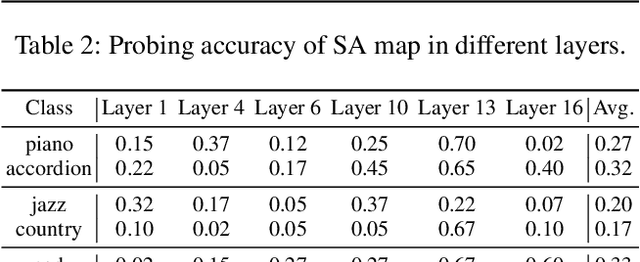
Text-to-music generation technology is progressing rapidly, creating new opportunities for musical composition and editing. However, existing music editing methods often fail to preserve the source music's temporal structure, including melody and rhythm, when altering particular attributes like instrument, genre, and mood. To address this challenge, this paper conducts an in-depth probing analysis on attention maps within AudioLDM 2, a diffusion-based model commonly used as the backbone for existing music editing methods. We reveal a key finding: cross-attention maps encompass details regarding distinct musical characteristics, and interventions on these maps frequently result in ineffective modifications. In contrast, self-attention maps are essential for preserving the temporal structure of the source music during its conversion into the target music. Building upon this understanding, we present Melodia, a training-free technique that selectively manipulates self-attention maps in particular layers during the denoising process and leverages an attention repository to store source music information, achieving accurate modification of musical characteristics while preserving the original structure without requiring textual descriptions of the source music. Additionally, we propose two novel metrics to better evaluate music editing methods. Both objective and subjective experiments demonstrate that our approach achieves superior results in terms of textual adherence and structural integrity across various datasets. This research enhances comprehension of internal mechanisms within music generation models and provides improved control for music creation.
A Physics-Informed Blur Learning Framework for Imaging Systems
Feb 17, 2025Accurate blur estimation is essential for high-performance imaging across various applications. Blur is typically represented by the point spread function (PSF). In this paper, we propose a physics-informed PSF learning framework for imaging systems, consisting of a simple calibration followed by a learning process. Our framework could achieve both high accuracy and universal applicability. Inspired by the Seidel PSF model for representing spatially varying PSF, we identify its limitations in optimization and introduce a novel wavefront-based PSF model accompanied by an optimization strategy, both reducing optimization complexity and improving estimation accuracy. Moreover, our wavefront-based PSF model is independent of lens parameters, eliminate the need for prior knowledge of the lens. To validate our approach, we compare it with recent PSF estimation methods (Degradation Transfer and Fast Two-step) through a deblurring task, where all the estimated PSFs are used to train state-of-the-art deblurring algorithms. Our approach demonstrates improvements in image quality in simulation and also showcases noticeable visual quality improvements on real captured images.
Tolerance-Aware Deep Optics
Feb 07, 2025



Deep optics has emerged as a promising approach by co-designing optical elements with deep learning algorithms. However, current research typically overlooks the analysis and optimization of manufacturing and assembly tolerances. This oversight creates a significant performance gap between designed and fabricated optical systems. To address this challenge, we present the first end-to-end tolerance-aware optimization framework that incorporates multiple tolerance types into the deep optics design pipeline. Our method combines physics-informed modelling with data-driven training to enhance optical design by accounting for and compensating for structural deviations in manufacturing and assembly. We validate our approach through computational imaging applications, demonstrating results in both simulations and real-world experiments. We further examine how our proposed solution improves the robustness of optical systems and vision algorithms against tolerances through qualitative and quantitative analyses. Code and additional visual results are available at openimaginglab.github.io/LensTolerance.
DriveEditor: A Unified 3D Information-Guided Framework for Controllable Object Editing in Driving Scenes
Dec 27, 2024



Vision-centric autonomous driving systems require diverse data for robust training and evaluation, which can be augmented by manipulating object positions and appearances within existing scene captures. While recent advancements in diffusion models have shown promise in video editing, their application to object manipulation in driving scenarios remains challenging due to imprecise positional control and difficulties in preserving high-fidelity object appearances. To address these challenges in position and appearance control, we introduce DriveEditor, a diffusion-based framework for object editing in driving videos. DriveEditor offers a unified framework for comprehensive object editing operations, including repositioning, replacement, deletion, and insertion. These diverse manipulations are all achieved through a shared set of varying inputs, processed by identical position control and appearance maintenance modules. The position control module projects the given 3D bounding box while preserving depth information and hierarchically injects it into the diffusion process, enabling precise control over object position and orientation. The appearance maintenance module preserves consistent attributes with a single reference image by employing a three-tiered approach: low-level detail preservation, high-level semantic maintenance, and the integration of 3D priors from a novel view synthesis model. Extensive qualitative and quantitative evaluations on the nuScenes dataset demonstrate DriveEditor's exceptional fidelity and controllability in generating diverse driving scene edits, as well as its remarkable ability to facilitate downstream tasks.