 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Apr 22, 2024Large language models (LLMs) excel in most NLP tasks but also require expensive cloud servers for deployment due to their size, while smaller models that can be deployed on lower cost (e.g., edge) devices, tend to lag behind in terms of response quality. Therefore in this work we propose a hybrid inference approach which combines their respective strengths to save cost and maintain quality. Our approach uses a router that assigns queries to the small or large model based on the predicted query difficulty and the desired quality level. The desired quality level can be tuned dynamically at test time to seamlessly trade quality for cost as per the scenario requirements. In experiments our approach allows us to make up to 40% fewer calls to the large model, with no drop in response quality.
Sweeping Heterogeneity with Smart MoPs: Mixture of Prompts for LLM Task Adaptation
Oct 05, 2023



Large Language Models (LLMs) have the ability to solve a variety of tasks, such as text summarization and mathematical questions, just out of the box, but they are often trained with a single task in mind. Due to high computational costs, the current trend is to use prompt instruction tuning to better adjust monolithic, pretrained LLMs for new -- but often individual -- downstream tasks. Thus, how one would expand prompt tuning to handle -- concomitantly -- heterogeneous tasks and data distributions is a widely open question. To address this gap, we suggest the use of \emph{Mixture of Prompts}, or MoPs, associated with smart gating functionality: the latter -- whose design is one of the contributions of this paper -- can identify relevant skills embedded in different groups of prompts and dynamically assign combined experts (i.e., collection of prompts), based on the target task. Additionally, MoPs are empirically agnostic to any model compression technique applied -- for efficiency reasons -- as well as instruction data source and task composition. In practice, MoPs can simultaneously mitigate prompt training "interference" in multi-task, multi-source scenarios (e.g., task and data heterogeneity across sources), as well as possible implications from model approximations. As a highlight, MoPs manage to decrease final perplexity from $\sim20\%$ up to $\sim70\%$, as compared to baselines, in the federated scenario, and from $\sim 3\%$ up to $\sim30\%$ in the centralized scenario.
Contrastive Post-training Large Language Models on Data Curriculum
Oct 03, 2023



Alignment serves as an important step to steer large language models (LLMs) towards human preferences. In this paper, we explore contrastive post-training techniques for alignment by automatically constructing preference pairs from multiple models of varying strengths (e.g., InstructGPT, ChatGPT and GPT-4). We carefully compare the contrastive techniques of SLiC and DPO to SFT baselines and find that DPO provides a step-function improvement even after continueing SFT saturates. We also explore a data curriculum learning scheme for contrastive post-training, which starts by learning from "easier" pairs and transitioning to "harder" ones, which further improves alignment. Finally, we scale up our experiments to train with more data and larger models like Orca. Remarkably, contrastive post-training further improves the performance of Orca, already a state-of-the-art instruction learning model tuned with GPT-4 outputs, to exceed that of ChatGPT.
Fed-ZERO: Efficient Zero-shot Personalization with Federated Mixture of Experts
Jun 14, 2023



One of the goals in Federated Learning (FL) is to create personalized models that can adapt to the context of each participating client, while utilizing knowledge from a shared global model. Yet, often, personalization requires a fine-tuning step using clients' labeled data in order to achieve good performance. This may not be feasible in scenarios where incoming clients are fresh and/or have privacy concerns. It, then, remains open how one can achieve zero-shot personalization in these scenarios. We propose a novel solution by using a Mixture-of-Experts (MoE) framework within a FL setup. Our method leverages the diversity of the clients to train specialized experts on different subsets of classes, and a gating function to route the input to the most relevant expert(s). Our gating function harnesses the knowledge of a pretrained model common expert to enhance its routing decisions on-the-fly. As a highlight, our approach can improve accuracy up to 18\% in state of the art FL settings, while maintaining competitive zero-shot performance. In practice, our method can handle non-homogeneous data distributions, scale more efficiently, and improve the state-of-the-art performance on common FL benchmarks.
GRILL: Grounded Vision-language Pre-training via Aligning Text and Image Regions
May 24, 2023



Generalization to unseen tasks is an important ability for few-shot learners to achieve better zero-/few-shot performance on diverse tasks. However, such generalization to vision-language tasks including grounding and generation tasks has been under-explored; existing few-shot VL models struggle to handle tasks that involve object grounding and multiple images such as visual commonsense reasoning or NLVR2. In this paper, we introduce GRILL, GRounded vIsion Language aLigning, a novel VL model that can be generalized to diverse tasks including visual question answering, captioning, and grounding tasks with no or very few training instances. Specifically, GRILL learns object grounding and localization by exploiting object-text alignments, which enables it to transfer to grounding tasks in a zero-/few-shot fashion. We evaluate our model on various zero-/few-shot VL tasks and show that it consistently surpasses the state-of-the-art few-shot methods.
Improving Grounded Language Understanding in a Collaborative Environment by Interacting with Agents Through Help Feedback
Apr 21, 2023



Many approaches to Natural Language Processing (NLP) tasks often treat them as single-step problems, where an agent receives an instruction, executes it, and is evaluated based on the final outcome. However, human language is inherently interactive, as evidenced by the back-and-forth nature of human conversations. In light of this, we posit that human-AI collaboration should also be interactive, with humans monitoring the work of AI agents and providing feedback that the agent can understand and utilize. Further, the AI agent should be able to detect when it needs additional information and proactively ask for help. Enabling this scenario would lead to more natural, efficient, and engaging human-AI collaborations. In this work, we explore these directions using the challenging task defined by the IGLU competition, an interactive grounded language understanding task in a MineCraft-like world. We explore multiple types of help players can give to the AI to guide it and analyze the impact of this help in AI behavior, resulting in performance improvements.
An Empirical Study of Metrics to Measure Representational Harms in Pre-Trained Language Models
Jan 22, 2023



Large-scale Pre-Trained Language Models (PTLMs) capture knowledge from massive human-written data which contains latent societal biases and toxic contents. In this paper, we leverage the primary task of PTLMs, i.e., language modeling, and propose a new metric to quantify manifested implicit representational harms in PTLMs towards 13 marginalized demographics. Using this metric, we conducted an empirical analysis of 24 widely used PTLMs. Our analysis provides insights into the correlation between the proposed metric in this work and other related metrics for representational harm. We observe that our metric correlates with most of the gender-specific metrics in the literature. Through extensive experiments, we explore the connections between PTLMs architectures and representational harms across two dimensions: depth and width of the networks. We found that prioritizing depth over width, mitigates representational harms in some PTLMs. Our code and data can be found at https://github.com/microsoft/SafeNLP.
AdaMix: Mixture-of-Adaptations for Parameter-efficient Model Tuning
Nov 02, 2022



Standard fine-tuning of large pre-trained language models (PLMs) for downstream tasks requires updating hundreds of millions to billions of parameters, and storing a large copy of the PLM weights for every task resulting in increased cost for storing, sharing and serving the models. To address this, parameter-efficient fine-tuning (PEFT) techniques were introduced where small trainable components are injected in the PLM and updated during fine-tuning. We propose AdaMix as a general PEFT method that tunes a mixture of adaptation modules -- given the underlying PEFT method of choice -- introduced in each Transformer layer while keeping most of the PLM weights frozen. For instance, AdaMix can leverage a mixture of adapters like Houlsby or a mixture of low rank decomposition matrices like LoRA to improve downstream task performance over the corresponding PEFT methods for fully supervised and few-shot NLU and NLG tasks. Further, we design AdaMix such that it matches the same computational cost and the number of tunable parameters as the underlying PEFT method. By only tuning 0.1-0.2% of PLM parameters, we show that AdaMix outperforms SOTA parameter-efficient fine-tuning and full model fine-tuning for both NLU and NLG tasks.
AutoMoE: Neural Architecture Search for Efficient Sparsely Activated Transformers
Oct 14, 2022
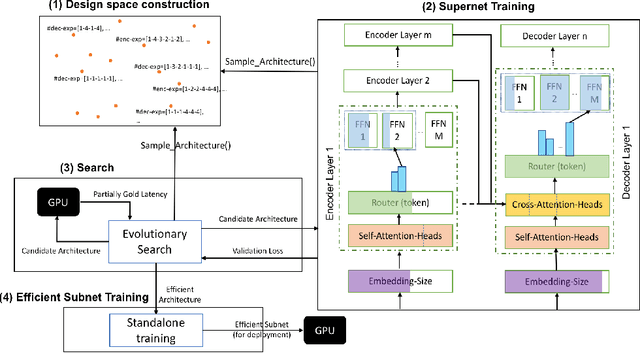


Neural architecture search (NAS) has demonstrated promising results on identifying efficient Transformer architectures which outperform manually designed ones for natural language tasks like neural machine translation (NMT). Existing NAS methods operate on a space of dense architectures, where all of the sub-architecture weights are activated for every input. Motivated by the recent advances in sparsely activated models like the Mixture-of-Experts (MoE) model, we introduce sparse architectures with conditional computation into the NAS search space. Given this expressive search space which subsumes prior densely activated architectures, we develop a new framework AutoMoE to search for efficient sparsely activated sub-Transformers. AutoMoE-generated sparse models obtain (i) 3x FLOPs reduction over manually designed dense Transformers and (ii) 23% FLOPs reduction over state-of-the-art NAS-generated dense sub-Transformers with parity in BLEU score on benchmark datasets for NMT. AutoMoE consists of three training phases: (a) Heterogeneous search space design with dense and sparsely activated Transformer modules (e.g., how many experts? where to place them? what should be their sizes?); (b) SuperNet training that jointly trains several subnetworks sampled from the large search space by weight-sharing; (c) Evolutionary search for the architecture with the optimal trade-off between task performance and computational constraint like FLOPs and latency. AutoMoE code, data and trained models are available at https://github.com/microsoft/AutoMoE.
AdaMix: Mixture-of-Adapter for Parameter-efficient Tuning of Large Language Models
May 24, 2022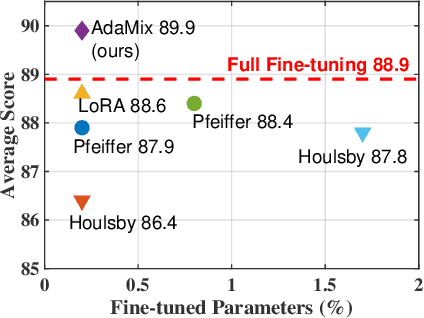
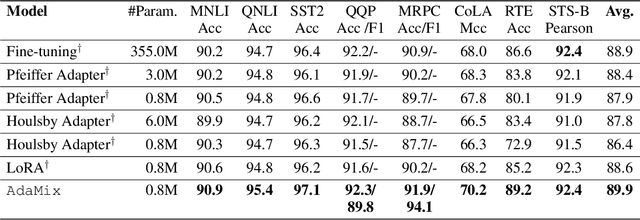
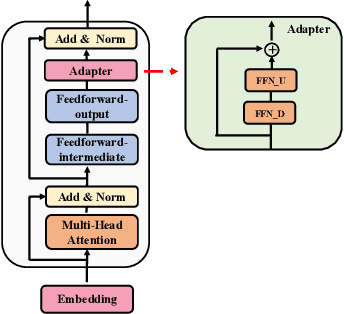
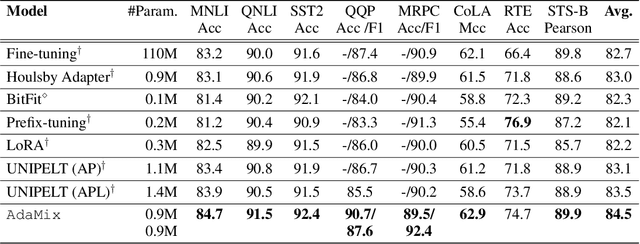
Fine-tuning large-scale pre-trained language models to downstream tasks require updating hundreds of millions of parameters. This not only increases the serving cost to store a large copy of the model weights for every task, but also exhibits instability during few-shot task adaptation. Parameter-efficient techniques have been developed that tune small trainable components (e.g., adapters) injected in the large model while keeping most of the model weights frozen. The prevalent mechanism to increase adapter capacity is to increase the bottleneck dimension which increases the adapter parameters. In this work, we introduce a new mechanism to improve adapter capacity without increasing parameters or computational cost by two key techniques. (i) We introduce multiple shared adapter components in each layer of the Transformer architecture. We leverage sparse learning via random routing to update the adapter parameters (encoder is kept frozen) resulting in the same amount of computational cost (FLOPs) as that of training a single adapter. (ii) We propose a simple merging mechanism to average the weights of multiple adapter components to collapse to a single adapter in each Transformer layer, thereby, keeping the overall parameters also the same but with significant performance improvement. We demonstrate these techniques to work well across multiple task settings including fully supervised and few-shot Natural Language Understanding tasks. By only tuning 0.23% of a pre-trained language model's parameters, our model outperforms the full model fine-tuning performance and several competing methods.