 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Topology and Deep Representation Learning: A TDA-ViT Fusion Model for Four-Class Brain Tumor Classification
May 30, 2026Accurate brain tumor classification from magnetic resonance imaging (MRI) is a key requirement for early diagnosis and clinical decision-making. Vision Transformers (ViTs) have shown strong performance in medical image analysis by learning global contextual representations, but they often fail to capture intrinsic structural and topological patterns present in tumor regions. To address this limitation, we propose a fusion framework that combines Topological Data Analysis (TDA) features with pretrained Vision Transformer representations for four-class brain tumor classification. In the proposed method, TDA is used to extract complementary topological descriptors that capture geometric structure, connectivity, and shape information from MRI images. In parallel, a pretrained ViT model learns high-level semantic representations from the same images. These two feature spaces are then fused to form a unified and more discriminative representation for classification. The model is evaluated on the BRISC2025 dataset, which contains four brain tumor classes: glioma, meningioma, pituitary tumor, and non-tumor cases. Experimental results show that combining topological and transformer-based features significantly improves performance compared to using either approach alone. The proposed TDA-ViT fusion model achieves an accuracy of 99.10%, precision of 99.27%, recall of 99.15%, F1-score of 99.21%, and an AUC of 99.98%. It also outperforms several state-of-the-art models, including ResNet50, ResNet101, EfficientNetB2, and standalone Vision Transformers. These results demonstrate that topological features provide valuable complementary information that enhances deep representation learning, leading to a robust and highly accurate framework for automated brain tumor classification.
Brain Tumor Classification from 3D MRI Using Persistent Homology and Betti Features: A Topological Data Analysis Approach on BraTS2020
Mar 14, 2026Accurate and interpretable brain tumor classification from medical imaging remains a challenging problem due to the high dimensionality and complex structural patterns present in magnetic resonance imaging (MRI). In this study, we propose a topology-driven framework for brain tumor classification based on Topological Data Analysis (TDA) applied directly to three-dimensional (3D) MRI volumes. Specifically, we analyze 3D Fluid Attenuated Inversion Recovery (FLAIR) images from the BraTS 2020 dataset and extract interpretable topological descriptors using persistent homology. Persistent homology captures intrinsic geometric and structural characteristics of the data through Betti numbers, which describe connected components (Betti-0), loops (Betti-1), and voids (Betti-2). From the 3D MRI volumes, we derive a compact set of 100 topological features that summarize the underlying topology of brain tumor structures. These descriptors represent complex 3D tumor morphology while significantly reducing data dimensionality. Unlike many deep learning approaches that require large-scale training data or complex architectures, the proposed framework relies on computationally efficient topological features extracted directly from the images. These features are used to train classical machine learning classifiers, including Random Forest and XGBoost, for binary classification of high-grade glioma (HGG) and low-grade glioma (LGG). Experimental results on the BraTS 2020 dataset show that the Random Forest classifier combined with selected Betti features achieves an accuracy of 89.19%. These findings highlight the potential of persistent homology as an effective and interpretable approach for analyzing complex 3D medical images and performing brain tumor classification.
Hybrid Topological and Deep Feature Fusion for Accurate MRI-Based Alzheimer's Disease Severity Classification
Feb 01, 2026Early and accurate diagnosis of Alzheimer's disease (AD) remains a critical challenge in neuroimaging-based clinical decision support systems. In this work, we propose a novel hybrid deep learning framework that integrates Topological Data Analysis (TDA) with a DenseNet121 backbone for four-class Alzheimer's disease classification using structural MRI data from the OASIS dataset. TDA is employed to capture complementary topological characteristics of brain structures that are often overlooked by conventional neural networks, while DenseNet121 efficiently learns hierarchical spatial features from MRI slices. The extracted deep and topological features are fused to enhance class separability across the four AD stages. Extensive experiments conducted on the OASIS-1 Kaggle MRI dataset demonstrate that the proposed TDA+DenseNet121 model significantly outperforms existing state-of-the-art approaches. The model achieves an accuracy of 99.93% and an AUC of 100%, surpassing recently published CNN-based, transfer learning, ensemble, and multi-scale architectures. These results confirm the effectiveness of incorporating topological insights into deep learning pipelines and highlight the potential of the proposed framework as a robust and highly accurate tool for automated Alzheimer's disease diagnosis.
Four-Stage Alzheimer's Disease Classification from MRI Using Topological Feature Extraction, Feature Selection, and Ensemble Learning
Jan 01, 2026Accurate and efficient classification of Alzheimer's disease (AD) severity from brain magnetic resonance imaging (MRI) remains a critical challenge, particularly when limited data and model interpretability are of concern. In this work, we propose TDA-Alz, a novel framework for four-stage Alzheimer's disease severity classification (non-demented, moderate dementia, mild, and very mild) using topological data analysis (TDA) and ensemble learning. Instead of relying on deep convolutional architectures or extensive data augmentation, our approach extracts topological descriptors that capture intrinsic structural patterns of brain MRI, followed by feature selection to retain the most discriminative topological features. These features are then classified using an ensemble learning strategy to achieve robust multiclass discrimination. Experiments conducted on the OASIS-1 MRI dataset demonstrate that the proposed method achieves an accuracy of 98.19% and an AUC of 99.75%, outperforming or matching state-of-the-art deep learning--based methods reported on OASIS and OASIS-derived datasets. Notably, the proposed framework does not require data augmentation, pretrained networks, or large-scale computational resources, making it computationally efficient and fast compared to deep neural network approaches. Furthermore, the use of topological descriptors provides greater interpretability, as the extracted features are directly linked to the underlying structural characteristics of brain MRI rather than opaque latent representations. These results indicate that TDA-Alz offers a powerful, lightweight, and interpretable alternative to deep learning models for MRI-based Alzheimer's disease severity classification, with strong potential for real-world clinical decision-support systems.
Colormap-Enhanced Vision Transformers for MRI-Based Multiclass (4-Class) Alzheimer's Disease Classification
Dec 18, 2025
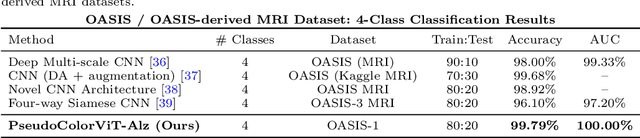
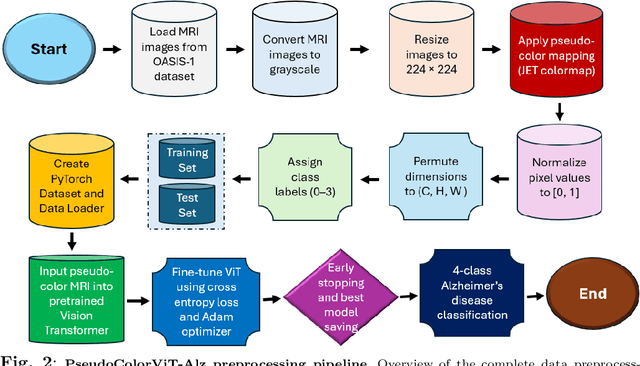
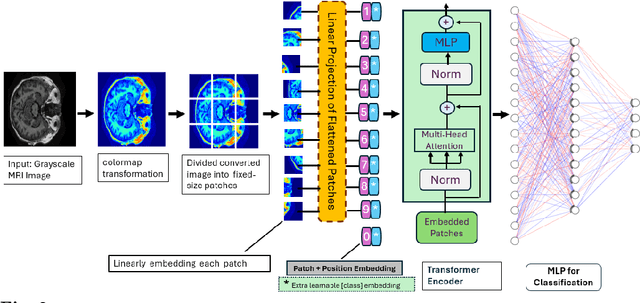
Magnetic Resonance Imaging (MRI) plays a pivotal role in the early diagnosis and monitoring of Alzheimer's disease (AD). However, the subtle structural variations in brain MRI scans often pose challenges for conventional deep learning models to extract discriminative features effectively. In this work, we propose PseudoColorViT-Alz, a colormap-enhanced Vision Transformer framework designed to leverage pseudo-color representations of MRI images for improved Alzheimer's disease classification. By combining colormap transformations with the global feature learning capabilities of Vision Transformers, our method amplifies anatomical texture and contrast cues that are otherwise subdued in standard grayscale MRI scans. We evaluate PseudoColorViT-Alz on the OASIS-1 dataset using a four-class classification setup (non-demented, moderate dementia, mild dementia, and very mild dementia). Our model achieves a state-of-the-art accuracy of 99.79% with an AUC of 100%, surpassing the performance of recent 2024--2025 methods, including CNN-based and Siamese-network approaches, which reported accuracies ranging from 96.1% to 99.68%. These results demonstrate that pseudo-color augmentation combined with Vision Transformers can significantly enhance MRI-based Alzheimer's disease classification. PseudoColorViT-Alz offers a robust and interpretable framework that outperforms current methods, providing a promising tool to support clinical decision-making and early detection of Alzheimer's disease.
3D-TDA -- Topological feature extraction from 3D images for Alzheimer's disease classification
Nov 11, 2025



Now that disease-modifying therapies for Alzheimer disease have been approved by regulatory agencies, the early, objective, and accurate clinical diagnosis of AD based on the lowest-cost measurement modalities possible has become an increasingly urgent need. In this study, we propose a novel feature extraction method using persistent homology to analyze structural MRI of the brain. This approach converts topological features into powerful feature vectors through Betti functions. By integrating these feature vectors with a simple machine learning model like XGBoost, we achieve a computationally efficient machine learning model. Our model outperforms state-of-the-art deep learning models in both binary and three-class classification tasks for ADNI 3D MRI disease diagnosis. Using 10-fold cross-validation, our model achieved an average accuracy of 97.43 percent and sensitivity of 99.09 percent for binary classification. For three-class classification, it achieved an average accuracy of 95.47 percent and sensitivity of 94.98 percent. Unlike many deep learning models, our approach does not require data augmentation or extensive preprocessing, making it particularly suitable for smaller datasets. Topological features differ significantly from those commonly extracted using convolutional filters and other deep learning machinery. Because it provides an entirely different type of information from machine learning models, it has the potential to combine topological features with other models later on.
RepViT-CXR: A Channel Replication Strategy for Vision Transformers in Chest X-ray Tuberculosis and Pneumonia Classification
Sep 10, 2025



Chest X-ray (CXR) imaging remains one of the most widely used diagnostic tools for detecting pulmonary diseases such as tuberculosis (TB) and pneumonia. Recent advances in deep learning, particularly Vision Transformers (ViTs), have shown strong potential for automated medical image analysis. However, most ViT architectures are pretrained on natural images and require three-channel inputs, while CXR scans are inherently grayscale. To address this gap, we propose RepViT-CXR, a channel replication strategy that adapts single-channel CXR images into a ViT-compatible format without introducing additional information loss. We evaluate RepViT-CXR on three benchmark datasets. On the TB-CXR dataset,our method achieved an accuracy of 99.9% and an AUC of 99.9%, surpassing prior state-of-the-art methods such as Topo-CXR (99.3% accuracy, 99.8% AUC). For the Pediatric Pneumonia dataset, RepViT-CXR obtained 99.0% accuracy, with 99.2% recall, 99.3% precision, and an AUC of 99.0%, outperforming strong baselines including DCNN and VGG16. On the Shenzhen TB dataset, our approach achieved 91.1% accuracy and an AUC of 91.2%, marking a performance improvement over previously reported CNN-based methods. These results demonstrate that a simple yet effective channel replication strategy allows ViTs to fully leverage their representational power on grayscale medical imaging tasks. RepViT-CXR establishes a new state of the art for TB and pneumonia detection from chest X-rays, showing strong potential for deployment in real-world clinical screening systems.
HOG-CNN: Integrating Histogram of Oriented Gradients with Convolutional Neural Networks for Retinal Image Classification
Jul 29, 2025The analysis of fundus images is critical for the early detection and diagnosis of retinal diseases such as Diabetic Retinopathy (DR), Glaucoma, and Age-related Macular Degeneration (AMD). Traditional diagnostic workflows, however, often depend on manual interpretation and are both time- and resource-intensive. To address these limitations, we propose an automated and interpretable clinical decision support framework based on a hybrid feature extraction model called HOG-CNN. Our key contribution lies in the integration of handcrafted Histogram of Oriented Gradients (HOG) features with deep convolutional neural network (CNN) representations. This fusion enables our model to capture both local texture patterns and high-level semantic features from retinal fundus images. We evaluated our model on three public benchmark datasets: APTOS 2019 (for binary and multiclass DR classification), ORIGA (for Glaucoma detection), and IC-AMD (for AMD diagnosis); HOG-CNN demonstrates consistently high performance. It achieves 98.5\% accuracy and 99.2 AUC for binary DR classification, and 94.2 AUC for five-class DR classification. On the IC-AMD dataset, it attains 92.8\% accuracy, 94.8\% precision, and 94.5 AUC, outperforming several state-of-the-art models. For Glaucoma detection on ORIGA, our model achieves 83.9\% accuracy and 87.2 AUC, showing competitive performance despite dataset limitations. We show, through comprehensive appendix studies, the complementary strength of combining HOG and CNN features. The model's lightweight and interpretable design makes it particularly suitable for deployment in resource-constrained clinical environments. These results position HOG-CNN as a robust and scalable tool for automated retinal disease screening.
Robust Five-Class and binary Diabetic Retinopathy Classification Using Transfer Learning and Data Augmentation
Jul 23, 2025Diabetic retinopathy (DR) is a leading cause of vision loss worldwide, and early diagnosis through automated retinal image analysis can significantly reduce the risk of blindness. This paper presents a robust deep learning framework for both binary and five-class DR classification, leveraging transfer learning and extensive data augmentation to address the challenges of class imbalance and limited training data. We evaluate a range of pretrained convolutional neural network architectures, including variants of ResNet and EfficientNet, on the APTOS 2019 dataset. For binary classification, our proposed model achieves a state-of-the-art accuracy of 98.9%, with a precision of 98.6%, recall of 99.3%, F1-score of 98.9%, and an AUC of 99.4%. In the more challenging five-class severity classification task, our model obtains a competitive accuracy of 84.6% and an AUC of 94.1%, outperforming several existing approaches. Our findings also demonstrate that EfficientNet-B0 and ResNet34 offer optimal trade-offs between accuracy and computational efficiency across both tasks. These results underscore the effectiveness of combining class-balanced augmentation with transfer learning for high-performance DR diagnosis. The proposed framework provides a scalable and accurate solution for DR screening, with potential for deployment in real-world clinical environments.
FedAuxHMTL: Federated Auxiliary Hard-Parameter Sharing Multi-Task Learning for Network Edge Traffic Classification
Apr 11, 2024Federated Learning (FL) has garnered significant interest recently due to its potential as an effective solution for tackling many challenges in diverse application scenarios, for example, data privacy in network edge traffic classification. Despite its recognized advantages, FL encounters obstacles linked to statistical data heterogeneity and labeled data scarcity during the training of single-task models for machine learning-based traffic classification, leading to hindered learning performance. In response to these challenges, adopting a hard-parameter sharing multi-task learning model with auxiliary tasks proves to be a suitable approach. Such a model has the capability to reduce communication and computation costs, navigate statistical complexities inherent in FL contexts, and overcome labeled data scarcity by leveraging knowledge derived from interconnected auxiliary tasks. This paper introduces a new framework for federated auxiliary hard-parameter sharing multi-task learning, namely, FedAuxHMTL. The introduced framework incorporates model parameter exchanges between edge server and base stations, enabling base stations from distributed areas to participate in the FedAuxHMTL process and enhance the learning performance of the main task-network edge traffic classification. Empirical experiments are conducted to validate and demonstrate the FedAuxHMTL's effectiveness in terms of accuracy, total global loss, communication costs, computing time, and energy consumption compared to its counterparts.