 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Qiao
Tiny LVLM-eHub: Early Multimodal Experiments with Bard
Aug 07, 2023

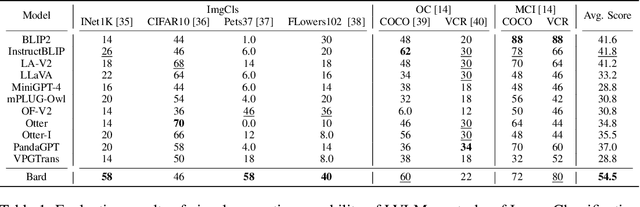
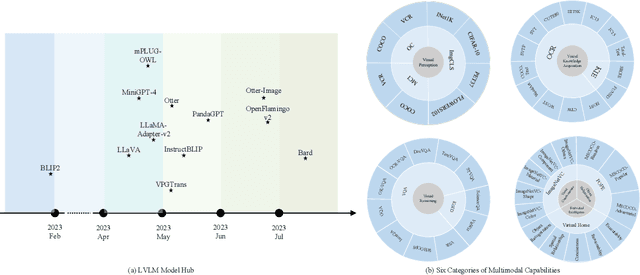
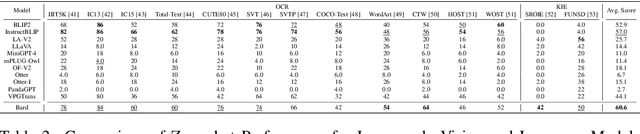
Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated significant progress in tackling complex multimodal tasks. Among these cutting-edge developments, Google's Bard stands out for its remarkable multimodal capabilities, promoting comprehensive comprehension and reasoning across various domains. This work presents an early and holistic evaluation of LVLMs' multimodal abilities, with a particular focus on Bard, by proposing a lightweight variant of LVLM-eHub, named Tiny LVLM-eHub. In comparison to the vanilla version, Tiny LVLM-eHub possesses several appealing properties. Firstly, it provides a systematic assessment of six categories of multimodal capabilities, including visual perception, visual knowledge acquisition, visual reasoning, visual commonsense, object hallucination, and embodied intelligence, through quantitative evaluation of $42$ standard text-related visual benchmarks. Secondly, it conducts an in-depth analysis of LVLMs' predictions using the ChatGPT Ensemble Evaluation (CEE), which leads to a robust and accurate evaluation and exhibits improved alignment with human evaluation compared to the word matching approach. Thirdly, it comprises a mere $2.1$K image-text pairs, facilitating ease of use for practitioners to evaluate their own offline LVLMs. Through extensive experimental analysis, this study demonstrates that Bard outperforms previous LVLMs in most multimodal capabilities except object hallucination, to which Bard is still susceptible. Tiny LVLM-eHub serves as a baseline evaluation for various LVLMs and encourages innovative strategies aimed at advancing multimodal techniques. Our project is publicly available at \url{https://github.com/OpenGVLab/Multi-Modality-Arena}.
The All-Seeing Project: Towards Panoptic Visual Recognition and Understanding of the Open World
Aug 03, 2023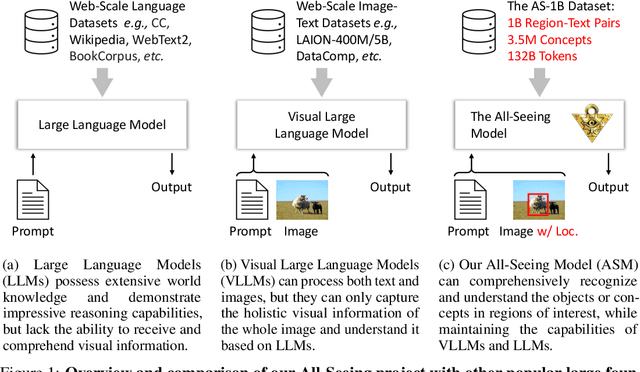
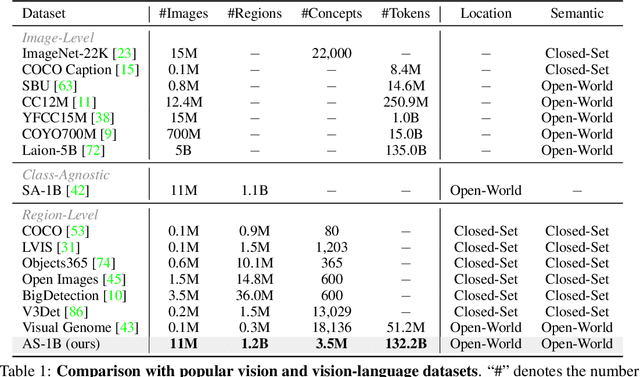
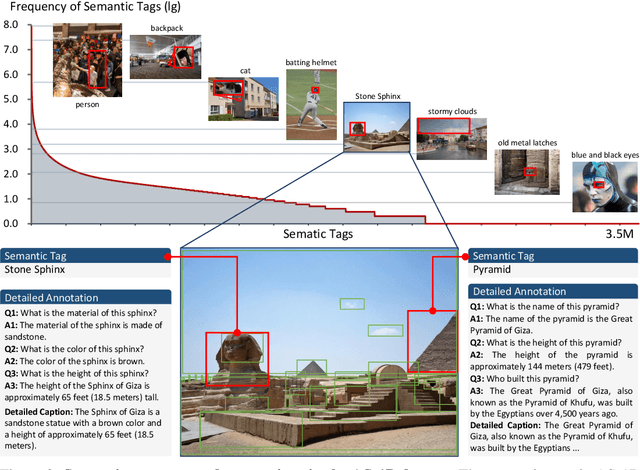
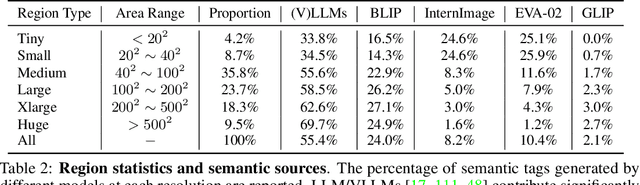
We present the All-Seeing (AS) project: a large-scale data and model for recognizing and understanding everything in the open world. Using a scalable data engine that incorporates human feedback and efficient models in the loop, we create a new dataset (AS-1B) with over 1 billion regions annotated with semantic tags, question-answering pairs, and detailed captions. It covers a wide range of 3.5 million common and rare concepts in the real world, and has 132.2 billion tokens that describe the concepts and their attributes. Leveraging this new dataset, we develop the All-Seeing model (ASM), a unified framework for panoptic visual recognition and understanding. The model is trained with open-ended language prompts and locations, which allows it to generalize to various vision and language tasks with remarkable zero-shot performance, including region-text retrieval, region recognition, captioning, and question-answering. We hope that this project can serve as a foundation for vision-language artificial general intelligence research. Models and the dataset shall be released at https://github.com/OpenGVLab/All-Seeing, and demo can be seen at https://huggingface.co/spaces/OpenGVLab/all-seeing.
Scaling Data Generation in Vision-and-Language Navigation
Jul 28, 2023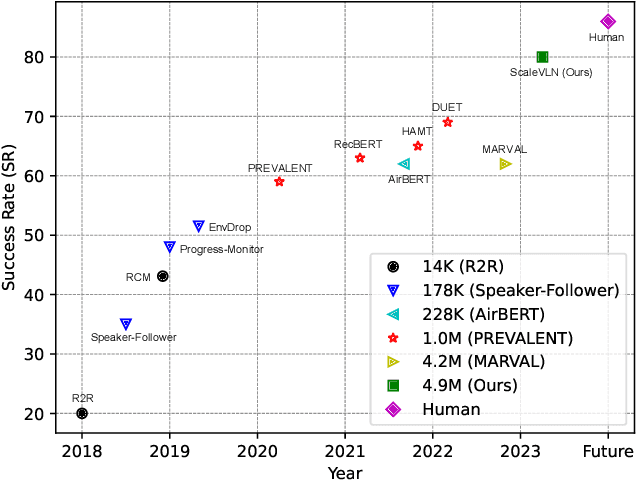
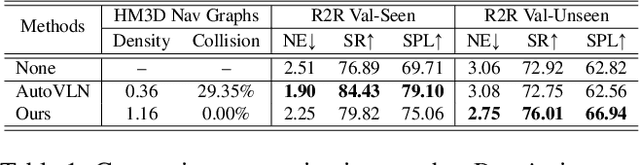
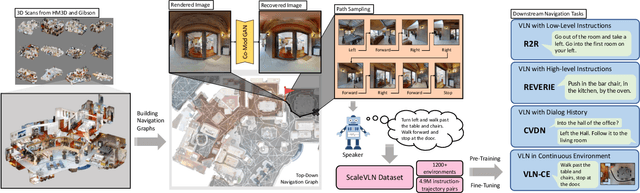
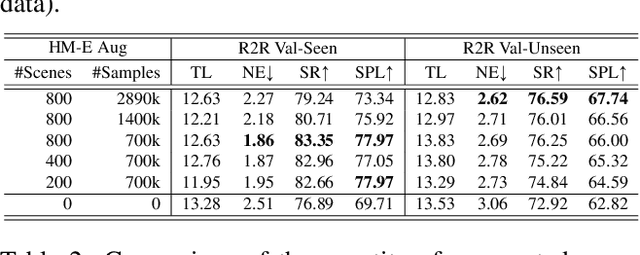
Recent research in language-guided visual navigation has demonstrated a significant demand for the diversity of traversable environments and the quantity of supervision for training generalizable agents. To tackle the common data scarcity issue in existing vision-and-language navigation datasets, we propose an effective paradigm for generating large-scale data for learning, which applies 1200+ photo-realistic environments from HM3D and Gibson datasets and synthesizes 4.9 million instruction trajectory pairs using fully-accessible resources on the web. Importantly, we investigate the influence of each component in this paradigm on the agent's performance and study how to adequately apply the augmented data to pre-train and fine-tune an agent. Thanks to our large-scale dataset, the performance of an existing agent can be pushed up (+11% absolute with regard to previous SoTA) to a significantly new best of 80% single-run success rate on the R2R test split by simple imitation learning. The long-lasting generalization gap between navigating in seen and unseen environments is also reduced to less than 1% (versus 8% in the previous best method). Moreover, our paradigm also facilitates different models to achieve new state-of-the-art navigation results on CVDN, REVERIE, and R2R in continuous environments.
Scaling TransNormer to 175 Billion Parameters
Jul 27, 2023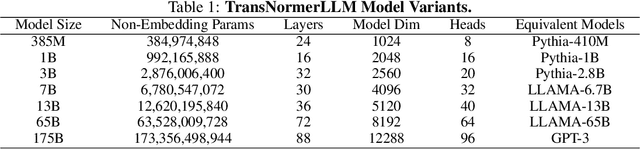
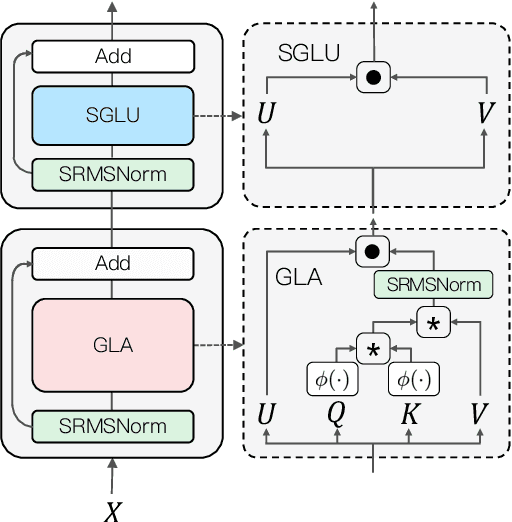
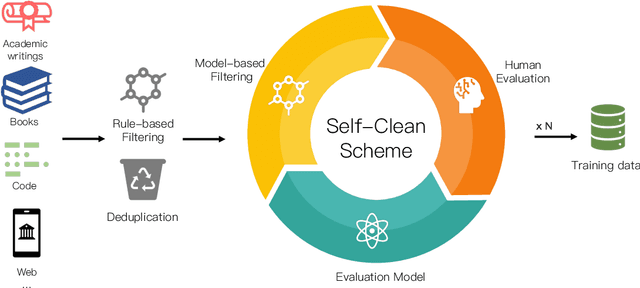
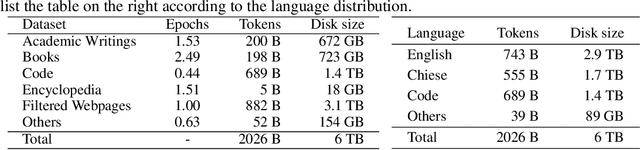
We present TransNormerLLM, the first linear attention-based Large Language Model (LLM) that outperforms conventional softmax attention-based models in terms of both accuracy and efficiency. TransNormerLLM evolves from the previous linear attention architecture TransNormer by making advanced modifications that include positional embedding, linear attention acceleration, gating mechanism, tensor normalization, inference acceleration and stabilization. Specifically, we use LRPE together with an exponential decay to avoid attention dilution issues while allowing the model to retain global interactions between tokens. Additionally, we propose Lightning Attention, a cutting-edge technique that accelerates linear attention by more than twice in runtime and reduces memory usage by a remarkable four times. To further enhance the performance of TransNormer, we leverage a gating mechanism to smooth training and a new tensor normalization scheme to accelerate the model, resulting in an impressive acceleration of over 20%. Furthermore, we have developed a robust inference algorithm that ensures numerical stability and consistent inference speed, regardless of the sequence length, showcasing superior efficiency during both training and inference stages. Scalability is at the heart of our model's design, enabling seamless deployment on large-scale clusters and facilitating expansion to even more extensive models, all while maintaining outstanding performance metrics. Rigorous validation of our model design is achieved through a series of comprehensive experiments on our self-collected corpus, boasting a size exceeding 6TB and containing over 2 trillion tokens. To ensure data quality and relevance, we implement a new self-cleaning strategy to filter our collected data. Our pre-trained models will be released to foster community advancements in efficient LLMs.
Text-guided Foundation Model Adaptation for Pathological Image Classification
Jul 27, 2023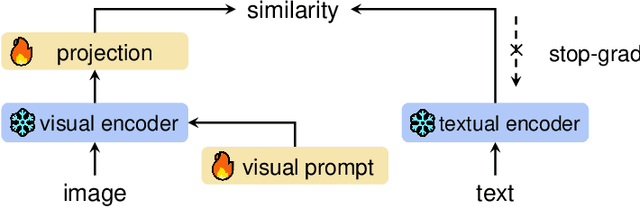

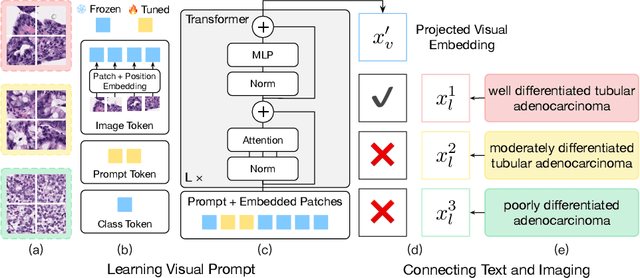
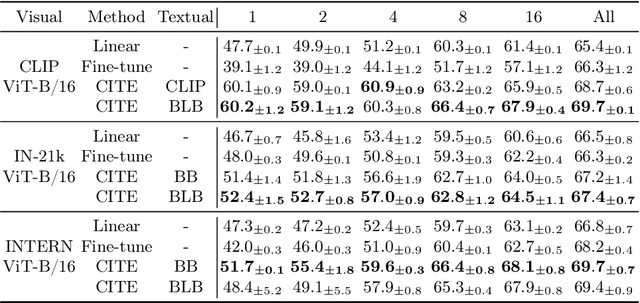
The recent surge of foundation models in computer vision and natural language processing opens up perspectives in utilizing multi-modal clinical data to train large models with strong generalizability. Yet pathological image datasets often lack biomedical text annotation and enrichment. Guiding data-efficient image diagnosis from the use of biomedical text knowledge becomes a substantial interest. In this paper, we propose to Connect Image and Text Embeddings (CITE) to enhance pathological image classification. CITE injects text insights gained from language models pre-trained with a broad range of biomedical texts, leading to adapt foundation models towards pathological image understanding. Through extensive experiments on the PatchGastric stomach tumor pathological image dataset, we demonstrate that CITE achieves leading performance compared with various baselines especially when training data is scarce. CITE offers insights into leveraging in-domain text knowledge to reinforce data-efficient pathological image classification. Code is available at https://github.com/Yunkun-Zhang/CITE.
LimSim: A Long-term Interactive Multi-scenario Traffic Simulator
Jul 26, 2023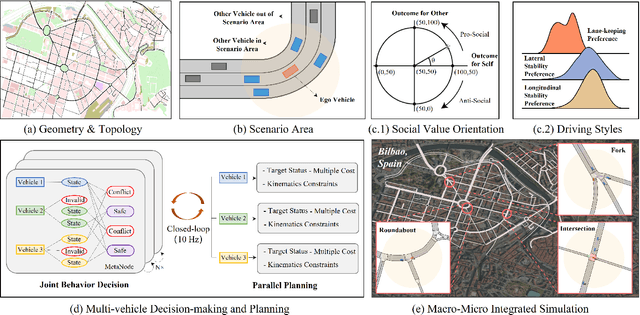
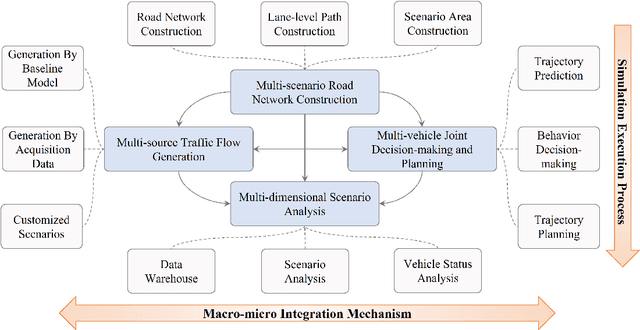
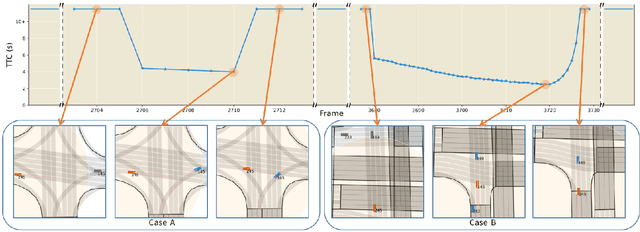
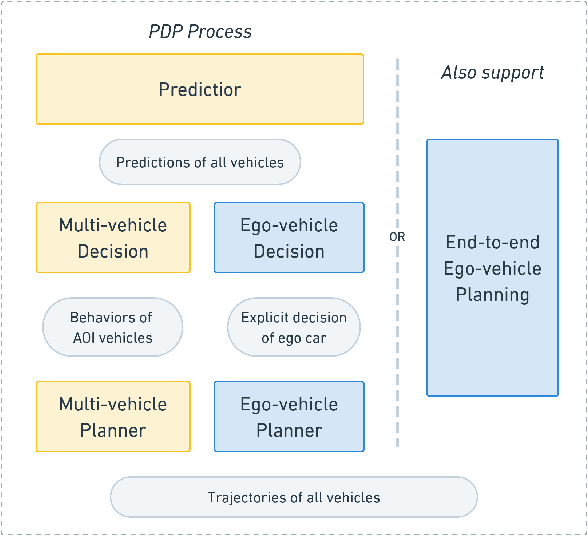
With the growing popularity of digital twin and autonomous driving in transportation, the demand for simulation systems capable of generating high-fidelity and reliable scenarios is increasing. Existing simulation systems suffer from a lack of support for different types of scenarios, and the vehicle models used in these systems are too simplistic. Thus, such systems fail to represent driving styles and multi-vehicle interactions, and struggle to handle corner cases in the dataset. In this paper, we propose LimSim, the Long-term Interactive Multi-scenario traffic Simulator, which aims to provide a long-term continuous simulation capability under the urban road network. LimSim can simulate fine-grained dynamic scenarios and focus on the diverse interactions between multiple vehicles in the traffic flow. This paper provides a detailed introduction to the framework and features of the LimSim, and demonstrates its performance through case studies and experiments. LimSim is now open source on GitHub: https://www.github.com/PJLab-ADG/LimSim .
FedMEKT: Distillation-based Embedding Knowledge Transfer for Multimodal Federated Learning
Jul 25, 2023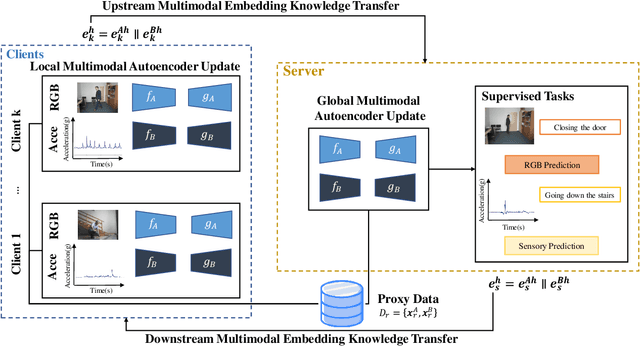
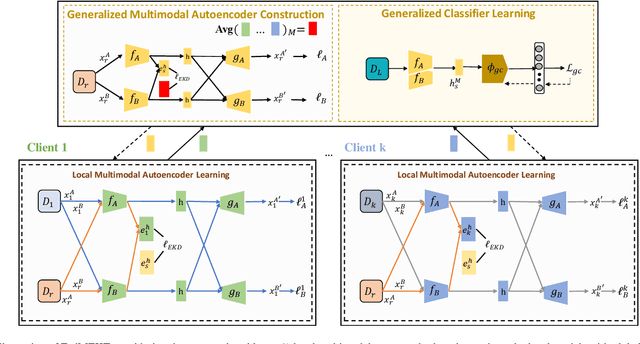
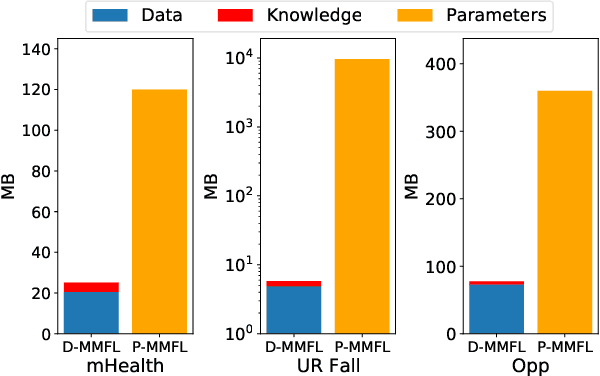
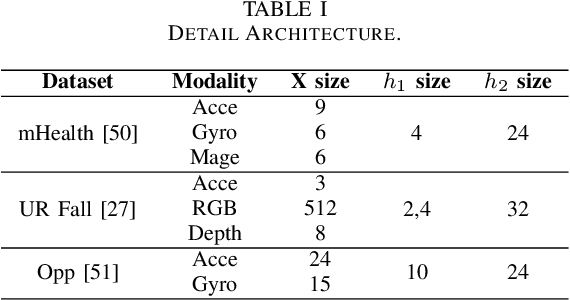
Federated learning (FL) enables a decentralized machine learning paradigm for multiple clients to collaboratively train a generalized global model without sharing their private data. Most existing works simply propose typical FL systems for single-modal data, thus limiting its potential on exploiting valuable multimodal data for future personalized applications. Furthermore, the majority of FL approaches still rely on the labeled data at the client side, which is limited in real-world applications due to the inability of self-annotation from users. In light of these limitations, we propose a novel multimodal FL framework that employs a semi-supervised learning approach to leverage the representations from different modalities. Bringing this concept into a system, we develop a distillation-based multimodal embedding knowledge transfer mechanism, namely FedMEKT, which allows the server and clients to exchange the joint knowledge of their learning models extracted from a small multimodal proxy dataset. Our FedMEKT iteratively updates the generalized global encoders with the joint embedding knowledge from the participating clients. Thereby, to address the modality discrepancy and labeled data constraint in existing FL systems, our proposed FedMEKT comprises local multimodal autoencoder learning, generalized multimodal autoencoder construction, and generalized classifier learning. Through extensive experiments on three multimodal human activity recognition datasets, we demonstrate that FedMEKT achieves superior global encoder performance on linear evaluation and guarantees user privacy for personal data and model parameters while demanding less communication cost than other baselines.
Meta-Transformer: A Unified Framework for Multimodal Learning
Jul 20, 2023
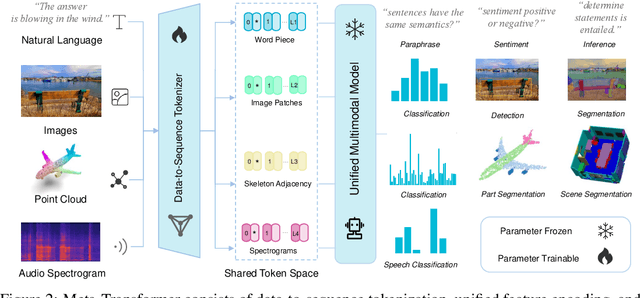
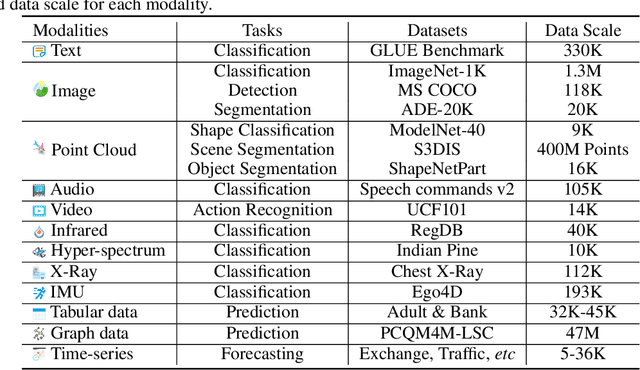
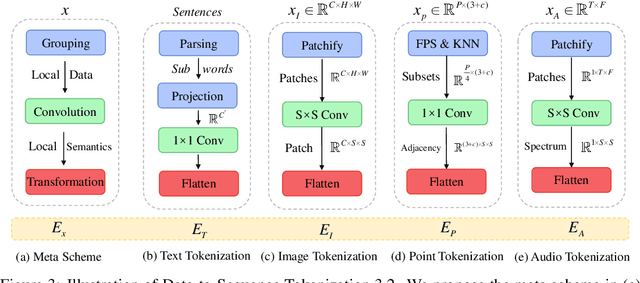
Multimodal learning aims to build models that can process and relate information from multiple modalities. Despite years of development in this field, it still remains challenging to design a unified network for processing various modalities ($\textit{e.g.}$ natural language, 2D images, 3D point clouds, audio, video, time series, tabular data) due to the inherent gaps among them. In this work, we propose a framework, named Meta-Transformer, that leverages a $\textbf{frozen}$ encoder to perform multimodal perception without any paired multimodal training data. In Meta-Transformer, the raw input data from various modalities are mapped into a shared token space, allowing a subsequent encoder with frozen parameters to extract high-level semantic features of the input data. Composed of three main components: a unified data tokenizer, a modality-shared encoder, and task-specific heads for downstream tasks, Meta-Transformer is the first framework to perform unified learning across 12 modalities with unpaired data. Experiments on different benchmarks reveal that Meta-Transformer can handle a wide range of tasks including fundamental perception (text, image, point cloud, audio, video), practical application (X-Ray, infrared, hyperspectral, and IMU), and data mining (graph, tabular, and time-series). Meta-Transformer indicates a promising future for developing unified multimodal intelligence with transformers. Code will be available at https://github.com/invictus717/MetaTransformer
Boosting Federated Learning Convergence with Prototype Regularization
Jul 20, 2023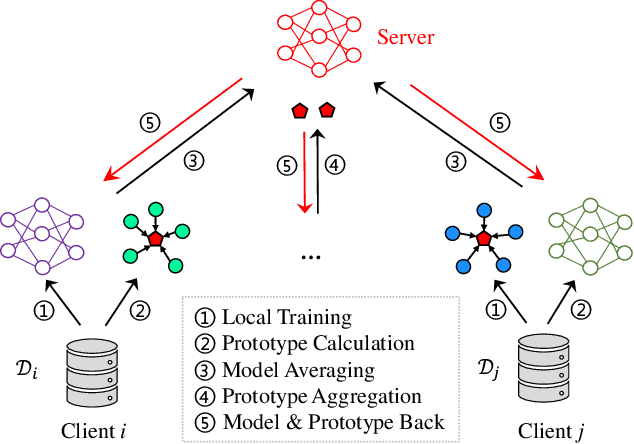
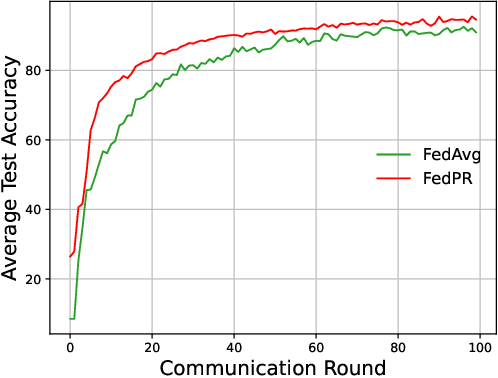
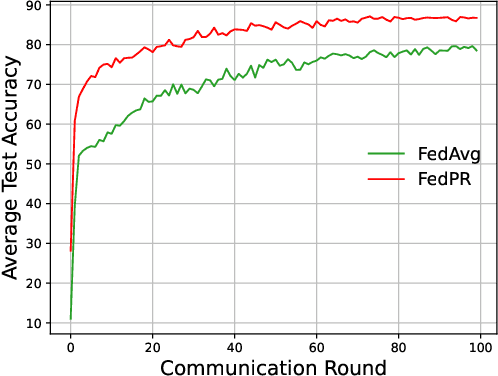
As a distributed machine learning technique, federated learning (FL) requires clients to collaboratively train a shared model with an edge server without leaking their local data. However, the heterogeneous data distribution among clients often leads to a decrease in model performance. To tackle this issue, this paper introduces a prototype-based regularization strategy to address the heterogeneity in the data distribution. Specifically, the regularization process involves the server aggregating local prototypes from distributed clients to generate a global prototype, which is then sent back to the individual clients to guide their local training. The experimental results on MNIST and Fashion-MNIST show that our proposal achieves improvements of 3.3% and 8.9% in average test accuracy, respectively, compared to the most popular baseline FedAvg. Furthermore, our approach has a fast convergence rate in heterogeneous settings.
Drive Like a Human: Rethinking Autonomous Driving with Large Language Models
Jul 14, 2023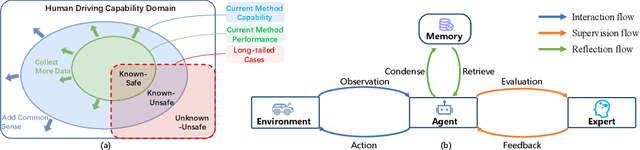
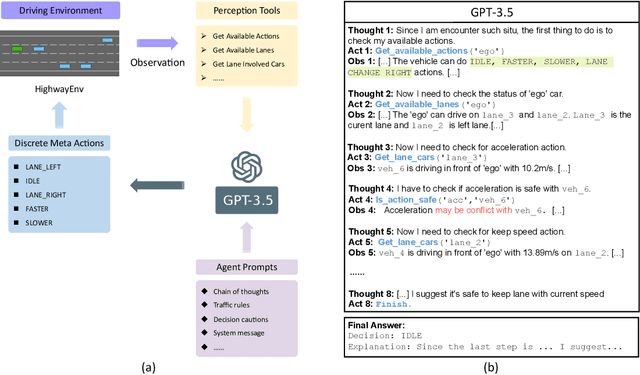
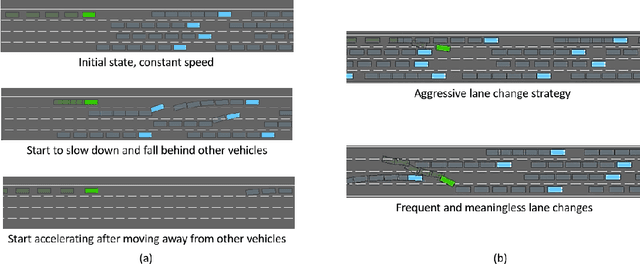

In this paper, we explore the potential of using a large language model (LLM) to understand the driving environment in a human-like manner and analyze its ability to reason, interpret, and memorize when facing complex scenarios. We argue that traditional optimization-based and modular autonomous driving (AD) systems face inherent performance limitations when dealing with long-tail corner cases. To address this problem, we propose that an ideal AD system should drive like a human, accumulating experience through continuous driving and using common sense to solve problems. To achieve this goal, we identify three key abilities necessary for an AD system: reasoning, interpretation, and memorization. We demonstrate the feasibility of employing an LLM in driving scenarios by building a closed-loop system to showcase its comprehension and environment-interaction abilities. Our extensive experiments show that the LLM exhibits the impressive ability to reason and solve long-tailed cases, providing valuable insights for the development of human-like autonomous driving. The related code are available at https://github.com/PJLab-ADG/DriveLikeAHuman .