 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTadA-Bench: A Million-Variant Benchmark for Future-Round Discovery Toward Agentic Protein Engineering
May 29, 2026AI for scientific discovery is entering an agentic era, where protein-engineering systems are expected to prioritize future wet-lab experiments rather than merely fit static measurements. We introduce TadA-Bench, a million-variant wet-lab replay benchmark from 31 TadA directed-evolution rounds for future-round discovery toward agentic protein engineering. TadA-Bench preserves the campaign chronology and defines a fixed-data replay task: given earlier experimental rounds, models rank variants that appear only in later rounds. It provides aligned DNA, RNA, and protein views, and uses Seq2Graph, a graph-based label-unification pipeline, to reconcile noisy enrichment measurements into consistent cross-round activity labels. Random-split controls show strong interpolation, but future-round ranking and finite-budget candidate selection are much weaker. Controlled analyses suggest that evolutionary coverage is more informative than local data density, positioning TadA-Bench as a reproducible wet-lab replay substrate for future-round discovery toward agentic protein engineering; the data and code are released on Hugging Face and GitHub.
Aligned Agents, Biased Swarm: Measuring Bias Amplification in Multi-Agent Systems
Apr 13, 2026While Multi-Agent Systems (MAS) are increasingly deployed for complex workflows, their emergent properties-particularly the accumulation of bias-remain poorly understood. Because real-world MAS are too complex to analyze entirely, evaluating their ethical robustness requires first isolating their foundational mechanics. In this work, we conduct a baseline empirical study investigating how basic MAS topologies and feedback loops influence prejudice. Contrary to the assumption that multi-agent collaboration naturally dilutes bias, we hypothesize that structured workflows act as echo chambers, amplifying minor stochastic biases into systemic polarization. To evaluate this, we introduce Discrim-Eval-Open, an open-ended benchmark that bypasses individual model neutrality through forced comparative judgments across demographic groups. Analyzing bias cascades across various structures reveals that architectural sophistication frequently exacerbates bias rather than mitigating it. We observe systemic amplification even when isolated agents operate neutrally, and identify a 'Trigger Vulnerability' where injecting purely objective context drastically accelerates polarization. By stripping away advanced swarm complexity to study foundational dynamics, we establish a crucial baseline: structural complexity does not guarantee ethical robustness. Our code is available at https://github.com/weizhihao1/MAS-Bias.
Credit-Budgeted ICPC-Style Coding: When Agents Must Pay for Every Decision
Apr 11, 2026Current evaluations of autonomous coding agents assume an unrealistic, infinite-resource environment. However, real-world software engineering is a resource-bound competition. As we scale toward large agent swarms, ignoring compute and time costs risks catastrophic budget exhaustion. To shift the focus from isolated accuracy to cost-aware problem-solving, we introduce USACOArena, an interactive ACM-ICPC-style arena driven by a strict "credit" economy. Every generated token, local test, and elapsed second depletes a fixed budget, forcing agents to make strategic trade-offs. Our comprehensive profiling reveals that frontier single agents and swarms currently fail to optimally balance accuracy with these constraints, exhibiting divergent, path-dependent behaviors. Ultimately, USACOArena provides an essential dynamic training ground for developing highly efficient, resource-aware agent architectures.
Learning Native Continuation for Action Chunking Flow Policies
Feb 13, 2026Action chunking enables Vision Language Action (VLA) models to run in real time, but naive chunked execution often exhibits discontinuities at chunk boundaries. Real-Time Chunking (RTC) alleviates this issue but is external to the policy, leading to spurious multimodal switching and trajectories that are not intrinsically smooth. We propose Legato, a training-time continuation method for action-chunked flow-based VLA policies. Specifically, Legato initializes denoising from a schedule-shaped mixture of known actions and noise, exposing the model to partial action information. Moreover, Legato reshapes the learned flow dynamics to ensure that the denoising process remains consistent between training and inference under per-step guidance. Legato further uses randomized schedule condition during training to support varying inference delays and achieve controllable smoothness. Empirically, Legato produces smoother trajectories and reduces spurious multimodal switching during execution, leading to less hesitation and shorter task completion time. Extensive real-world experiments show that Legato consistently outperforms RTC across five manipulation tasks, achieving approximately 10% improvements in both trajectory smoothness and task completion time.
daVinci-Agency: Unlocking Long-Horizon Agency Data-Efficiently
Feb 02, 2026While Large Language Models (LLMs) excel at short-term tasks, scaling them to long-horizon agentic workflows remains challenging. The core bottleneck lies in the scarcity of training data that captures authentic long-dependency structures and cross-stage evolutionary dynamics--existing synthesis methods either confine to single-feature scenarios constrained by model distribution, or incur prohibitive human annotation costs, failing to provide scalable, high-quality supervision. We address this by reconceptualizing data synthesis through the lens of real-world software evolution. Our key insight: Pull Request (PR) sequences naturally embody the supervision signals for long-horizon learning. They decompose complex objectives into verifiable submission units, maintain functional coherence across iterations, and encode authentic refinement patterns through bug-fix histories. Building on this, we propose daVinci-Agency, which systematically mines structured supervision from chain-of-PRs through three interlocking mechanisms: (1) progressive task decomposition via continuous commits, (2) long-term consistency enforcement through unified functional objectives, and (3) verifiable refinement from authentic bug-fix trajectories. Unlike synthetic trajectories that treat each step independently, daVinci-Agency's PR-grounded structure inherently preserves the causal dependencies and iterative refinements essential for teaching persistent goal-directed behavior and enables natural alignment with project-level, full-cycle task modeling. The resulting trajectories are substantial--averaging 85k tokens and 116 tool calls--yet remarkably data-efficient: fine-tuning GLM-4.6 on 239 daVinci-Agency samples yields broad improvements across benchmarks, notably achieving a 47% relative gain on Toolathlon. Beyond benchmark performance, our analysis confirms...
AgencyBench: Benchmarking the Frontiers of Autonomous Agents in 1M-Token Real-World Contexts
Jan 16, 2026Large Language Models (LLMs) based autonomous agents demonstrate multifaceted capabilities to contribute substantially to economic production. However, existing benchmarks remain focused on single agentic capability, failing to capture long-horizon real-world scenarios. Moreover, the reliance on human-in-the-loop feedback for realistic tasks creates a scalability bottleneck, hindering automated rollout collection and evaluation. To bridge this gap, we introduce AgencyBench, a comprehensive benchmark derived from daily AI usage, evaluating 6 core agentic capabilities across 32 real-world scenarios, comprising 138 tasks with specific queries, deliverables, and rubrics. These scenarios require an average of 90 tool calls, 1 million tokens, and hours of execution time to resolve. To enable automated evaluation, we employ a user simulation agent to provide iterative feedback, and a Docker sandbox to conduct visual and functional rubric-based assessment. Experiments reveal that closed-source models significantly outperform open-source models (48.4% vs 32.1%). Further analysis reveals significant disparities across models in resource efficiency, feedback-driven self-correction, and specific tool-use preferences. Finally, we investigate the impact of agentic scaffolds, observing that proprietary models demonstrate superior performance within their native ecosystems (e.g., Claude-4.5-Opus via Claude-Agent-SDK), while open-source models exhibit distinct performance peaks, suggesting potential optimization for specific execution frameworks. AgencyBench serves as a critical testbed for next-generation agents, highlighting the necessity of co-optimizing model architecture with agentic frameworks. We believe this work sheds light on the future direction of autonomous agents, and we release the full benchmark and evaluation toolkit at https://github.com/GAIR-NLP/AgencyBench.
Saying the Unsaid: Revealing the Hidden Language of Multimodal Systems Through Telephone Games
Nov 12, 2025



Recent closed-source multimodal systems have made great advances, but their hidden language for understanding the world remains opaque because of their black-box architectures. In this paper, we use the systems' preference bias to study their hidden language: During the process of compressing the input images (typically containing multiple concepts) into texts and then reconstructing them into images, the systems' inherent preference bias introduces specific shifts in the outputs, disrupting the original input concept co-occurrence. We employ the multi-round "telephone game" to strategically leverage this bias. By observing the co-occurrence frequencies of concepts in telephone games, we quantitatively investigate the concept connection strength in the understanding of multimodal systems, i.e., "hidden language." We also contribute Telescope, a dataset of 10,000+ concept pairs, as the database of our telephone game framework. Our telephone game is test-time scalable: By iteratively running telephone games, we can construct a global map of concept connections in multimodal systems' understanding. Here we can identify preference bias inherited from training, assess generalization capability advancement, and discover more stable pathways for fragile concept connections. Furthermore, we use Reasoning-LLMs to uncover unexpected concept relationships that transcend textual and visual similarities, inferring how multimodal systems understand and simulate the world. This study offers a new perspective on the hidden language of multimodal systems and lays the foundation for future research on the interpretability and controllability of multimodal systems.
DatasetResearch: Benchmarking Agent Systems for Demand-Driven Dataset Discovery
Aug 09, 2025The rapid advancement of large language models has fundamentally shifted the bottleneck in AI development from computational power to data availability-with countless valuable datasets remaining hidden across specialized repositories, research appendices, and domain platforms. As reasoning capabilities and deep research methodologies continue to evolve, a critical question emerges: can AI agents transcend conventional search to systematically discover any dataset that meets specific user requirements, enabling truly autonomous demand-driven data curation? We introduce DatasetResearch, the first comprehensive benchmark evaluating AI agents' ability to discover and synthesize datasets from 208 real-world demands across knowledge-intensive and reasoning-intensive tasks. Our tri-dimensional evaluation framework reveals a stark reality: even advanced deep research systems achieve only 22% score on our challenging DatasetResearch-pro subset, exposing the vast gap between current capabilities and perfect dataset discovery. Our analysis uncovers a fundamental dichotomy-search agents excel at knowledge tasks through retrieval breadth, while synthesis agents dominate reasoning challenges via structured generation-yet both catastrophically fail on "corner cases" outside existing distributions. These findings establish the first rigorous baseline for dataset discovery agents and illuminate the path toward AI systems capable of finding any dataset in the digital universe. Our benchmark and comprehensive analysis provide the foundation for the next generation of self-improving AI systems and are publicly available at https://github.com/GAIR-NLP/DatasetResearch.
MedForge: Building Medical Foundation Models Like Open Source Software Development
Feb 22, 2025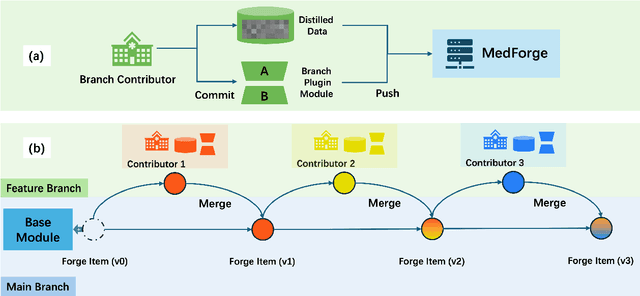
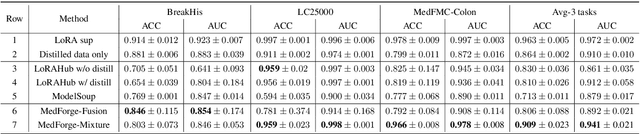
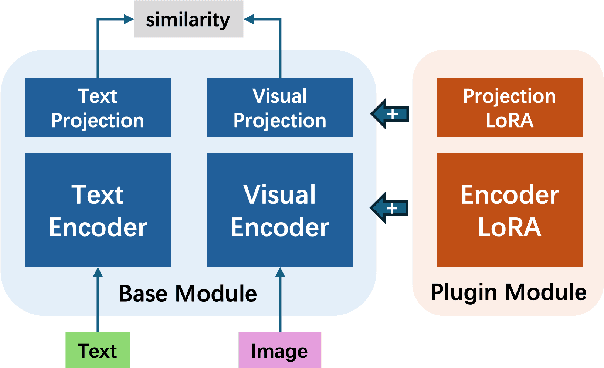
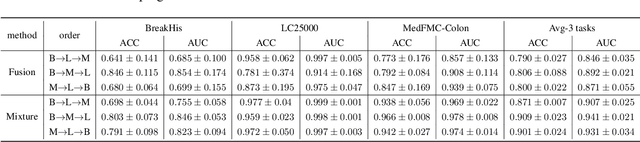
Foundational models (FMs) have made significant strides in the healthcare domain. Yet the data silo challenge and privacy concern remain in healthcare systems, hindering safe medical data sharing and collaborative model development among institutions. The collection and curation of scalable clinical datasets increasingly become the bottleneck for training strong FMs. In this study, we propose Medical Foundation Models Merging (MedForge), a cooperative framework enabling a community-driven medical foundation model development, meanwhile preventing the information leakage of raw patient data and mitigating synchronization model development issues across clinical institutions. MedForge offers a bottom-up model construction mechanism by flexibly merging task-specific Low-Rank Adaptation (LoRA) modules, which can adapt to downstream tasks while retaining original model parameters. Through an asynchronous LoRA module integration scheme, the resulting composite model can progressively enhance its comprehensive performance on various clinical tasks. MedForge shows strong performance on multiple clinical datasets (e.g., breast cancer, lung cancer, and colon cancer) collected from different institutions. Our major findings highlight the value of collaborative foundation models in advancing multi-center clinical collaboration effectively and cohesively. Our code is publicly available at https://github.com/TanZheling/MedForge.
Lost in Translation: Latent Concept Misalignment in Text-to-Image Diffusion Models
Aug 05, 2024Advancements in text-to-image diffusion models have broadened extensive downstream practical applications, but such models often encounter misalignment issues between text and image. Taking the generation of a combination of two disentangled concepts as an example, say given the prompt "a tea cup of iced coke", existing models usually generate a glass cup of iced coke because the iced coke usually co-occurs with the glass cup instead of the tea one during model training. The root of such misalignment is attributed to the confusion in the latent semantic space of text-to-image diffusion models, and hence we refer to the "a tea cup of iced coke" phenomenon as Latent Concept Misalignment (LC-Mis). We leverage large language models (LLMs) to thoroughly investigate the scope of LC-Mis, and develop an automated pipeline for aligning the latent semantics of diffusion models to text prompts. Empirical assessments confirm the effectiveness of our approach, substantially reducing LC-Mis errors and enhancing the robustness and versatility of text-to-image diffusion models. The code and dataset are here: https://github.com/RossoneriZhao/iced_coke.