 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Before You Move: Latent Motion Reasoning for Text-to-Motion Generation
Dec 30, 2025Current state-of-the-art paradigms predominantly treat Text-to-Motion (T2M) generation as a direct translation problem, mapping symbolic language directly to continuous poses. While effective for simple actions, this System 1 approach faces a fundamental theoretical bottleneck we identify as the Semantic-Kinematic Impedance Mismatch: the inherent difficulty of grounding semantically dense, discrete linguistic intent into kinematically dense, high-frequency motion data in a single shot. In this paper, we argue that the solution lies in an architectural shift towards Latent System 2 Reasoning. Drawing inspiration from Hierarchical Motor Control in cognitive science, we propose Latent Motion Reasoning (LMR) that reformulates generation as a two-stage Think-then-Act decision process. Central to LMR is a novel Dual-Granularity Tokenizer that disentangles motion into two distinct manifolds: a compressed, semantically rich Reasoning Latent for planning global topology, and a high-frequency Execution Latent for preserving physical fidelity. By forcing the model to autoregressively reason (plan the coarse trajectory) before it moves (instantiates the frames), we effectively bridge the ineffability gap between language and physics. We demonstrate LMR's versatility by implementing it for two representative baselines: T2M-GPT (discrete) and MotionStreamer (continuous). Extensive experiments show that LMR yields non-trivial improvements in both semantic alignment and physical plausibility, validating that the optimal substrate for motion planning is not natural language, but a learned, motion-aligned concept space. Codes and demos can be found in \hyperlink{https://chenhaoqcdyq.github.io/LMR/}{https://chenhaoqcdyq.github.io/LMR/}
TravelBench: A Real-World Benchmark for Multi-Turn and Tool-Augmented Travel Planning
Dec 27, 2025Large language model (LLM) agents have demonstrated strong capabilities in planning and tool use. Travel planning provides a natural and high-impact testbed for these capabilities, as it requires multi-step reasoning, iterative preference elicitation through interaction, and calls to external tools under evolving constraints. Prior work has studied LLMs on travel-planning tasks, but existing settings are limited in domain coverage and multi-turn interaction. As a result, they cannot support dynamic user-agent interaction and therefore fail to comprehensively assess agent capabilities. In this paper, we introduce TravelBench, a real-world travel-planning benchmark featuring multi-turn interaction and tool use. We collect user requests from real-world scenarios and construct three subsets-multi-turn, single-turn, and unsolvable-to evaluate different aspects of agent performance. For stable and reproducible evaluation, we build a controlled sandbox environment with 10 travel-domain tools, providing deterministic tool outputs for reliable reasoning. We evaluate multiple LLMs on TravelBench and conduct an analysis of their behaviors and performance. TravelBench offers a practical and reproducible benchmark for advancing LLM agents in travel planning.
Secure and Explainable Fraud Detection in Finance via Hierarchical Multi-source Dataset Distillation
Dec 26, 2025We propose an explainable, privacy-preserving dataset distillation framework for collaborative financial fraud detection. A trained random forest is converted into transparent, axis-aligned rule regions (leaf hyperrectangles), and synthetic transactions are generated by uniformly sampling within each region. This produces a compact, auditable surrogate dataset that preserves local feature interactions without exposing sensitive original records. The rule regions also support explainability: aggregated rule statistics (for example, support and lift) describe global patterns, while assigning each case to its generating region gives concise human-readable rationales and calibrated uncertainty based on tree-vote disagreement. On the IEEE-CIS fraud dataset (590k transactions across three institution-like clusters), distilled datasets reduce data volume by 85% to 93% (often under 15% of the original) while maintaining competitive precision and micro-F1, with only a modest AUC drop. Sharing and augmenting with synthesized data across institutions improves cross-cluster precision, recall, and AUC. Real vs. synthesized structure remains highly similar (over 93% by nearest-neighbor cosine analysis). Membership-inference attacks perform at chance level (about 0.50) when distinguishing training from hold-out records, suggesting low memorization risk. Removing high-uncertainty synthetic points using disagreement scores further boosts AUC (up to 0.687) and improves calibration. Sensitivity tests show weak dependence on the distillation ratio (AUC about 0.641 to 0.645 from 6% to 60%). Overall, tree-region distillation enables trustworthy, deployable fraud analytics with interpretable global rules, per-case rationales with quantified uncertainty, and strong privacy properties suitable for multi-institution settings and regulatory audit.
UltraLBM-UNet: Ultralight Bidirectional Mamba-based Model for Skin Lesion Segmentation
Dec 25, 2025Skin lesion segmentation is a crucial step in dermatology for guiding clinical decision-making. However, existing methods for accurate, robust, and resource-efficient lesion analysis have limitations, including low performance and high computational complexity. To address these limitations, we propose UltraLBM-UNet, a lightweight U-Net variant that integrates a bidirectional Mamba-based global modeling mechanism with multi-branch local feature perception. The proposed architecture integrates efficient local feature injection with bidirectional state-space modeling, enabling richer contextual interaction across spatial dimensions while maintaining computational compactness suitable for point-of-care deployment. Extensive experiments on the ISIC 2017, ISIC 2018, and PH2 datasets demonstrate that our model consistently achieves state-of-the-art segmentation accuracy, outperforming existing lightweight and Mamba counterparts with only 0.034M parameters and 0.060 GFLOPs. In addition, we introduce a hybrid knowledge distillation strategy to train an ultra-compact student model, where the distilled variant UltraLBM-UNet-T, with only 0.011M parameters and 0.019 GFLOPs, achieves competitive segmentation performance. These results highlight the suitability of UltraLBM-UNet for point-of-care deployment, where accurate and robust lesion analyses are essential. The source code is publicly available at https://github.com/LinLinLin-X/UltraLBM-UNet.
The Procrustean Bed of Time Series: The Optimization Bias of Point-wise Loss
Dec 21, 2025



Optimizing time series models via point-wise loss functions (e.g., MSE) relying on a flawed point-wise independent and identically distributed (i.i.d.) assumption that disregards the causal temporal structure, an issue with growing awareness yet lacking formal theoretical grounding. Focusing on the core independence issue under covariance stationarity, this paper aims to provide a first-principles analysis of the Expectation of Optimization Bias (EOB), formalizing it information-theoretically as the discrepancy between the true joint distribution and its flawed i.i.d. counterpart. Our analysis reveals a fundamental paradigm paradox: the more deterministic and structured the time series, the more severe the bias by point-wise loss function. We derive the first closed-form quantification for the non-deterministic EOB across linear and non-linear systems, and prove EOB is an intrinsic data property, governed exclusively by sequence length and our proposed Structural Signal-to-Noise Ratio (SSNR). This theoretical diagnosis motivates our principled debiasing program that eliminates the bias through sequence length reduction and structural orthogonalization. We present a concrete solution that simultaneously achieves both principles via DFT or DWT. Furthermore, a novel harmonized $\ell_p$ norm framework is proposed to rectify gradient pathologies of high-variance series. Extensive experiments validate EOB Theory's generality and the superior performance of debiasing program.
FuXi-$γ$: Efficient Sequential Recommendation with Exponential-Power Temporal Encoder and Diagonal-Sparse Positional Mechanism
Dec 14, 2025Sequential recommendation aims to model users' evolving preferences based on their historical interactions. Recent advances leverage Transformer-based architectures to capture global dependencies, but existing methods often suffer from high computational overhead, primarily due to discontinuous memory access in temporal encoding and dense attention over long sequences. To address these limitations, we propose FuXi-$γ$, a novel sequential recommendation framework that improves both effectiveness and efficiency through principled architectural design. FuXi-$γ$ adopts a decoder-only Transformer structure and introduces two key innovations: (1) An exponential-power temporal encoder that encodes relative temporal intervals using a tunable exponential decay function inspired by the Ebbinghaus forgetting curve. This encoder enables flexible modeling of both short-term and long-term preferences while maintaining high efficiency through continuous memory access and pure matrix operations. (2) A diagonal-sparse positional mechanism that prunes low-contribution attention blocks using a diagonal-sliding strategy guided by the persymmetry of Toeplitz matrix. Extensive experiments on four real-world datasets demonstrate that FuXi-$γ$ achieves state-of-the-art performance in recommendation quality, while accelerating training by up to 4.74$\times$ and inference by up to 6.18$\times$, making it a practical and scalable solution for long-sequence recommendation. Our code is available at https://github.com/Yeedzhi/FuXi-gamma.
TR-Gaussians: High-fidelity Real-time Rendering of Planar Transmission and Reflection with 3D Gaussian Splatting
Nov 17, 2025We propose Transmission-Reflection Gaussians (TR-Gaussians), a novel 3D-Gaussian-based representation for high-fidelity rendering of planar transmission and reflection, which are ubiquitous in indoor scenes. Our method combines 3D Gaussians with learnable reflection planes that explicitly model the glass planes with view-dependent reflectance strengths. Real scenes and transmission components are modeled by 3D Gaussians and the reflection components are modeled by the mirrored Gaussians with respect to the reflection plane. The transmission and reflection components are blended according to a Fresnel-based, view-dependent weighting scheme, allowing for faithful synthesis of complex appearance effects under varying viewpoints. To effectively optimize TR-Gaussians, we develop a multi-stage optimization framework incorporating color and geometry constraints and an opacity perturbation mechanism. Experiments on different datasets demonstrate that TR-Gaussians achieve real-time, high-fidelity novel view synthesis in scenes with planar transmission and reflection, and outperform state-of-the-art approaches both quantitatively and qualitatively.
FOCUS: Efficient Keyframe Selection for Long Video Understanding
Oct 31, 2025Multimodal large language models (MLLMs) represent images and video frames as visual tokens. Scaling from single images to hour-long videos, however, inflates the token budget far beyond practical limits. Popular pipelines therefore either uniformly subsample or apply keyframe selection with retrieval-style scoring using smaller vision-language models. However, these keyframe selection methods still rely on pre-filtering before selection to reduce the inference cost and can miss the most informative moments. We propose FOCUS, Frame-Optimistic Confidence Upper-bound Selection, a training-free, model-agnostic keyframe selection module that selects query-relevant frames under a strict token budget. FOCUS formulates keyframe selection as a combinatorial pure-exploration (CPE) problem in multi-armed bandits: it treats short temporal clips as arms, and uses empirical means and Bernstein confidence radius to identify informative regions while preserving exploration of uncertain areas. The resulting two-stage exploration-exploitation procedure reduces from a sequential policy with theoretical guarantees, first identifying high-value temporal regions, then selecting top-scoring frames within each region On two long-video question-answering benchmarks, FOCUS delivers substantial accuracy improvements while processing less than 2% of video frames. For videos longer than 20 minutes, it achieves an 11.9% gain in accuracy on LongVideoBench, demonstrating its effectiveness as a keyframe selection method and providing a simple and general solution for scalable long-video understanding with MLLMs.
Towards Fine-Grained Vision-Language Alignment for Few-Shot Anomaly Detection
Oct 30, 2025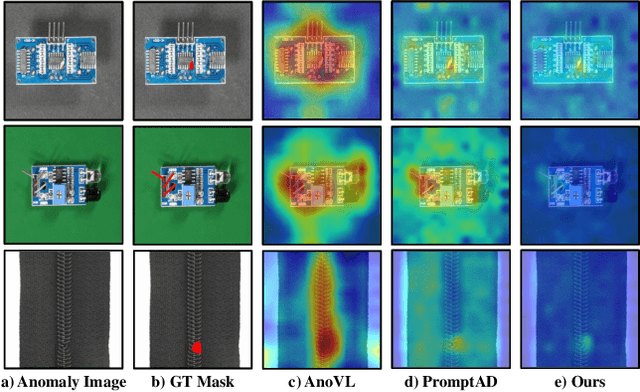
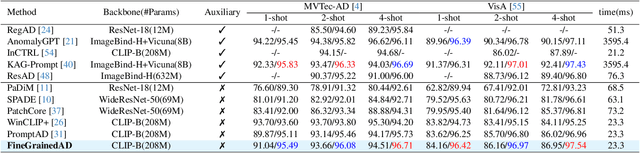
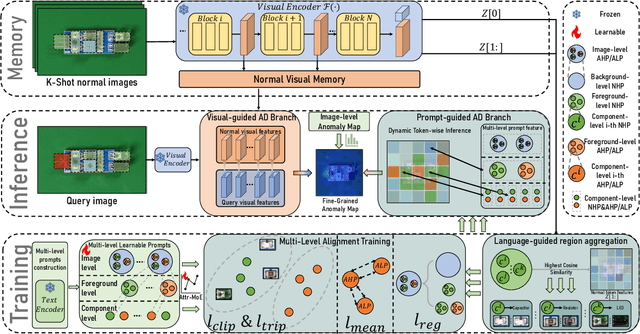
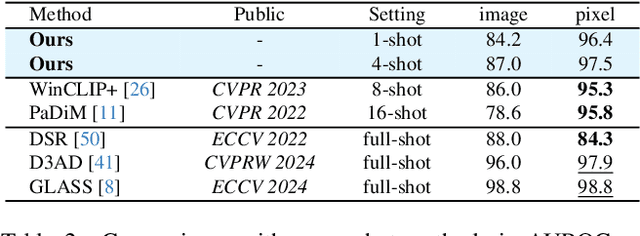
Few-shot anomaly detection (FSAD) methods identify anomalous regions with few known normal samples. Most existing methods rely on the generalization ability of pre-trained vision-language models (VLMs) to recognize potentially anomalous regions through feature similarity between text descriptions and images. However, due to the lack of detailed textual descriptions, these methods can only pre-define image-level descriptions to match each visual patch token to identify potential anomalous regions, which leads to the semantic misalignment between image descriptions and patch-level visual anomalies, achieving sub-optimal localization performance. To address the above issues, we propose the Multi-Level Fine-Grained Semantic Caption (MFSC) to provide multi-level and fine-grained textual descriptions for existing anomaly detection datasets with automatic construction pipeline. Based on the MFSC, we propose a novel framework named FineGrainedAD to improve anomaly localization performance, which consists of two components: Multi-Level Learnable Prompt (MLLP) and Multi-Level Semantic Alignment (MLSA). MLLP introduces fine-grained semantics into multi-level learnable prompts through automatic replacement and concatenation mechanism, while MLSA designs region aggregation strategy and multi-level alignment training to facilitate learnable prompts better align with corresponding visual regions. Experiments demonstrate that the proposed FineGrainedAD achieves superior overall performance in few-shot settings on MVTec-AD and VisA datasets.
Doc-Researcher: A Unified System for Multimodal Document Parsing and Deep Research
Oct 24, 2025Deep Research systems have revolutionized how LLMs solve complex questions through iterative reasoning and evidence gathering. However, current systems remain fundamentally constrained to textual web data, overlooking the vast knowledge embedded in multimodal documents Processing such documents demands sophisticated parsing to preserve visual semantics (figures, tables, charts, and equations), intelligent chunking to maintain structural coherence, and adaptive retrieval across modalities, which are capabilities absent in existing systems. In response, we present Doc-Researcher, a unified system that bridges this gap through three integrated components: (i) deep multimodal parsing that preserves layout structure and visual semantics while creating multi-granular representations from chunk to document level, (ii) systematic retrieval architecture supporting text-only, vision-only, and hybrid paradigms with dynamic granularity selection, and (iii) iterative multi-agent workflows that decompose complex queries, progressively accumulate evidence, and synthesize comprehensive answers across documents and modalities. To enable rigorous evaluation, we introduce M4DocBench, the first benchmark for Multi-modal, Multi-hop, Multi-document, and Multi-turn deep research. Featuring 158 expert-annotated questions with complete evidence chains across 304 documents, M4DocBench tests capabilities that existing benchmarks cannot assess. Experiments demonstrate that Doc-Researcher achieves 50.6% accuracy, 3.4xbetter than state-of-the-art baselines, validating that effective document research requires not just better retrieval, but fundamentally deep parsing that preserve multimodal integrity and support iterative research. Our work establishes a new paradigm for conducting deep research on multimodal document collections.