 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatchLM2Lite: A Scalable MLLM-to-Lite Framework for Reproduced Content Identification
Jun 10, 2026Content moderation is critical for online video platforms to ensure content safety, protect creators, and sustain positive user experiences. Beyond filtering harmful content, platforms must guarantee content authenticity at scale so that users are exposed to diverse, original videos rather than low-value reproductions. We present MatchLM2Lite, a real-time, production-grade reproduced content identification (RCI) system that leverages the powerful understanding of a multimodal large language model (MLLM) distilled into a small and fast-inference model. Our system jointly models video, audio, and text signals, operating on pairs of videos to produce fine-grained reproduction scores. The system comprises two modules, MatchLM and MatchLite, and a two-stage training recipe. First, our high-capacity MLLM, MatchLM, serves as a teacher model to define the upper bound of RCI performance. Its capabilities are then distilled into a compact student model, MatchLite. This design allows MatchLite to deliver low-latency, high-throughput inference on video pairs while preserving much of MatchLM's accuracy, making it suitable for integration into real-time recommendation systems. MatchLM achieves an F1-score improvement of +8.57 compared to our previous production model. After knowledge distillation, MatchLite retains a +6.55 gain in F1-score while reducing computational cost by 35x. Deployed at scale, MatchLM2Lite enables efficient, pairwise multimodal RCI, stably serving online traffic at high queries per second (QPS) with an end-to-end latency below 30 seconds. This system has reduced the reproduced video view rate on our platform by 2.5% without degrading user engagement, demonstrating its effectiveness in a large-scale production environment.
MLT-Dedup: Efficient Large-Scale Online Video Deduplication via Multi-Level Representations and Spatial-Temporal Matching
Jun 10, 2026The explosive growth of user-generated video content on online platforms is accompanied by the emergence of numerous near-duplicate videos--videos that are identical or highly similar but differ by partial edits. These duplicates degrade user experience and increase storage and bandwidth costs, making large-scale video deduplication a critical task. Existing video deduplication frameworks face a fundamental challenge in retrieving sufficient high-quality candidates under a limited index budget, as well as trade-offs between efficiency and precision. To address these issues, we propose MLT-Dedup, an efficient large-scale online video deduplication framework with Multi-Level representations and spatial-Temporal matching. Our approach employs a Multi-Level Video Encoder (ML-VE) to extract both fine-grained frame-level and sparse clip-level embeddings: sparse embeddings support efficient candidate retrieval, while fine-grained embeddings are loaded for precise pairwise matching. During matching, we introduce DiF-SiM, a Differential Feature-enhanced Similarity Module capable of locating duplicated temporal segments and providing reliable similarity evidence to support policy-driven deduplication decisions. Extensive experiments on a real-world large-scale platform demonstrate that MLT-Dedup reduces online repetition rates by 91% at 90% precision. Furthermore, our sparse retrieval design achieves a 5x increase in indexing capacity, enabling broader candidate coverage in real-world deployment.
CAMEL: Confidence-Gated Reflection for Reward Modeling
Feb 24, 2026Reward models play a fundamental role in aligning large language models with human preferences. Existing methods predominantly follow two paradigms: scalar discriminative preference models, which are efficient but lack interpretability, and generative judging models, which offer richer reasoning at the cost of higher computational overhead. We observe that the log-probability margin between verdict tokens strongly correlates with prediction correctness, providing a reliable proxy for instance difficulty without additional inference cost. Building on this insight, we propose CAMEL, a confidence-gated reflection framework that performs a lightweight single-token preference decision first and selectively invokes reflection only for low-confidence instances. To induce effective self-correction, we train the model via reinforcement learning with counterfactual prefix augmentation, which exposes the model to diverse initial verdicts and encourages genuine revision. Empirically, CAMEL achieves state-of-the-art performance on three widely used reward-model benchmarks with 82.9% average accuracy, surpassing the best prior model by 3.2% and outperforming 70B-parameter models using only 14B parameters, while establishing a strictly better accuracy-efficiency Pareto frontier.
FOCUS: Efficient Keyframe Selection for Long Video Understanding
Oct 31, 2025Multimodal large language models (MLLMs) represent images and video frames as visual tokens. Scaling from single images to hour-long videos, however, inflates the token budget far beyond practical limits. Popular pipelines therefore either uniformly subsample or apply keyframe selection with retrieval-style scoring using smaller vision-language models. However, these keyframe selection methods still rely on pre-filtering before selection to reduce the inference cost and can miss the most informative moments. We propose FOCUS, Frame-Optimistic Confidence Upper-bound Selection, a training-free, model-agnostic keyframe selection module that selects query-relevant frames under a strict token budget. FOCUS formulates keyframe selection as a combinatorial pure-exploration (CPE) problem in multi-armed bandits: it treats short temporal clips as arms, and uses empirical means and Bernstein confidence radius to identify informative regions while preserving exploration of uncertain areas. The resulting two-stage exploration-exploitation procedure reduces from a sequential policy with theoretical guarantees, first identifying high-value temporal regions, then selecting top-scoring frames within each region On two long-video question-answering benchmarks, FOCUS delivers substantial accuracy improvements while processing less than 2% of video frames. For videos longer than 20 minutes, it achieves an 11.9% gain in accuracy on LongVideoBench, demonstrating its effectiveness as a keyframe selection method and providing a simple and general solution for scalable long-video understanding with MLLMs.
Info-Coevolution: An Efficient Framework for Data Model Coevolution
Jun 09, 2025



Machine learning relies heavily on data, yet the continuous growth of real-world data poses challenges for efficient dataset construction and training. A fundamental yet unsolved question is: given our current model and data, does a new data (sample/batch) need annotation/learning? Conventional approaches retain all available data, leading to non-optimal data and training efficiency. Active learning aims to reduce data redundancy by selecting a subset of samples to annotate, while it increases pipeline complexity and introduces bias. In this work, we propose Info-Coevolution, a novel framework that efficiently enables models and data to coevolve through online selective annotation with no bias. Leveraging task-specific models (and open-source models), it selectively annotates and integrates online and web data to improve datasets efficiently. For real-world datasets like ImageNet-1K, Info-Coevolution reduces annotation and training costs by 32\% without performance loss. It is able to automatically give the saving ratio without tuning the ratio. It can further reduce the annotation ratio to 50\% with semi-supervised learning. We also explore retrieval-based dataset enhancement using unlabeled open-source data. Code is available at https://github.com/NUS-HPC-AI-Lab/Info-Coevolution/.
* V1
Pure and Hybrid Evolutionary Computing in Global Optimization of Chemical Structures: from Atoms and Molecules to Clusters and Crystals
Aug 31, 2015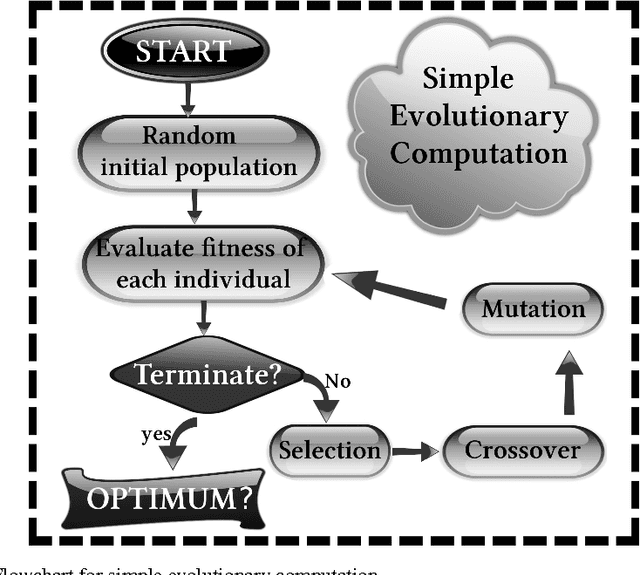
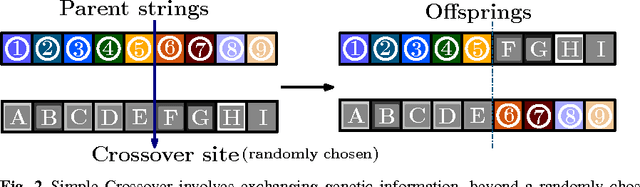
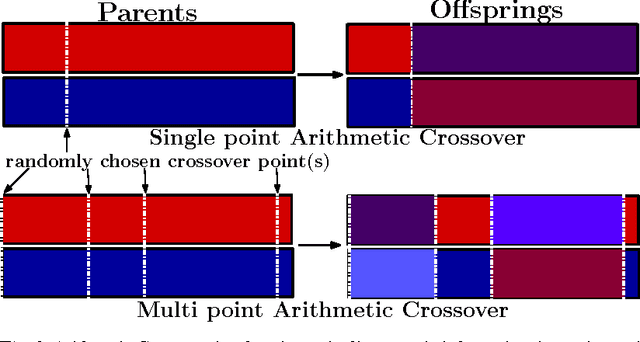

The growth of evolutionary computing (EC) methods in the exploration of complex potential energy landscapes of atomic and molecular clusters, as well as crystals over the last decade or so is reviewed. The trend of growth indicates that pure as well as hybrid evolutionary computing techniques in conjunction of DFT has been emerging as a powerful tool, although work on molecular clusters has been rather limited so far. Some attempts to solve the atomic/molecular Schrodinger Equation (SE) directly by genetic algorithms (GA) are available in literature. At the Born-Oppenheimer level of approximation GA-density methods appear to be a viable tool which could be more extensively explored in the coming years, specially in the context of designing molecules and materials with targeted properties.