 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStoryBlender: Inter-Shot Consistent and Editable 3D Storyboard with Spatial-temporal Dynamics
Apr 01, 2026Storyboarding is a core skill in visual storytelling for film, animation, and games. However, automating this process requires a system to achieve two properties that current approaches rarely satisfy simultaneously: inter-shot consistency and explicit editability. While 2D diffusion-based generators produce vivid imagery, they often suffer from identity drift along with limited geometric control; conversely, traditional 3D animation workflows are consistent and editable but require expert-heavy, labor-intensive authoring. We present StoryBlender, a grounded 3D storyboard generation framework governed by a Story-centric Reflection Scheme. At its core, we propose the StoryBlender system, which is built on a three-stage pipeline: (1) Semantic-Spatial Grounding, to construct a continuity memory graph to decouple global assets from shot-specific variables for long-horizon consistency; (2) Canonical Asset Materialization, to instantiate entities in a unified coordinate space to maintain visual identity; and (3) Spatial-Temporal Dynamics, to achieve layout design and cinematic evolution through visual metrics. By orchestrating multiple agents in a hierarchical manner within a verification loop, StoryBlender iteratively self-corrects spatial hallucinations via engine-verified feedback. The resulting native 3D scenes support direct, precise editing of cameras and visual assets while preserving unwavering multi-shot continuity. Experiments demonstrate that StoryBlender significantly improves consistency and editability over both diffusion-based and 3D-grounded baselines. Code, data, and demonstration video will be available on https://engineeringai-lab.github.io/StoryBlender/
i-PhysGaussian: Implicit Physical Simulation for 3D Gaussian Splatting
Feb 19, 2026Physical simulation predicts future states of objects based on material properties and external loads, enabling blueprints for both Industry and Engineering to conduct risk management. Current 3D reconstruction-based simulators typically rely on explicit, step-wise updates, which are sensitive to step time and suffer from rapid accuracy degradation under complicated scenarios, such as high-stiffness materials or quasi-static movement. To address this, we introduce i-PhysGaussian, a framework that couples 3D Gaussian Splatting (3DGS) with an implicit Material Point Method (MPM) integrator. Unlike explicit methods, our solution obtains an end-of-step state by minimizing a momentum-balance residual through implicit Newton-type optimization with a GMRES solver. This formulation significantly reduces time-step sensitivity and ensures physical consistency. Our results demonstrate that i-PhysGaussian maintains stability at up to 20x larger time steps than explicit baselines, preserving structural coherence and smooth motion even in complex dynamic transitions.
3DXTalker: Unifying Identity, Lip Sync, Emotion, and Spatial Dynamics in Expressive 3D Talking Avatars
Feb 12, 2026Audio-driven 3D talking avatar generation is increasingly important in virtual communication, digital humans, and interactive media, where avatars must preserve identity, synchronize lip motion with speech, express emotion, and exhibit lifelike spatial dynamics, collectively defining a broader objective of expressivity. However, achieving this remains challenging due to insufficient training data with limited subject identities, narrow audio representations, and restricted explicit controllability. In this paper, we propose 3DXTalker, an expressive 3D talking avatar through data-curated identity modeling, audio-rich representations, and spatial dynamics controllability. 3DXTalker enables scalable identity modeling via 2D-to-3D data curation pipeline and disentangled representations, alleviating data scarcity and improving identity generalization. Then, we introduce frame-wise amplitude and emotional cues beyond standard speech embeddings, ensuring superior lip synchronization and nuanced expression modulation. These cues are unified by a flow-matching-based transformer for coherent facial dynamics. Moreover, 3DXTalker also enables natural head-pose motion generation while supporting stylized control via prompt-based conditioning. Extensive experiments show that 3DXTalker integrates lip synchronization, emotional expression, and head-pose dynamics within a unified framework, achieves superior performance in 3D talking avatar generation.
Beyond the Dirac Delta: Mitigating Diversity Collapse in Reinforcement Fine-Tuning for Versatile Image Generation
Jan 18, 2026Reinforcement learning (RL) has emerged as a powerful paradigm for fine-tuning large-scale generative models, such as diffusion and flow models, to align with complex human preferences and user-specified tasks. A fundamental limitation remains \textit{the curse of diversity collapse}, where the objective formulation and optimization landscape inherently collapse the policy to a Dirac delta distribution. To address this challenge, we propose \textbf{DRIFT} (\textbf{D}ive\textbf{R}sity-\textbf{I}ncentivized Reinforcement \textbf{F}ine-\textbf{T}uning for Versatile Image Generation), an innovative framework that systematically incentivizes output diversity throughout the on-policy fine-tuning process, reconciling strong task alignment with high generation diversity to enhance versatility essential for applications that demand diverse candidate generations. We approach the problem across three representative perspectives: i) \textbf{sampling} a reward-concentrated subset that filters out reward outliers to prevent premature collapse; ii) \textbf{prompting} with stochastic variations to expand the conditioning space, and iii) \textbf{optimization} of the intra-group diversity with a potential-based reward shaping mechanism. Experimental results show that DRIFT achieves superior Pareto dominance regarding task alignment and generation diversity, yielding a $ 9.08\%\!\sim\! 43.46\%$ increase in diversity at equivalent alignment levels and a $ 59.65\% \!\sim\! 65.86\%$ increase in alignment at equivalent levels of diversity.
The Procrustean Bed of Time Series: The Optimization Bias of Point-wise Loss
Dec 21, 2025



Optimizing time series models via point-wise loss functions (e.g., MSE) relying on a flawed point-wise independent and identically distributed (i.i.d.) assumption that disregards the causal temporal structure, an issue with growing awareness yet lacking formal theoretical grounding. Focusing on the core independence issue under covariance stationarity, this paper aims to provide a first-principles analysis of the Expectation of Optimization Bias (EOB), formalizing it information-theoretically as the discrepancy between the true joint distribution and its flawed i.i.d. counterpart. Our analysis reveals a fundamental paradigm paradox: the more deterministic and structured the time series, the more severe the bias by point-wise loss function. We derive the first closed-form quantification for the non-deterministic EOB across linear and non-linear systems, and prove EOB is an intrinsic data property, governed exclusively by sequence length and our proposed Structural Signal-to-Noise Ratio (SSNR). This theoretical diagnosis motivates our principled debiasing program that eliminates the bias through sequence length reduction and structural orthogonalization. We present a concrete solution that simultaneously achieves both principles via DFT or DWT. Furthermore, a novel harmonized $\ell_p$ norm framework is proposed to rectify gradient pathologies of high-variance series. Extensive experiments validate EOB Theory's generality and the superior performance of debiasing program.
Conditional Diffusion Model for Multi-Agent Dynamic Task Decomposition
Nov 17, 2025Task decomposition has shown promise in complex cooperative multi-agent reinforcement learning (MARL) tasks, which enables efficient hierarchical learning for long-horizon tasks in dynamic and uncertain environments. However, learning dynamic task decomposition from scratch generally requires a large number of training samples, especially exploring the large joint action space under partial observability. In this paper, we present the Conditional Diffusion Model for Dynamic Task Decomposition (C$\text{D}^\text{3}$T), a novel two-level hierarchical MARL framework designed to automatically infer subtask and coordination patterns. The high-level policy learns subtask representation to generate a subtask selection strategy based on subtask effects. To capture the effects of subtasks on the environment, C$\text{D}^\text{3}$T predicts the next observation and reward using a conditional diffusion model. At the low level, agents collaboratively learn and share specialized skills within their assigned subtasks. Moreover, the learned subtask representation is also used as additional semantic information in a multi-head attention mixing network to enhance value decomposition and provide an efficient reasoning bridge between individual and joint value functions. Experimental results on various benchmarks demonstrate that C$\text{D}^\text{3}$T achieves better performance than existing baselines.
QiNN-QJ: A Quantum-inspired Neural Network with Quantum Jump for Multimodal Sentiment Analysis
Oct 31, 2025Quantum theory provides non-classical principles, such as superposition and entanglement, that inspires promising paradigms in machine learning. However, most existing quantum-inspired fusion models rely solely on unitary or unitary-like transformations to generate quantum entanglement. While theoretically expressive, such approaches often suffer from training instability and limited generalizability. In this work, we propose a Quantum-inspired Neural Network with Quantum Jump (QiNN-QJ) for multimodal entanglement modelling. Each modality is firstly encoded as a quantum pure state, after which a differentiable module simulating the QJ operator transforms the separable product state into the entangled representation. By jointly learning Hamiltonian and Lindblad operators, QiNN-QJ generates controllable cross-modal entanglement among modalities with dissipative dynamics, where structured stochasticity and steady-state attractor properties serve to stabilize training and constrain entanglement shaping. The resulting entangled states are projected onto trainable measurement vectors to produce predictions. In addition to achieving superior performance over the state-of-the-art models on benchmark datasets, including CMU-MOSI, CMU-MOSEI, and CH-SIMS, QiNN-QJ facilitates enhanced post-hoc interpretability through von-Neumann entanglement entropy. This work establishes a principled framework for entangled multimodal fusion and paves the way for quantum-inspired approaches in modelling complex cross-modal correlations.
Listwise Preference Alignment Optimization for Tail Item Recommendation
Jul 03, 2025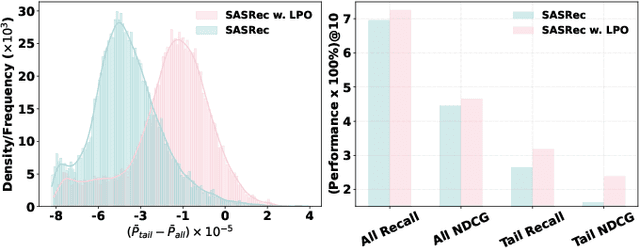
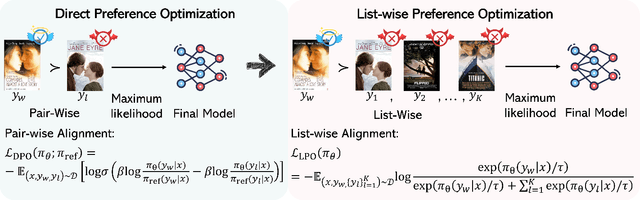
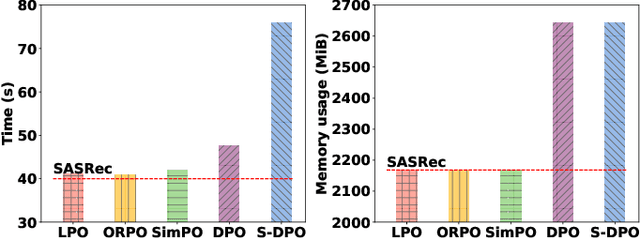
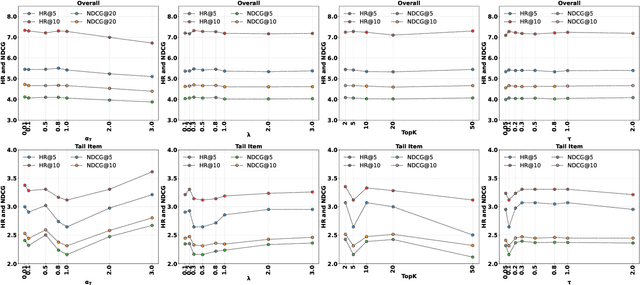
Preference alignment has achieved greater success on Large Language Models (LLMs) and drawn broad interest in recommendation research. Existing preference alignment methods for recommendation either require explicit reward modeling or only support pairwise preference comparison. The former directly increases substantial computational costs, while the latter hinders training efficiency on negative samples. Moreover, no existing effort has explored preference alignment solutions for tail-item recommendation. To bridge the above gaps, we propose LPO4Rec, which extends the Bradley-Terry model from pairwise comparison to listwise comparison, to improve the efficiency of model training. Specifically, we derive a closed form optimal policy to enable more efficient and effective training without explicit reward modeling. We also present an adaptive negative sampling and reweighting strategy to prioritize tail items during optimization and enhance performance in tail-item recommendations. Besides, we theoretically prove that optimizing the listwise preference optimization (LPO) loss is equivalent to maximizing the upper bound of the optimal reward. Our experiments on three public datasets show that our method outperforms 10 baselines by a large margin, achieving up to 50% performance improvement while reducing 17.9% GPU memory usage when compared with direct preference optimization (DPO) in tail-item recommendation. Our code is available at https://github.com/Yuhanleeee/LPO4Rec.
Mixture-of-Experts Meets In-Context Reinforcement Learning
Jun 05, 2025In-context reinforcement learning (ICRL) has emerged as a promising paradigm for adapting RL agents to downstream tasks through prompt conditioning. However, two notable challenges remain in fully harnessing in-context learning within RL domains: the intrinsic multi-modality of the state-action-reward data and the diverse, heterogeneous nature of decision tasks. To tackle these challenges, we propose \textbf{T2MIR} (\textbf{T}oken- and \textbf{T}ask-wise \textbf{M}oE for \textbf{I}n-context \textbf{R}L), an innovative framework that introduces architectural advances of mixture-of-experts (MoE) into transformer-based decision models. T2MIR substitutes the feedforward layer with two parallel layers: a token-wise MoE that captures distinct semantics of input tokens across multiple modalities, and a task-wise MoE that routes diverse tasks to specialized experts for managing a broad task distribution with alleviated gradient conflicts. To enhance task-wise routing, we introduce a contrastive learning method that maximizes the mutual information between the task and its router representation, enabling more precise capture of task-relevant information. The outputs of two MoE components are concatenated and fed into the next layer. Comprehensive experiments show that T2MIR significantly facilitates in-context learning capacity and outperforms various types of baselines. We bring the potential and promise of MoE to ICRL, offering a simple and scalable architectural enhancement to advance ICRL one step closer toward achievements in language and vision communities. Our code is available at https://github.com/NJU-RL/T2MIR.
Learning Diverse Natural Behaviors for Enhancing the Agility of Quadrupedal Robots
May 15, 2025Achieving animal-like agility is a longstanding goal in quadrupedal robotics. While recent studies have successfully demonstrated imitation of specific behaviors, enabling robots to replicate a broader range of natural behaviors in real-world environments remains an open challenge. Here we propose an integrated controller comprising a Basic Behavior Controller (BBC) and a Task-Specific Controller (TSC) which can effectively learn diverse natural quadrupedal behaviors in an enhanced simulator and efficiently transfer them to the real world. Specifically, the BBC is trained using a novel semi-supervised generative adversarial imitation learning algorithm to extract diverse behavioral styles from raw motion capture data of real dogs, enabling smooth behavior transitions by adjusting discrete and continuous latent variable inputs. The TSC, trained via privileged learning with depth images as input, coordinates the BBC to efficiently perform various tasks. Additionally, we employ evolutionary adversarial simulator identification to optimize the simulator, aligning it closely with reality. After training, the robot exhibits diverse natural behaviors, successfully completing the quadrupedal agility challenge at an average speed of 1.1 m/s and achieving a peak speed of 3.2 m/s during hurdling. This work represents a substantial step toward animal-like agility in quadrupedal robots, opening avenues for their deployment in increasingly complex real-world environments.