 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Policy Entropy Constraint Fails: Preserving Diversity in Flow-based RLHF via Perceptual Entropy
May 12, 2026RLHF is widely used to align flow-matching text-to-image models with human preferences, but often leads to severe diversity collapse after fine-tuning. In RL, diversity is often assumed to correlate with policy entropy, motivating entropy regularization. However, we show this intuition breaks in flow models: policy entropy remains constant, even while perceptual diversity collapses. We explain this mismatch both theoretically and empirically: the constant entropy arises from the fixed, pre-defined noise schedule, while the diversity collapse is driven by the mode-seeking nature of policy gradients. As a result, policy entropy fails to prevent the model from converging to a narrow high-reward region in the perceptual space. To this end, we introduce perceptual entropy that captures diversity in a perceptual space and maintains the property of standard entropy. Building upon this insight, we propose two entropy-regularized strategies, Perceptual Entropy Constraint and Perceptual Constraints on Generation Space, to preserve perceptual diversity and improve the quality. Experiments across two base models, neural and rule-based rewards, and three perceptual spaces demonstrate consistent gains in the quality-diversity trade-off; PEC achieves the best overall score of 0.734 (vs. baseline's 0.366); a complementary setting of PEC further reaches a diversity average of 0.989 (vs. baseline's 0.047). Our project page (https://xiaofeng-tan.github.io/projects/PEC) is publicly available.
Large-Scale Universal Defect Generation: Foundation Models and Datasets
Apr 10, 2026Existing defect/anomaly generation methods often rely on few-shot learning, which overfits to specific defect categories due to the lack of large-scale paired defect editing data. This issue is aggravated by substantial variations in defect scale and morphology, resulting in limited generalization, degraded realism, and category consistency. We address these challenges by introducing UDG, a large-scale dataset of 300K normal-abnormal-mask-caption quadruplets spanning diverse domains, and by presenting UniDG, a universal defect generation foundation model that supports both reference-based defect generation and text instruction-based defect editing without per-category fine-tuning. UniDG performs Defect-Context Editing via adaptive defect cropping and structured diptych input format, and fuses reference and target conditions through MM-DiT multimodal attention. A two-stage training strategy, Diversity-SFT followed by Consistency-RFT, further improves diversity while enhancing realism and reference consistency. Extensive experiments on MVTec-AD and VisA show that UniDG outperforms prior few-shot anomaly generation and image insertion/editing baselines in synthesis quality and downstream single- and multi-class anomaly detection/localization. Code will be available at https://github.com/RetoFan233/UniDG.
PET-DINO: Unifying Visual Cues into Grounding DINO with Prompt-Enriched Training
Apr 01, 2026Open-Set Object Detection (OSOD) enables recognition of novel categories beyond fixed classes but faces challenges in aligning text representations with complex visual concepts and the scarcity of image-text pairs for rare categories. This results in suboptimal performance in specialized domains or with complex objects. Recent visual-prompted methods partially address these issues but often involve complex multi-modal designs and multi-stage optimizations, prolonging the development cycle. Additionally, effective training strategies for data-driven OSOD models remain largely unexplored. To address these challenges, we propose PET-DINO, a universal detector supporting both text and visual prompts. Our Alignment-Friendly Visual Prompt Generation (AFVPG) module builds upon an advanced text-prompted detector, addressing the limitations of text representation guidance and reducing the development cycle. We introduce two prompt-enriched training strategies: Intra-Batch Parallel Prompting (IBP) at the iteration level and Dynamic Memory-Driven Prompting (DMD) at the overall training level. These strategies enable simultaneous modeling of multiple prompt routes, facilitating parallel alignment with diverse real-world usage scenarios. Comprehensive experiments demonstrate that PET-DINO exhibits competitive zero-shot object detection capabilities across various prompt-based detection protocols. These strengths can be attributed to inheritance-based philosophy and prompt-enriched training strategies, which play a critical role in building an effective generic object detector. Project page: https://fuweifuvtoo.github.io/pet-dino.
Learning Trajectory-Aware Multimodal Large Language Models for Video Reasoning Segmentation
Mar 23, 2026The prosperity of Multimodal Large Language Models (MLLMs) has stimulated the demand for video reasoning segmentation, which aims to segment video objects based on human instructions. Previous studies rely on unidirectional and implicit text-trajectory alignment, which struggles with trajectory perception when faced with severe video dynamics. In this work, we propose TrajSeg, a simple and unified framework built upon MLLMs. Concretely, we introduce bidirectional text-trajectory alignment, where MLLMs accept grounding-intended (text-to-trajectory) and captioning-intended (trajectory-to-text) instructions. This way, MLLMs can benefit from enhanced correspondence and better perceive object trajectories in videos. The mask generation from trajectories is achieved via a frame-level content integration (FCI) module and a unified mask decoder. The former adapts the MLLM-parsed trajectory-level token to frame-specific information. The latter unifies segmentation for all frames into a single structure, enabling the proposed framework to be simplified and end-to-end trainable. Extensive experiments on referring and reasoning video segmentation datasets demonstrate the effectiveness of TrajSeg, which outperforms all video reasoning segmentation methods on all metrics. The code will be publicly available at https://github.com/haodi19/TrajSeg.
AD-Copilot: A Vision-Language Assistant for Industrial Anomaly Detection via Visual In-context Comparison
Mar 14, 2026Multimodal Large Language Models (MLLMs) have achieved impressive success in natural visual understanding, yet they consistently underperform in industrial anomaly detection (IAD). This is because MLLMs trained mostly on general web data differ significantly from industrial images. Moreover, they encode each image independently and can only compare images in the language space, making them insensitive to subtle visual differences that are key to IAD. To tackle these issues, we present AD-Copilot, an interactive MLLM specialized for IAD via visual in-context comparison. We first design a novel data curation pipeline to mine inspection knowledge from sparsely labeled industrial images and generate precise samples for captioning, VQA, and defect localization, yielding a large-scale multimodal dataset Chat-AD rich in semantic signals for IAD. On this foundation, AD-Copilot incorporates a novel Comparison Encoder that employs cross-attention between paired image features to enhance multi-image fine-grained perception, and is trained with a multi-stage strategy that incorporates domain knowledge and gradually enhances IAD skills. In addition, we introduce MMAD-BBox, an extended benchmark for anomaly localization with bounding-box-based evaluation. The experiments show that AD-Copilot achieves 82.3% accuracy on the MMAD benchmark, outperforming all other models without any data leakage. In the MMAD-BBox test, it achieves a maximum improvement of $3.35\times$ over the baseline. AD-Copilot also exhibits excellent generalization of its performance gains across other specialized and general-purpose benchmarks. Remarkably, AD-Copilot surpasses human expert-level performance on several IAD tasks, demonstrating its potential as a reliable assistant for real-world industrial inspection. All datasets and models will be released for the broader benefit of the community.
ConsistentRFT: Reducing Visual Hallucinations in Flow-based Reinforcement Fine-Tuning
Feb 03, 2026Reinforcement Fine-Tuning (RFT) on flow-based models is crucial for preference alignment. However, they often introduce visual hallucinations like over-optimized details and semantic misalignment. This work preliminarily explores why visual hallucinations arise and how to reduce them. We first investigate RFT methods from a unified perspective, and reveal the core problems stemming from two aspects, exploration and exploitation: (1) limited exploration during stochastic differential equation (SDE) rollouts, leading to an over-emphasis on local details at the expense of global semantics, and (2) trajectory imitation process inherent in policy gradient methods, distorting the model's foundational vector field and its cross-step consistency. Building on this, we propose ConsistentRFT, a general framework to mitigate these hallucinations. Specifically, we design a Dynamic Granularity Rollout (DGR) mechanism to balance exploration between global semantics and local details by dynamically scheduling different noise sources. We then introduce a Consistent Policy Gradient Optimization (CPGO) that preserves the model's consistency by aligning the current policy with a more stable prior. Extensive experiments demonstrate that ConsistentRFT significantly mitigates visual hallucinations, achieving average reductions of 49\% for low-level and 38\% for high-level perceptual hallucinations. Furthermore, ConsistentRFT outperforms other RFT methods on out-of-domain metrics, showing an improvement of 5.1\% (v.s. the baseline's decrease of -0.4\%) over FLUX1.dev. This is \href{https://xiaofeng-tan.github.io/projects/ConsistentRFT}{Project Page}.
Towards Fine-Grained Vision-Language Alignment for Few-Shot Anomaly Detection
Oct 30, 2025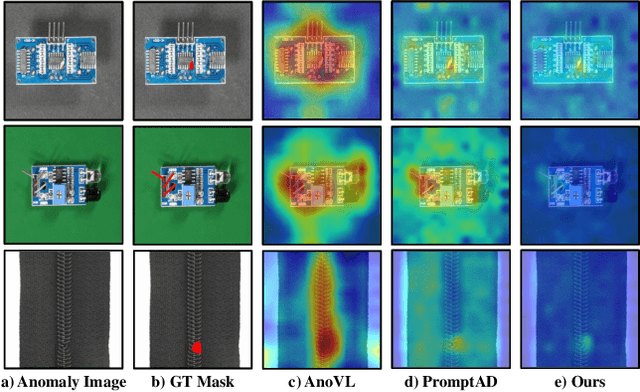
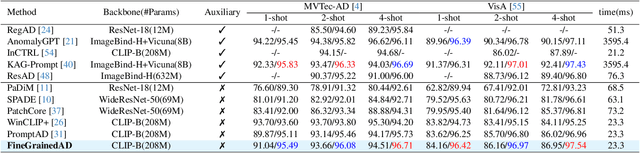
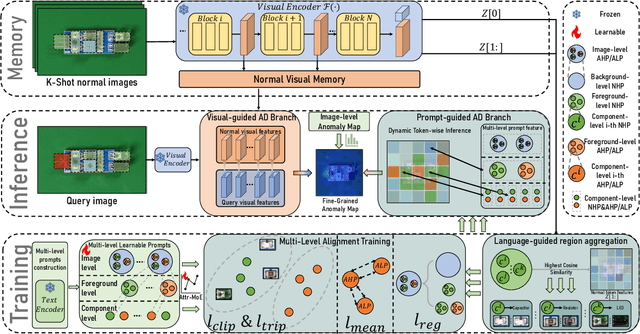
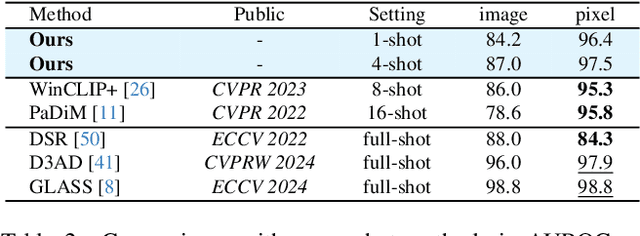
Few-shot anomaly detection (FSAD) methods identify anomalous regions with few known normal samples. Most existing methods rely on the generalization ability of pre-trained vision-language models (VLMs) to recognize potentially anomalous regions through feature similarity between text descriptions and images. However, due to the lack of detailed textual descriptions, these methods can only pre-define image-level descriptions to match each visual patch token to identify potential anomalous regions, which leads to the semantic misalignment between image descriptions and patch-level visual anomalies, achieving sub-optimal localization performance. To address the above issues, we propose the Multi-Level Fine-Grained Semantic Caption (MFSC) to provide multi-level and fine-grained textual descriptions for existing anomaly detection datasets with automatic construction pipeline. Based on the MFSC, we propose a novel framework named FineGrainedAD to improve anomaly localization performance, which consists of two components: Multi-Level Learnable Prompt (MLLP) and Multi-Level Semantic Alignment (MLSA). MLLP introduces fine-grained semantics into multi-level learnable prompts through automatic replacement and concatenation mechanism, while MLSA designs region aggregation strategy and multi-level alignment training to facilitate learnable prompts better align with corresponding visual regions. Experiments demonstrate that the proposed FineGrainedAD achieves superior overall performance in few-shot settings on MVTec-AD and VisA datasets.
Decoupling Classifier for Boosting Few-shot Object Detection and Instance Segmentation
May 20, 2025This paper focus on few-shot object detection~(FSOD) and instance segmentation~(FSIS), which requires a model to quickly adapt to novel classes with a few labeled instances. The existing methods severely suffer from bias classification because of the missing label issue which naturally exists in an instance-level few-shot scenario and is first formally proposed by us. Our analysis suggests that the standard classification head of most FSOD or FSIS models needs to be decoupled to mitigate the bias classification. Therefore, we propose an embarrassingly simple but effective method that decouples the standard classifier into two heads. Then, these two individual heads are capable of independently addressing clear positive samples and noisy negative samples which are caused by the missing label. In this way, the model can effectively learn novel classes while mitigating the effects of noisy negative samples. Without bells and whistles, our model without any additional computation cost and parameters consistently outperforms its baseline and state-of-the-art by a large margin on PASCAL VOC and MS-COCO benchmarks for FSOD and FSIS tasks. The Code is available at https://csgaobb.github.io/Projects/DCFS.
AdaptCLIP: Adapting CLIP for Universal Visual Anomaly Detection
May 15, 2025



Universal visual anomaly detection aims to identify anomalies from novel or unseen vision domains without additional fine-tuning, which is critical in open scenarios. Recent studies have demonstrated that pre-trained vision-language models like CLIP exhibit strong generalization with just zero or a few normal images. However, existing methods struggle with designing prompt templates, complex token interactions, or requiring additional fine-tuning, resulting in limited flexibility. In this work, we present a simple yet effective method called AdaptCLIP based on two key insights. First, adaptive visual and textual representations should be learned alternately rather than jointly. Second, comparative learning between query and normal image prompt should incorporate both contextual and aligned residual features, rather than relying solely on residual features. AdaptCLIP treats CLIP models as a foundational service, adding only three simple adapters, visual adapter, textual adapter, and prompt-query adapter, at its input or output ends. AdaptCLIP supports zero-/few-shot generalization across domains and possesses a training-free manner on target domains once trained on a base dataset. AdaptCLIP achieves state-of-the-art performance on 12 anomaly detection benchmarks from industrial and medical domains, significantly outperforming existing competitive methods. We will make the code and model of AdaptCLIP available at https://github.com/gaobb/AdaptCLIP.
MetaUAS: Universal Anomaly Segmentation with One-Prompt Meta-Learning
May 14, 2025Zero- and few-shot visual anomaly segmentation relies on powerful vision-language models that detect unseen anomalies using manually designed textual prompts. However, visual representations are inherently independent of language. In this paper, we explore the potential of a pure visual foundation model as an alternative to widely used vision-language models for universal visual anomaly segmentation. We present a novel paradigm that unifies anomaly segmentation into change segmentation. This paradigm enables us to leverage large-scale synthetic image pairs, featuring object-level and local region changes, derived from existing image datasets, which are independent of target anomaly datasets. We propose a one-prompt Meta-learning framework for Universal Anomaly Segmentation (MetaUAS) that is trained on this synthetic dataset and then generalizes well to segment any novel or unseen visual anomalies in the real world. To handle geometrical variations between prompt and query images, we propose a soft feature alignment module that bridges paired-image change perception and single-image semantic segmentation. This is the first work to achieve universal anomaly segmentation using a pure vision model without relying on special anomaly detection datasets and pre-trained visual-language models. Our method effectively and efficiently segments any anomalies with only one normal image prompt and enjoys training-free without guidance from language. Our MetaUAS significantly outperforms previous zero-shot, few-shot, and even full-shot anomaly segmentation methods. The code and pre-trained models are available at https://github.com/gaobb/MetaUAS.