 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOP: A Scalable Online Post-Training System for Vision-Language-Action Models
Jan 06, 2026Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training, but real-world deployment requires expert-level task proficiency in addition to broad generality. Existing post-training approaches for VLA models are typically offline, single-robot, or task-specific, limiting effective on-policy adaptation and scalable learning from real-world interaction. We introduce a Scalable Online Post-training (SOP) system that enables online, distributed, multi-task post-training of generalist VLA models directly in the physical world. SOP tightly couples execution and learning through a closed-loop architecture in which a fleet of robots continuously streams on-policy experience and human intervention signals to a centralized cloud learner, and asynchronously receives updated policies. This design supports prompt on-policy correction, scales experience collection through parallel deployment, and preserves generality during adaptation. SOP is agnostic to the choice of post-training algorithm; we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP). Across a range of real-world manipulation tasks including cloth folding, box assembly, and grocery restocking, we show that SOP substantially improves the performance of large pretrained VLA models while maintaining a single shared policy across tasks. Effective post-training can be achieved within hours of real-world interaction, and performance scales near-linearly with the number of robots in the fleet. These results suggest that tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training of generalist robot policies in the physical world.
Let It Flow: Agentic Crafting on Rock and Roll, Building the ROME Model within an Open Agentic Learning Ecosystem
Dec 31, 2025Agentic crafting requires LLMs to operate in real-world environments over multiple turns by taking actions, observing outcomes, and iteratively refining artifacts. Despite its importance, the open-source community lacks a principled, end-to-end ecosystem to streamline agent development. We introduce the Agentic Learning Ecosystem (ALE), a foundational infrastructure that optimizes the production pipeline for agent LLMs. ALE consists of three components: ROLL, a post-training framework for weight optimization; ROCK, a sandbox environment manager for trajectory generation; and iFlow CLI, an agent framework for efficient context engineering. We release ROME (ROME is Obviously an Agentic Model), an open-source agent grounded by ALE and trained on over one million trajectories. Our approach includes data composition protocols for synthesizing complex behaviors and a novel policy optimization algorithm, Interaction-based Policy Alignment (IPA), which assigns credit over semantic interaction chunks rather than individual tokens to improve long-horizon training stability. Empirically, we evaluate ROME within a structured setting and introduce Terminal Bench Pro, a benchmark with improved scale and contamination control. ROME demonstrates strong performance across benchmarks like SWE-bench Verified and Terminal Bench, proving the effectiveness of the ALE infrastructure.
GRL-SNAM: Geometric Reinforcement Learning with Path Differential Hamiltonians for Simultaneous Navigation and Mapping in Unknown Environments
Dec 31, 2025We present GRL-SNAM, a geometric reinforcement learning framework for Simultaneous Navigation and Mapping(SNAM) in unknown environments. A SNAM problem is challenging as it needs to design hierarchical or joint policies of multiple agents that control the movement of a real-life robot towards the goal in mapless environment, i.e. an environment where the map of the environment is not available apriori, and needs to be acquired through sensors. The sensors are invoked from the path learner, i.e. navigator, through active query responses to sensory agents, and along the motion path. GRL-SNAM differs from preemptive navigation algorithms and other reinforcement learning methods by relying exclusively on local sensory observations without constructing a global map. Our approach formulates path navigation and mapping as a dynamic shortest path search and discovery process using controlled Hamiltonian optimization: sensory inputs are translated into local energy landscapes that encode reachability, obstacle barriers, and deformation constraints, while policies for sensing, planning, and reconfiguration evolve stagewise via updating Hamiltonians. A reduced Hamiltonian serves as an adaptive score function, updating kinetic/potential terms, embedding barrier constraints, and continuously refining trajectories as new local information arrives. We evaluate GRL-SNAM on two different 2D navigation tasks. Comparing against local reactive baselines and global policy learning references under identical stagewise sensing constraints, it preserves clearance, generalizes to unseen layouts, and demonstrates that Geometric RL learning via updating Hamiltonians enables high-quality navigation through minimal exploration via local energy refinement rather than extensive global mapping. The code is publicly available on \href{https://github.com/CVC-Lab/GRL-SNAM}{Github}.
GVSynergy-Det: Synergistic Gaussian-Voxel Representations for Multi-View 3D Object Detection
Dec 29, 2025Image-based 3D object detection aims to identify and localize objects in 3D space using only RGB images, eliminating the need for expensive depth sensors required by point cloud-based methods. Existing image-based approaches face two critical challenges: methods achieving high accuracy typically require dense 3D supervision, while those operating without such supervision struggle to extract accurate geometry from images alone. In this paper, we present GVSynergy-Det, a novel framework that enhances 3D detection through synergistic Gaussian-Voxel representation learning. Our key insight is that continuous Gaussian and discrete voxel representations capture complementary geometric information: Gaussians excel at modeling fine-grained surface details while voxels provide structured spatial context. We introduce a dual-representation architecture that: 1) adapts generalizable Gaussian Splatting to extract complementary geometric features for detection tasks, and 2) develops a cross-representation enhancement mechanism that enriches voxel features with geometric details from Gaussian fields. Unlike previous methods that either rely on time-consuming per-scene optimization or utilize Gaussian representations solely for depth regularization, our synergistic strategy directly leverages features from both representations through learnable integration, enabling more accurate object localization. Extensive experiments demonstrate that GVSynergy-Det achieves state-of-the-art results on challenging indoor benchmarks, significantly outperforming existing methods on both ScanNetV2 and ARKitScenes datasets, all without requiring any depth or dense 3D geometry supervision (e.g., point clouds or TSDF).
DS-HGCN: A Dual-Stream Hypergraph Convolutional Network for Predicting Student Engagement via Social Contagion
Dec 23, 2025Student engagement is a critical factor influencing academic success and learning outcomes. Accurately predicting student engagement is essential for optimizing teaching strategies and providing personalized interventions. However, most approaches focus on single-dimensional feature analysis and assessing engagement based on individual student factors. In this work, we propose a dual-stream multi-feature fusion model based on hypergraph convolutional networks (DS-HGCN), incorporating social contagion of student engagement. DS-HGCN enables accurate prediction of student engagement states by modeling multi-dimensional features and their propagation mechanisms between students. The framework constructs a hypergraph structure to encode engagement contagion among students and captures the emotional and behavioral differences and commonalities by multi-frequency signals. Furthermore, we introduce a hypergraph attention mechanism to dynamically weigh the influence of each student, accounting for individual differences in the propagation process. Extensive experiments on public benchmark datasets demonstrate that our proposed method achieves superior performance and significantly outperforms existing state-of-the-art approaches.
Benchmarking neural surrogates on realistic spatiotemporal multiphysics flows
Dec 21, 2025Predicting multiphysics dynamics is computationally expensive and challenging due to the severe coupling of multi-scale, heterogeneous physical processes. While neural surrogates promise a paradigm shift, the field currently suffers from an "illusion of mastery", as repeatedly emphasized in top-tier commentaries: existing evaluations overly rely on simplified, low-dimensional proxies, which fail to expose the models' inherent fragility in realistic regimes. To bridge this critical gap, we present REALM (REalistic AI Learning for Multiphysics), a rigorous benchmarking framework designed to test neural surrogates on challenging, application-driven reactive flows. REALM features 11 high-fidelity datasets spanning from canonical multiphysics problems to complex propulsion and fire safety scenarios, alongside a standardized end-to-end training and evaluation protocol that incorporates multiphysics-aware preprocessing and a robust rollout strategy. Using this framework, we systematically benchmark over a dozen representative surrogate model families, including spectral operators, convolutional models, Transformers, pointwise operators, and graph/mesh networks, and identify three robust trends: (i) a scaling barrier governed jointly by dimensionality, stiffness, and mesh irregularity, leading to rapidly growing rollout errors; (ii) performance primarily controlled by architectural inductive biases rather than parameter count; and (iii) a persistent gap between nominal accuracy metrics and physically trustworthy behavior, where models with high correlations still miss key transient structures and integral quantities. Taken together, REALM exposes the limits of current neural surrogates on realistic multiphysics flows and offers a rigorous testbed to drive the development of next-generation physics-aware architectures.
Reconstruction as a Bridge for Event-Based Visual Question Answering
Dec 12, 2025Integrating event cameras with Multimodal Large Language Models (MLLMs) promises general scene understanding in challenging visual conditions, yet requires navigating a trade-off between preserving the unique advantages of event data and ensuring compatibility with frame-based models. We address this challenge by using reconstruction as a bridge, proposing a straightforward Frame-based Reconstruction and Tokenization (FRT) method and designing an efficient Adaptive Reconstruction and Tokenization (ART) method that leverages event sparsity. For robust evaluation, we introduce EvQA, the first objective, real-world benchmark for event-based MLLMs, comprising 1,000 event-Q&A pairs from 22 public datasets. Our experiments demonstrate that our methods achieve state-of-the-art performance on EvQA, highlighting the significant potential of MLLMs in event-based vision.
ImplicitRDP: An End-to-End Visual-Force Diffusion Policy with Structural Slow-Fast Learning
Dec 11, 2025
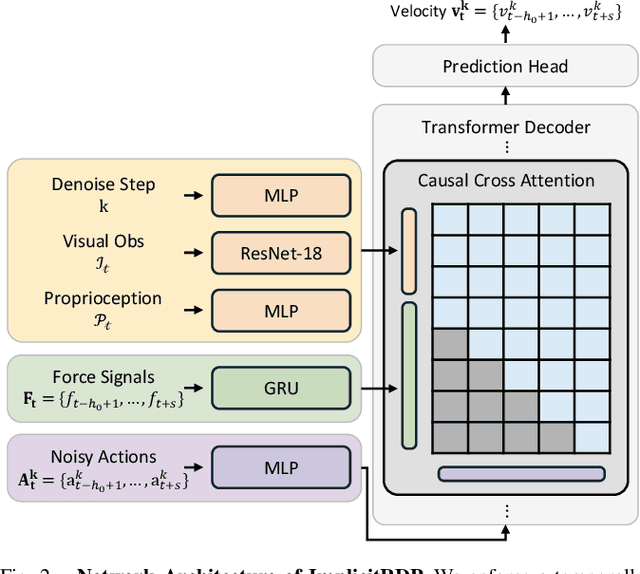


Human-level contact-rich manipulation relies on the distinct roles of two key modalities: vision provides spatially rich but temporally slow global context, while force sensing captures rapid, high-frequency local contact dynamics. Integrating these signals is challenging due to their fundamental frequency and informational disparities. In this work, we propose ImplicitRDP, a unified end-to-end visual-force diffusion policy that integrates visual planning and reactive force control within a single network. We introduce Structural Slow-Fast Learning, a mechanism utilizing causal attention to simultaneously process asynchronous visual and force tokens, allowing the policy to perform closed-loop adjustments at the force frequency while maintaining the temporal coherence of action chunks. Furthermore, to mitigate modality collapse where end-to-end models fail to adjust the weights across different modalities, we propose Virtual-target-based Representation Regularization. This auxiliary objective maps force feedback into the same space as the action, providing a stronger, physics-grounded learning signal than raw force prediction. Extensive experiments on contact-rich tasks demonstrate that ImplicitRDP significantly outperforms both vision-only and hierarchical baselines, achieving superior reactivity and success rates with a streamlined training pipeline. Code and videos will be publicly available at https://implicit-rdp.github.io.
Building Egocentric Procedural AI Assistant: Methods, Benchmarks, and Challenges
Nov 17, 2025Driven by recent advances in vision language models (VLMs) and egocentric perception research, we introduce the concept of an egocentric procedural AI assistant (EgoProceAssist) tailored to step-by-step support daily procedural tasks in a first-person view. In this work, we start by identifying three core tasks: egocentric procedural error detection, egocentric procedural learning, and egocentric procedural question answering. These tasks define the essential functions of EgoProceAssist within a new taxonomy. Specifically, our work encompasses a comprehensive review of current techniques, relevant datasets, and evaluation metrics across these three core areas. To clarify the gap between the proposed EgoProceAssist and existing VLM-based AI assistants, we introduce novel experiments and provide a comprehensive evaluation of representative VLM-based methods. Based on these findings and our technical analysis, we discuss the challenges ahead and suggest future research directions. Furthermore, an exhaustive list of this study is publicly available in an active repository that continuously collects the latest work: https://github.com/z1oong/Building-Egocentric-Procedural-AI-Assistant
Seg-VAR: Image Segmentation with Visual Autoregressive Modeling
Nov 16, 2025While visual autoregressive modeling (VAR) strategies have shed light on image generation with the autoregressive models, their potential for segmentation, a task that requires precise low-level spatial perception, remains unexplored. Inspired by the multi-scale modeling of classic Mask2Former-based models, we propose Seg-VAR, a novel framework that rethinks segmentation as a conditional autoregressive mask generation problem. This is achieved by replacing the discriminative learning with the latent learning process. Specifically, our method incorporates three core components: (1) an image encoder generating latent priors from input images, (2) a spatial-aware seglat (a latent expression of segmentation mask) encoder that maps segmentation masks into discrete latent tokens using a location-sensitive color mapping to distinguish instances, and (3) a decoder reconstructing masks from these latents. A multi-stage training strategy is introduced: first learning seglat representations via image-seglat joint training, then refining latent transformations, and finally aligning image-encoder-derived latents with seglat distributions. Experiments show Seg-VAR outperforms previous discriminative and generative methods on various segmentation tasks and validation benchmarks. By framing segmentation as a sequential hierarchical prediction task, Seg-VAR opens new avenues for integrating autoregressive reasoning into spatial-aware vision systems. Code will be available at https://github.com/rkzheng99/Seg-VAR.