 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models
Jan 16, 2026Vision-Language-Action (VLA) models have emerged as essential generalist robot policies for diverse manipulation tasks, conventionally relying on directly translating multimodal inputs into actions via Vision-Language Model (VLM) embeddings. Recent advancements have introduced explicit intermediary reasoning, such as sub-task prediction (language) or goal image synthesis (vision), to guide action generation. However, these intermediate reasoning are often indirect and inherently limited in their capacity to convey the full, granular information required for precise action execution. Instead, we posit that the most effective form of reasoning is one that deliberates directly in the action space. We introduce Action Chain-of-Thought (ACoT), a paradigm where the reasoning process itself is formulated as a structured sequence of coarse action intents that guide the final policy. In this paper, we propose ACoT-VLA, a novel architecture that materializes the ACoT paradigm. Specifically, we introduce two complementary components: an Explicit Action Reasoner (EAR) and Implicit Action Reasoner (IAR). The former proposes coarse reference trajectories as explicit action-level reasoning steps, while the latter extracts latent action priors from internal representations of multimodal input, co-forming an ACoT that conditions the downstream action head to enable grounded policy learning. Extensive experiments in real-world and simulation environments demonstrate the superiority of our proposed method, which achieves 98.5%, 84.1%, and 47.4% on LIBERO, LIBERO-Plus and VLABench, respectively.
SOP: A Scalable Online Post-Training System for Vision-Language-Action Models
Jan 06, 2026Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training, but real-world deployment requires expert-level task proficiency in addition to broad generality. Existing post-training approaches for VLA models are typically offline, single-robot, or task-specific, limiting effective on-policy adaptation and scalable learning from real-world interaction. We introduce a Scalable Online Post-training (SOP) system that enables online, distributed, multi-task post-training of generalist VLA models directly in the physical world. SOP tightly couples execution and learning through a closed-loop architecture in which a fleet of robots continuously streams on-policy experience and human intervention signals to a centralized cloud learner, and asynchronously receives updated policies. This design supports prompt on-policy correction, scales experience collection through parallel deployment, and preserves generality during adaptation. SOP is agnostic to the choice of post-training algorithm; we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP). Across a range of real-world manipulation tasks including cloth folding, box assembly, and grocery restocking, we show that SOP substantially improves the performance of large pretrained VLA models while maintaining a single shared policy across tasks. Effective post-training can be achieved within hours of real-world interaction, and performance scales near-linearly with the number of robots in the fleet. These results suggest that tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training of generalist robot policies in the physical world.
The Trajectory of Voice Onset Time with Vocal Aging
Oct 15, 2018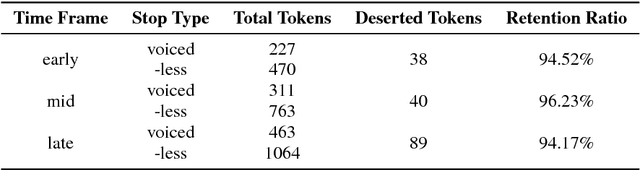
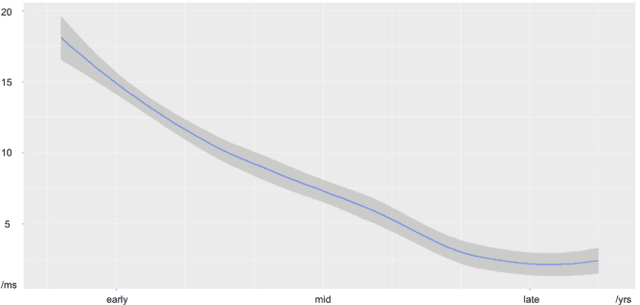
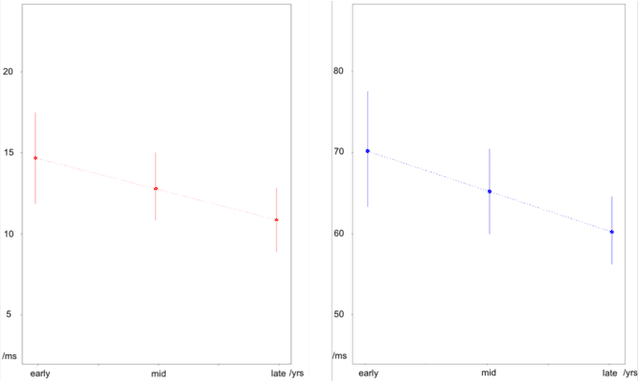
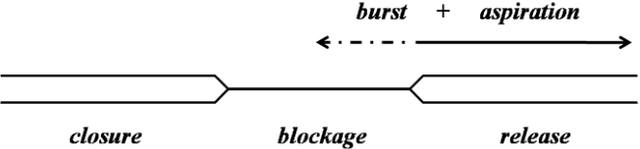
Vocal aging, a universal process of human aging, can largely affect one's language use, possibly including some subtle acoustic features of one's utterances like Voice Onset Time. To figure out the time effects, Queen Elizabeth's Christmas speeches are documented and analyzed in the long-term trend. We build statistical models of time dependence in Voice Onset Time, controlling a wide range of other fixed factors, to present annual variations and the simulated trajectory. It is revealed that the variation range of Voice Onset Time has been narrowing over fifty years with a slight reduction in the mean value, which, possibly, is an effect of diminishing exertion, resulting from subdued muscle contraction, transcending other non-linguistic factors in forming Voice Onset Time patterns over a long time.
* conference