 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForce Policy: Learning Hybrid Force-Position Control Policy under Interaction Frame for Contact-Rich Manipulation
Feb 25, 2026Contact-rich manipulation demands human-like integration of perception and force feedback: vision should guide task progress, while high-frequency interaction control must stabilize contact under uncertainty. Existing learning-based policies often entangle these roles in a monolithic network, trading off global generalization against stable local refinement, while control-centric approaches typically assume a known task structure or learn only controller parameters rather than the structure itself. In this paper, we formalize a physically grounded interaction frame, an instantaneous local basis that decouples force regulation from motion execution, and propose a method to recover it from demonstrations. Based on this, we address both issues by proposing Force Policy, a global-local vision-force policy in which a global policy guides free-space actions using vision, and upon contact, a high-frequency local policy with force feedback estimates the interaction frame and executes hybrid force-position control for stable interaction. Real-world experiments across diverse contact-rich tasks show consistent gains over strong baselines, with more robust contact establishment, more accurate force regulation, and reliable generalization to novel objects with varied geometries and physical properties, ultimately improving both contact stability and execution quality. Project page: https://force-policy.github.io/
ImplicitRDP: An End-to-End Visual-Force Diffusion Policy with Structural Slow-Fast Learning
Dec 11, 2025
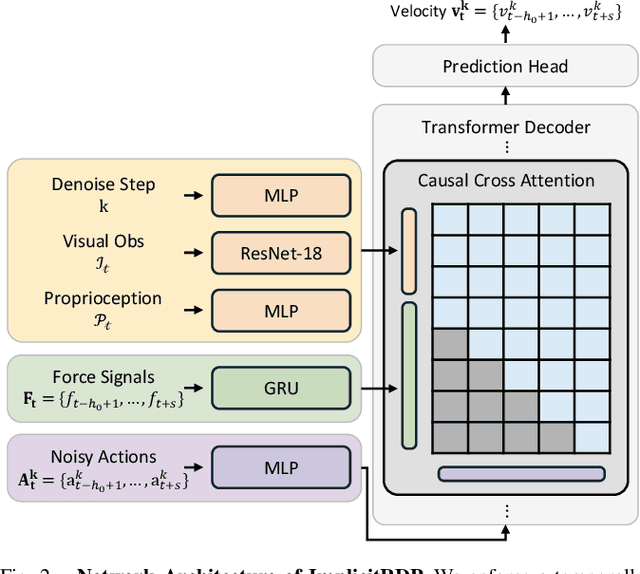


Human-level contact-rich manipulation relies on the distinct roles of two key modalities: vision provides spatially rich but temporally slow global context, while force sensing captures rapid, high-frequency local contact dynamics. Integrating these signals is challenging due to their fundamental frequency and informational disparities. In this work, we propose ImplicitRDP, a unified end-to-end visual-force diffusion policy that integrates visual planning and reactive force control within a single network. We introduce Structural Slow-Fast Learning, a mechanism utilizing causal attention to simultaneously process asynchronous visual and force tokens, allowing the policy to perform closed-loop adjustments at the force frequency while maintaining the temporal coherence of action chunks. Furthermore, to mitigate modality collapse where end-to-end models fail to adjust the weights across different modalities, we propose Virtual-target-based Representation Regularization. This auxiliary objective maps force feedback into the same space as the action, providing a stronger, physics-grounded learning signal than raw force prediction. Extensive experiments on contact-rich tasks demonstrate that ImplicitRDP significantly outperforms both vision-only and hierarchical baselines, achieving superior reactivity and success rates with a streamlined training pipeline. Code and videos will be publicly available at https://implicit-rdp.github.io.