 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveGlasses: Learning Manipulation with Active Vision from Ego-centric Human Demonstration
Apr 09, 2026Large-scale real-world robot data collection is a prerequisite for bringing robots into everyday deployment. However, existing pipelines often rely on specialized handheld devices to bridge the embodiment gap, which not only increases operator burden and limits scalability, but also makes it difficult to capture the naturally coordinated perception-manipulation behaviors of human daily interaction. This challenge calls for a more natural system that can faithfully capture human manipulation and perception behaviors while enabling zero-shot transfer to robotic platforms. We introduce ActiveGlasses, a system for learning robot manipulation from ego-centric human demonstrations with active vision. A stereo camera mounted on smart glasses serves as the sole perception device for both data collection and policy inference: the operator wears it during bare-hand demonstrations, and the same camera is mounted on a 6-DoF perception arm during deployment to reproduce human active vision. To enable zero-transfer, we extract object trajectories from demonstrations and use an object-centric point-cloud policy to jointly predict manipulation and head movement. Across several challenging tasks involving occlusion and precise interaction, ActiveGlasses achieves zero-shot transfer with active vision, consistently outperforms strong baselines under the same hardware setup, and generalizes across two robot platforms.
Learning Athletic Humanoid Tennis Skills from Imperfect Human Motion Data
Mar 13, 2026Human athletes demonstrate versatile and highly-dynamic tennis skills to successfully conduct competitive rallies with a high-speed tennis ball. However, reproducing such behaviors on humanoid robots is difficult, partially due to the lack of perfect humanoid action data or human kinematic motion data in tennis scenarios as reference. In this work, we propose LATENT, a system that Learns Athletic humanoid TEnnis skills from imperfect human motioN daTa. The imperfect human motion data consist only of motion fragments that capture the primitive skills used when playing tennis rather than precise and complete human-tennis motion sequences from real-world tennis matches, thereby significantly reducing the difficulty of data collection. Our key insight is that, despite being imperfect, such quasi-realistic data still provide priors about human primitive skills in tennis scenarios. With further correction and composition, we learn a humanoid policy that can consistently strike incoming balls under a wide range of conditions and return them to target locations, while preserving natural motion styles. We also propose a series of designs for robust sim-to-real transfer and deploy our policy on the Unitree G1 humanoid robot. Our method achieves surprising results in the real world and can stably sustain multi-shot rallies with human players. Project page: https://zzk273.github.io/LATENT/
RoboPocket: Improve Robot Policies Instantly with Your Phone
Mar 05, 2026Scaling imitation learning is fundamentally constrained by the efficiency of data collection. While handheld interfaces have emerged as a scalable solution for in-the-wild data acquisition, they predominantly operate in an open-loop manner: operators blindly collect demonstrations without knowing the underlying policy's weaknesses, leading to inefficient coverage of critical state distributions. Conversely, interactive methods like DAgger effectively address covariate shift but rely on physical robot execution, which is costly and difficult to scale. To reconcile this trade-off, we introduce RoboPocket, a portable system that enables Robot-Free Instant Policy Iteration using single consumer smartphones. Its core innovation is a Remote Inference framework that visualizes the policy's predicted trajectory via Augmented Reality (AR) Visual Foresight. This immersive feedback allows collectors to proactively identify potential failures and focus data collection on the policy's weak regions without requiring a physical robot. Furthermore, we implement an asynchronous Online Finetuning pipeline that continuously updates the policy with incoming data, effectively closing the learning loop in minutes. Extensive experiments demonstrate that RoboPocket adheres to data scaling laws and doubles the data efficiency compared to offline scaling strategies, overcoming their long-standing efficiency bottleneck. Moreover, our instant iteration loop also boosts sample efficiency by up to 2$\times$ in distributed environments a small number of interactive corrections per person. Project page and videos: https://robo-pocket.github.io.
Rethinking Camera Choice: An Empirical Study on Fisheye Camera Properties in Robotic Manipulation
Mar 02, 2026The adoption of fisheye cameras in robotic manipulation, driven by their exceptionally wide Field of View (FoV), is rapidly outpacing a systematic understanding of their downstream effects on policy learning. This paper presents the first comprehensive empirical study to bridge this gap, rigorously analyzing the properties of wrist-mounted fisheye cameras for imitation learning. Through extensive experiments in both simulation and the real world, we investigate three critical research questions: spatial localization, scene generalization, and hardware generalization. Our investigation reveals that: (1) The wide FoV significantly enhances spatial localization, but this benefit is critically contingent on the visual complexity of the environment. (2) Fisheye-trained policies, while prone to overfitting in simple scenes, unlock superior scene generalization when trained with sufficient environmental diversity. (3) While naive cross-camera transfer leads to failures, we identify the root cause as scale overfitting and demonstrate that hardware generalization performance can be improved with a simple Random Scale Augmentation (RSA) strategy. Collectively, our findings provide concrete, actionable guidance for the large-scale collection and effective use of fisheye datasets in robotic learning. More results and videos are available on https://robo-fisheye.github.io/
Collision-Free Humanoid Traversal in Cluttered Indoor Scenes
Jan 23, 2026We study the problem of collision-free humanoid traversal in cluttered indoor scenes, such as hurdling over objects scattered on the floor, crouching under low-hanging obstacles, or squeezing through narrow passages. To achieve this goal, the humanoid needs to map its perception of surrounding obstacles with diverse spatial layouts and geometries to the corresponding traversal skills. However, the lack of an effective representation that captures humanoid-obstacle relationships during collision avoidance makes directly learning such mappings difficult. We therefore propose Humanoid Potential Field (HumanoidPF), which encodes these relationships as collision-free motion directions, significantly facilitating RL-based traversal skill learning. We also find that HumanoidPF exhibits a surprisingly negligible sim-to-real gap as a perceptual representation. To further enable generalizable traversal skills through diverse and challenging cluttered indoor scenes, we further propose a hybrid scene generation method, incorporating crops of realistic 3D indoor scenes and procedurally synthesized obstacles. We successfully transfer our policy to the real world and develop a teleoperation system where users could command the humanoid to traverse in cluttered indoor scenes with just a single click. Extensive experiments are conducted in both simulation and the real world to validate the effectiveness of our method. Demos and code can be found in our website: https://axian12138.github.io/CAT/.
ImplicitRDP: An End-to-End Visual-Force Diffusion Policy with Structural Slow-Fast Learning
Dec 11, 2025
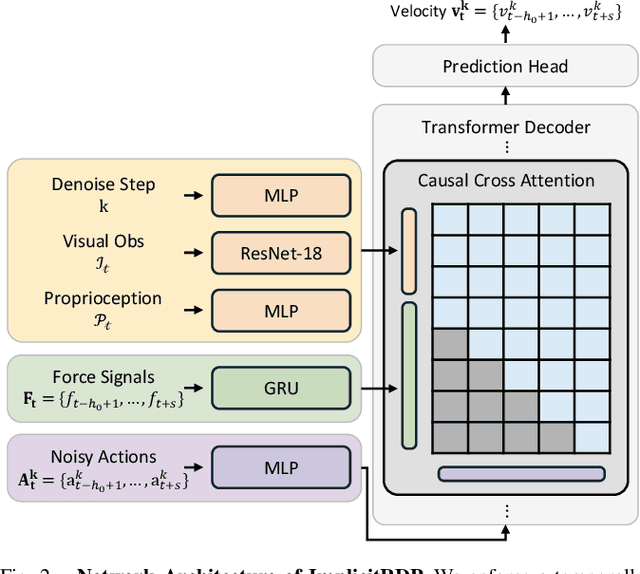


Human-level contact-rich manipulation relies on the distinct roles of two key modalities: vision provides spatially rich but temporally slow global context, while force sensing captures rapid, high-frequency local contact dynamics. Integrating these signals is challenging due to their fundamental frequency and informational disparities. In this work, we propose ImplicitRDP, a unified end-to-end visual-force diffusion policy that integrates visual planning and reactive force control within a single network. We introduce Structural Slow-Fast Learning, a mechanism utilizing causal attention to simultaneously process asynchronous visual and force tokens, allowing the policy to perform closed-loop adjustments at the force frequency while maintaining the temporal coherence of action chunks. Furthermore, to mitigate modality collapse where end-to-end models fail to adjust the weights across different modalities, we propose Virtual-target-based Representation Regularization. This auxiliary objective maps force feedback into the same space as the action, providing a stronger, physics-grounded learning signal than raw force prediction. Extensive experiments on contact-rich tasks demonstrate that ImplicitRDP significantly outperforms both vision-only and hierarchical baselines, achieving superior reactivity and success rates with a streamlined training pipeline. Code and videos will be publicly available at https://implicit-rdp.github.io.
Right-Side-Out: Learning Zero-Shot Sim-to-Real Garment Reversal
Sep 19, 2025Turning garments right-side out is a challenging manipulation task: it is highly dynamic, entails rapid contact changes, and is subject to severe visual occlusion. We introduce Right-Side-Out, a zero-shot sim-to-real framework that effectively solves this challenge by exploiting task structures. We decompose the task into Drag/Fling to create and stabilize an access opening, followed by Insert&Pull to invert the garment. Each step uses a depth-inferred, keypoint-parameterized bimanual primitive that sharply reduces the action space while preserving robustness. Efficient data generation is enabled by our custom-built, high-fidelity, GPU-parallel Material Point Method (MPM) simulator that models thin-shell deformation and provides robust and efficient contact handling for batched rollouts. Built on the simulator, our fully automated pipeline scales data generation by randomizing garment geometry, material parameters, and viewpoints, producing depth, masks, and per-primitive keypoint labels without any human annotations. With a single depth camera, policies trained entirely in simulation deploy zero-shot on real hardware, achieving up to 81.3% success rate. By employing task decomposition and high fidelity simulation, our framework enables tackling highly dynamic, severely occluded tasks without laborious human demonstrations.
Track Any Motions under Any Disturbances
Sep 17, 2025



A foundational humanoid motion tracker is expected to be able to track diverse, highly dynamic, and contact-rich motions. More importantly, it needs to operate stably in real-world scenarios against various dynamics disturbances, including terrains, external forces, and physical property changes for general practical use. To achieve this goal, we propose Any2Track (Track Any motions under Any disturbances), a two-stage RL framework to track various motions under multiple disturbances in the real world. Any2Track reformulates dynamics adaptability as an additional capability on top of basic action execution and consists of two key components: AnyTracker and AnyAdapter. AnyTracker is a general motion tracker with a series of careful designs to track various motions within a single policy. AnyAdapter is a history-informed adaptation module that endows the tracker with online dynamics adaptability to overcome the sim2real gap and multiple real-world disturbances. We deploy Any2Track on Unitree G1 hardware and achieve a successful sim2real transfer in a zero-shot manner. Any2Track performs exceptionally well in tracking various motions under multiple real-world disturbances.
Unleashing Humanoid Reaching Potential via Real-world-Ready Skill Space
May 16, 2025Humans possess a large reachable space in the 3D world, enabling interaction with objects at varying heights and distances. However, realizing such large-space reaching on humanoids is a complex whole-body control problem and requires the robot to master diverse skills simultaneously-including base positioning and reorientation, height and body posture adjustments, and end-effector pose control. Learning from scratch often leads to optimization difficulty and poor sim2real transferability. To address this challenge, we propose Real-world-Ready Skill Space (R2S2). Our approach begins with a carefully designed skill library consisting of real-world-ready primitive skills. We ensure optimal performance and robust sim2real transfer through individual skill tuning and sim2real evaluation. These skills are then ensembled into a unified latent space, serving as a structured prior that helps task execution in an efficient and sim2real transferable manner. A high-level planner, trained to sample skills from this space, enables the robot to accomplish real-world goal-reaching tasks. We demonstrate zero-shot sim2real transfer and validate R2S2 in multiple challenging goal-reaching scenarios.
Dense Policy: Bidirectional Autoregressive Learning of Actions
Mar 17, 2025Mainstream visuomotor policies predominantly rely on generative models for holistic action prediction, while current autoregressive policies, predicting the next token or chunk, have shown suboptimal results. This motivates a search for more effective learning methods to unleash the potential of autoregressive policies for robotic manipulation. This paper introduces a bidirectionally expanded learning approach, termed Dense Policy, to establish a new paradigm for autoregressive policies in action prediction. It employs a lightweight encoder-only architecture to iteratively unfold the action sequence from an initial single frame into the target sequence in a coarse-to-fine manner with logarithmic-time inference. Extensive experiments validate that our dense policy has superior autoregressive learning capabilities and can surpass existing holistic generative policies. Our policy, example data, and training code will be publicly available upon publication. Project page: https: //selen-suyue.github.io/DspNet/.