 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOP: A Scalable Online Post-Training System for Vision-Language-Action Models
Jan 06, 2026Vision-language-action (VLA) models achieve strong generalization through large-scale pre-training, but real-world deployment requires expert-level task proficiency in addition to broad generality. Existing post-training approaches for VLA models are typically offline, single-robot, or task-specific, limiting effective on-policy adaptation and scalable learning from real-world interaction. We introduce a Scalable Online Post-training (SOP) system that enables online, distributed, multi-task post-training of generalist VLA models directly in the physical world. SOP tightly couples execution and learning through a closed-loop architecture in which a fleet of robots continuously streams on-policy experience and human intervention signals to a centralized cloud learner, and asynchronously receives updated policies. This design supports prompt on-policy correction, scales experience collection through parallel deployment, and preserves generality during adaptation. SOP is agnostic to the choice of post-training algorithm; we instantiate it with both interactive imitation learning (HG-DAgger) and reinforcement learning (RECAP). Across a range of real-world manipulation tasks including cloth folding, box assembly, and grocery restocking, we show that SOP substantially improves the performance of large pretrained VLA models while maintaining a single shared policy across tasks. Effective post-training can be achieved within hours of real-world interaction, and performance scales near-linearly with the number of robots in the fleet. These results suggest that tightly coupling online learning with fleet-scale deployment is instrumental to enabling efficient, reliable, and scalable post-training of generalist robot policies in the physical world.
Unified Embodied VLM Reasoning with Robotic Action via Autoregressive Discretized Pre-training
Dec 30, 2025General-purpose robotic systems operating in open-world environments must achieve both broad generalization and high-precision action execution, a combination that remains challenging for existing Vision-Language-Action (VLA) models. While large Vision-Language Models (VLMs) improve semantic generalization, insufficient embodied reasoning leads to brittle behavior, and conversely, strong reasoning alone is inadequate without precise control. To provide a decoupled and quantitative assessment of this bottleneck, we introduce Embodied Reasoning Intelligence Quotient (ERIQ), a large-scale embodied reasoning benchmark in robotic manipulation, comprising 6K+ question-answer pairs across four reasoning dimensions. By decoupling reasoning from execution, ERIQ enables systematic evaluation and reveals a strong positive correlation between embodied reasoning capability and end-to-end VLA generalization. To bridge the gap from reasoning to precise execution, we propose FACT, a flow-matching-based action tokenizer that converts continuous control into discrete sequences while preserving high-fidelity trajectory reconstruction. The resulting GenieReasoner jointly optimizes reasoning and action in a unified space, outperforming both continuous-action and prior discrete-action baselines in real-world tasks. Together, ERIQ and FACT provide a principled framework for diagnosing and overcoming the reasoning-precision trade-off, advancing robust, general-purpose robotic manipulation.
Explicit Pose Deformation Learning for Tracking Human Poses
Nov 21, 2018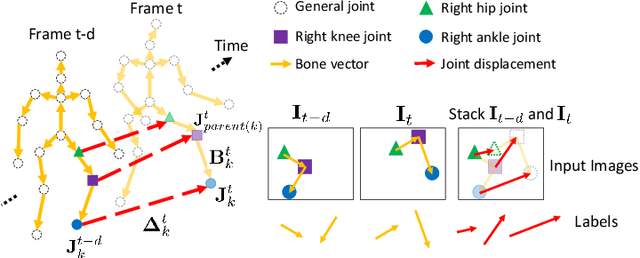

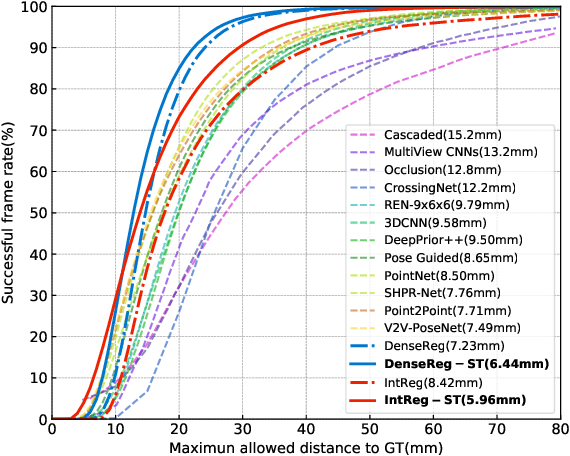
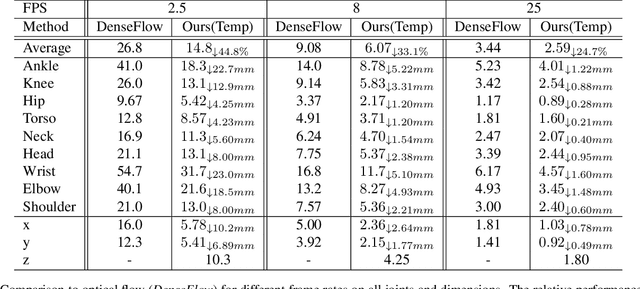
We present a method for human pose tracking that learns explicitly about the dynamic effects of human motion on joint appearance. In contrast to previous techniques which employ generic tools such as dense optical flow or spatio-temporal smoothness constraints to pass pose inference cues between frames, our system instead learns to predict joint displacements from the previous frame to the current frame based on the possibly changing appearance of relevant pixels surrounding the corresponding joints in the previous frame. This explicit learning of pose deformations is formulated by incorporating concepts from human pose estimation into an optical flow-like framework. With this approach, state-of-the-art performance is achieved on standard benchmarks for various pose tracking tasks including 3D body pose tracking in RGB video, 3D hand pose tracking in depth sequences, and 3D hand gesture tracking in RGB video.
An Integral Pose Regression System for the ECCV2018 PoseTrack Challenge
Sep 17, 2018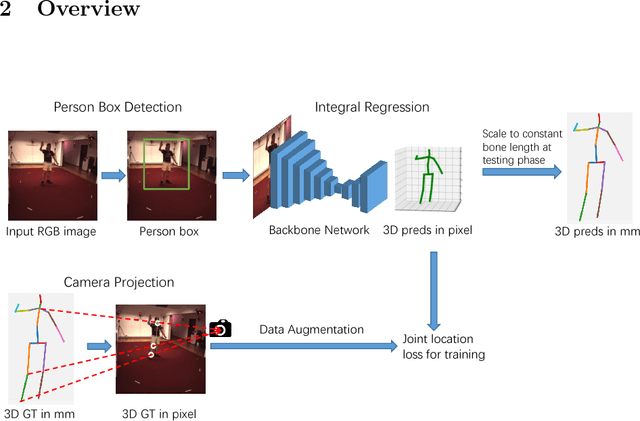

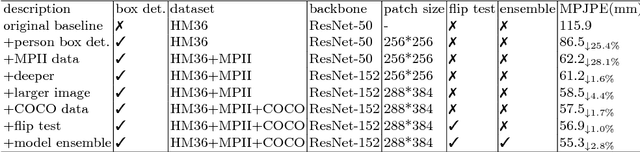
For the ECCV 2018 PoseTrack Challenge, we present a 3D human pose estimation system based mainly on the integral human pose regression method. We show a comprehensive ablation study to examine the key performance factors of the proposed system. Our system obtains 47mm MPJPE on the CHALL_H80K test dataset, placing second in the ECCV2018 3D human pose estimation challenge. Code will be released to facilitate future work.