 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCat-AudioDiT: High-Fidelity Diffusion Text-to-Speech in the Waveform Latent Space
Mar 31, 2026We present LongCat-AudioDiT, a novel, non-autoregressive diffusion-based text-to-speech (TTS) model that achieves state-of-the-art (SOTA) performance. Unlike previous methods that rely on intermediate acoustic representations such as mel-spectrograms, the core innovation of LongCat-AudioDiT lies in operating directly within the waveform latent space. This approach effectively mitigates compounding errors and drastically simplifies the TTS pipeline, requiring only a waveform variational autoencoder (Wav-VAE) and a diffusion backbone. Furthermore, we introduce two critical improvements to the inference process: first, we identify and rectify a long-standing training-inference mismatch; second, we replace traditional classifier-free guidance with adaptive projection guidance to elevate generation quality. Experimental results demonstrate that, despite the absence of complex multi-stage training pipelines or high-quality human-annotated datasets, LongCat-AudioDiT achieves SOTA zero-shot voice cloning performance on the Seed benchmark while maintaining competitive intelligibility. Specifically, our largest variant, LongCat-AudioDiT-3.5B, outperforms the previous SOTA model (Seed-TTS), improving the speaker similarity (SIM) scores from 0.809 to 0.818 on Seed-ZH, and from 0.776 to 0.797 on Seed-Hard. Finally, through comprehensive ablation studies and systematic analysis, we validate the effectiveness of our proposed modules. Notably, we investigate the interplay between the Wav-VAE and the TTS backbone, revealing the counterintuitive finding that superior reconstruction fidelity in the Wav-VAE does not necessarily lead to better overall TTS performance. Code and model weights are released to foster further research within the speech community.
MARCH: Multi-Agent Reinforced Self-Check for LLM Hallucination
Mar 25, 2026Hallucination remains a critical bottleneck for large language models (LLMs), undermining their reliability in real-world applications, especially in Retrieval-Augmented Generation (RAG) systems. While existing hallucination detection methods employ LLM-as-a-judge to verify LLM outputs against retrieved evidence, they suffer from inherent confirmation bias, where the verifier inadvertently reproduces the errors of the original generation. To address this, we introduce Multi-Agent Reinforced Self-Check for Hallucination (MARCH), a framework that enforces rigorous factual alignment by leveraging deliberate information asymmetry. MARCH orchestrates a collaborative pipeline of three specialized agents: a Solver, a Proposer, and a Checker. The Solver generates an initial RAG response, which the Proposer decomposes into claim-level verifiable atomic propositions. Crucially, the Checker validates these propositions against retrieved evidence in isolation, deprived of the Solver's original output. This well-crafted information asymmetry scheme breaks the cycle of self-confirmation bias. By training this pipeline with multi-agent reinforcement learning (MARL), we enable the agents to co-evolve and optimize factual adherence. Extensive experiments across hallucination benchmarks demonstrate that MARCH substantially reduces hallucination rates. Notably, an 8B-parameter LLM equipped with MARCH achieves performance competitive with powerful closed-source models. MARCH paves a scalable path for factual self-improvement of LLMs through co-evolution. The code is at https://github.com/Qwen-Applications/MARCH.
Semantic-VAE: Semantic-Alignment Latent Representation for Better Speech Synthesis
Sep 26, 2025While mel-spectrograms have been widely utilized as intermediate representations in zero-shot text-to-speech (TTS), their inherent redundancy leads to inefficiency in learning text-speech alignment. Compact VAE-based latent representations have recently emerged as a stronger alternative, but they also face a fundamental optimization dilemma: higher-dimensional latent spaces improve reconstruction quality and speaker similarity, but degrade intelligibility, while lower-dimensional spaces improve intelligibility at the expense of reconstruction fidelity. To overcome this dilemma, we propose Semantic-VAE, a novel VAE framework that utilizes semantic alignment regularization in the latent space. This design alleviates the reconstruction-generation trade-off by capturing semantic structure in high-dimensional latent representations. Extensive experiments demonstrate that Semantic-VAE significantly improves synthesis quality and training efficiency. When integrated into F5-TTS, our method achieves 2.10% WER and 0.64 speaker similarity on LibriSpeech-PC, outperforming mel-based systems (2.23%, 0.60) and vanilla acoustic VAE baselines (2.65%, 0.59). We also release the code and models to facilitate further research.
MOPSA: Mixture of Prompt-Experts Based Speaker Adaptation for Elderly Speech Recognition
May 30, 2025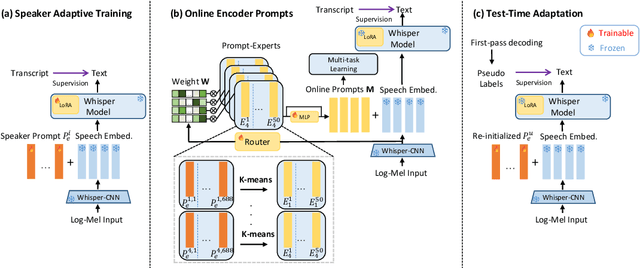
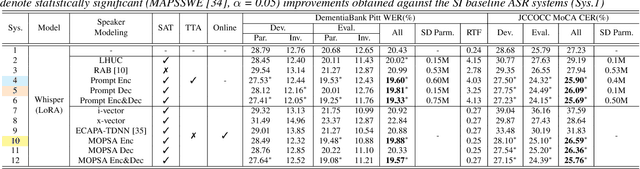
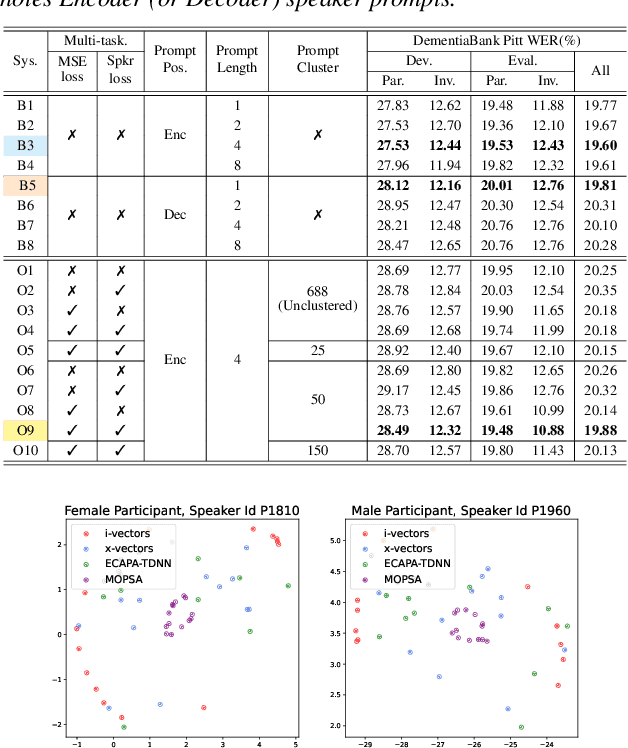
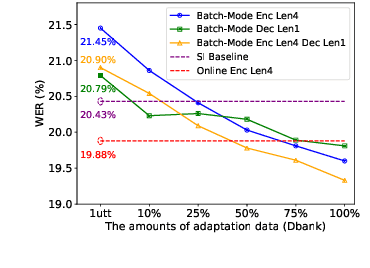
This paper proposes a novel Mixture of Prompt-Experts based Speaker Adaptation approach (MOPSA) for elderly speech recognition. It allows zero-shot, real-time adaptation to unseen speakers, and leverages domain knowledge tailored to elderly speakers. Top-K most distinctive speaker prompt clusters derived using K-means serve as experts. A router network is trained to dynamically combine clustered prompt-experts. Acoustic and language level variability among elderly speakers are modelled using separate encoder and decoder prompts for Whisper. Experiments on the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets suggest that online MOPSA adaptation outperforms the speaker-independent (SI) model by statistically significant word error rate (WER) or character error rate (CER) reductions of 0.86% and 1.47% absolute (4.21% and 5.40% relative). Real-time factor (RTF) speed-up ratios of up to 16.12 times are obtained over offline batch-mode adaptation.
Towards LLM-Empowered Fine-Grained Speech Descriptors for Explainable Emotion Recognition
May 29, 2025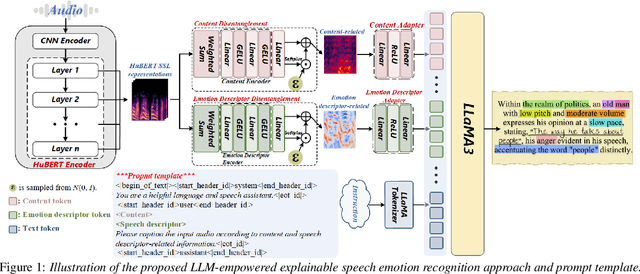
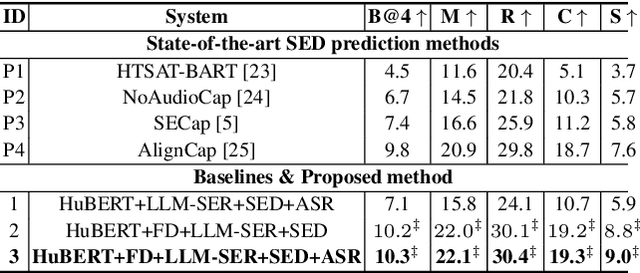
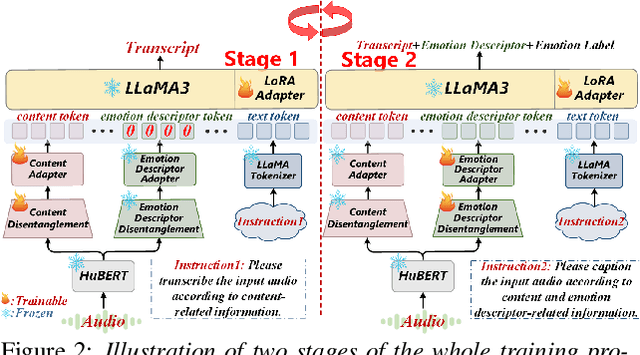
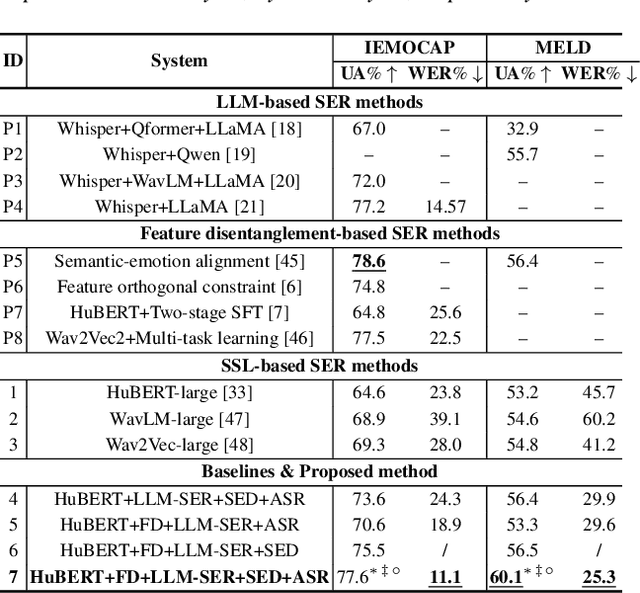
This paper presents a novel end-to-end LLM-empowered explainable speech emotion recognition (SER) approach. Fine-grained speech emotion descriptor (SED) features, e.g., pitch, tone and emphasis, are disentangled from HuBERT SSL representations via alternating LLM fine-tuning to joint SER-SED prediction and ASR tasks. VAE compressed HuBERT features derived via Information Bottleneck (IB) are used to adjust feature granularity. Experiments on the IEMOCAP and MELD benchmarks demonstrate that our approach consistently outperforms comparable LLaMA-based SER baselines, including those using either (a) alternating multi-task fine-tuning alone or (b) feature disentanglement only. Statistically significant increase of SER unweighted accuracy by up to 4.0% and 3.7% absolute (5.4% and 6.6% relative) are obtained. More importantly, emotion descriptors offer further explainability for SER.
Towards One-bit ASR: Extremely Low-bit Conformer Quantization Using Co-training and Stochastic Precision
May 27, 2025Model compression has become an emerging need as the sizes of modern speech systems rapidly increase. In this paper, we study model weight quantization, which directly reduces the memory footprint to accommodate computationally resource-constrained applications. We propose novel approaches to perform extremely low-bit (i.e., 2-bit and 1-bit) quantization of Conformer automatic speech recognition systems using multiple precision model co-training, stochastic precision, and tensor-wise learnable scaling factors to alleviate quantization incurred performance loss. The proposed methods can achieve performance-lossless 2-bit and 1-bit quantization of Conformer ASR systems trained with the 300-hr Switchboard and 960-hr LibriSpeech corpus. Maximum overall performance-lossless compression ratios of 16.2 and 16.6 times are achieved without a statistically significant increase in the word error rate (WER) over the full precision baseline systems, respectively.
Zero-Shot Streaming Text to Speech Synthesis with Transducer and Auto-Regressive Modeling
May 26, 2025Zero-shot streaming text-to-speech is an important research topic in human-computer interaction. Existing methods primarily use a lookahead mechanism, relying on future text to achieve natural streaming speech synthesis, which introduces high processing latency. To address this issue, we propose SMLLE, a streaming framework for generating high-quality speech frame-by-frame. SMLLE employs a Transducer to convert text into semantic tokens in real time while simultaneously obtaining duration alignment information. The combined outputs are then fed into a fully autoregressive (AR) streaming model to reconstruct mel-spectrograms. To further stabilize the generation process, we design a Delete < Bos > Mechanism that allows the AR model to access future text introducing as minimal delay as possible. Experimental results suggest that the SMLLE outperforms current streaming TTS methods and achieves comparable performance over sentence-level TTS systems. Samples are available on https://anonymous.4open.science/w/demo_page-48B7/.
Phone-purity Guided Discrete Tokens for Dysarthric Speech Recognition
Jan 08, 2025



Discrete tokens extracted provide efficient and domain adaptable speech features. Their application to disordered speech that exhibits articulation imprecision and large mismatch against normal voice remains unexplored. To improve their phonetic discrimination that is weakened during unsupervised K-means or vector quantization of continuous features, this paper proposes novel phone-purity guided (PPG) discrete tokens for dysarthric speech recognition. Phonetic label supervision is used to regularize maximum likelihood and reconstruction error costs used in standard K-means and VAE-VQ based discrete token extraction. Experiments conducted on the UASpeech corpus suggest that the proposed PPG discrete token features extracted from HuBERT consistently outperform hybrid TDNN and End-to-End (E2E) Conformer systems using non-PPG based K-means or VAE-VQ tokens across varying codebook sizes by statistically significant word error rate (WER) reductions up to 0.99\% and 1.77\% absolute (3.21\% and 4.82\% relative) respectively on the UASpeech test set of 16 dysarthric speakers. The lowest WER of 23.25\% was obtained by combining systems using different token features. Consistent improvements on the phone purity metric were also achieved. T-SNE visualization further demonstrates sharper decision boundaries were produced between K-means/VAE-VQ clusters after introducing phone-purity guidance.
Effective and Efficient Mixed Precision Quantization of Speech Foundation Models
Jan 07, 2025



This paper presents a novel mixed-precision quantization approach for speech foundation models that tightly integrates mixed-precision learning and quantized model parameter estimation into one single model compression stage. Experiments conducted on LibriSpeech dataset with fine-tuned wav2vec2.0-base and HuBERT-large models suggest the resulting mixed-precision quantized models increased the lossless compression ratio by factors up to 1.7x and 1.9x over the respective uniform-precision and two-stage mixed-precision quantized baselines that perform precision learning and model parameters quantization in separate and disjointed stages, while incurring no statistically word error rate (WER) increase over the 32-bit full-precision models. The system compression time of wav2vec2.0-base and HuBERT-large models is reduced by up to 1.9 and 1.5 times over the two-stage mixed-precision baselines, while both produce lower WERs. The best-performing 3.5-bit mixed-precision quantized HuBERT-large model produces a lossless compression ratio of 8.6x over the 32-bit full-precision system.
Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey
Dec 30, 2024



Building on the foundations of language modeling in natural language processing, Next Token Prediction (NTP) has evolved into a versatile training objective for machine learning tasks across various modalities, achieving considerable success. As Large Language Models (LLMs) have advanced to unify understanding and generation tasks within the textual modality, recent research has shown that tasks from different modalities can also be effectively encapsulated within the NTP framework, transforming the multimodal information into tokens and predict the next one given the context. This survey introduces a comprehensive taxonomy that unifies both understanding and generation within multimodal learning through the lens of NTP. The proposed taxonomy covers five key aspects: Multimodal tokenization, MMNTP model architectures, unified task representation, datasets \& evaluation, and open challenges. This new taxonomy aims to aid researchers in their exploration of multimodal intelligence. An associated GitHub repository collecting the latest papers and repos is available at https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction