 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoNSA: Native Sparse Attention Scales Video Understanding
Oct 02, 2025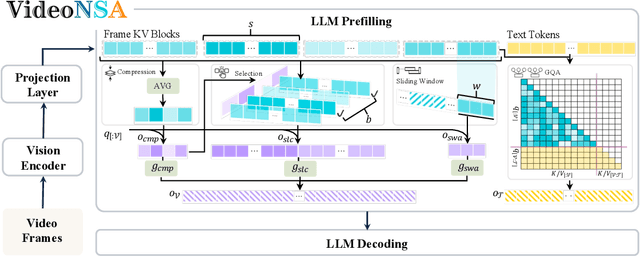
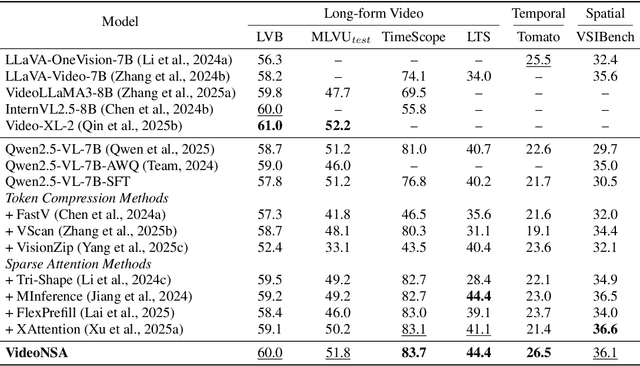
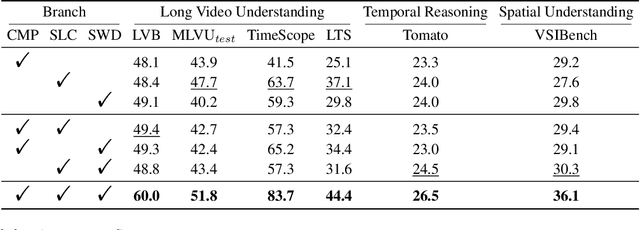
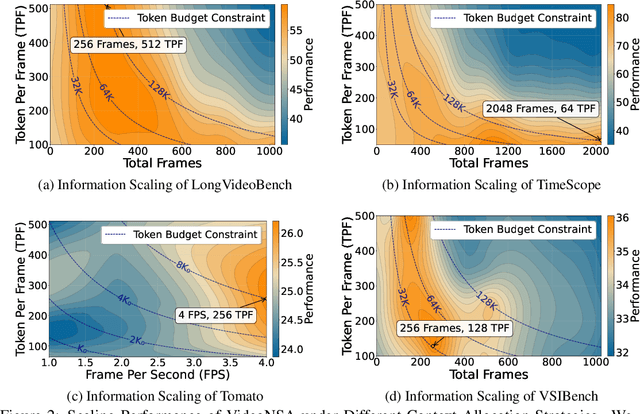
Video understanding in multimodal language models remains limited by context length: models often miss key transition frames and struggle to maintain coherence across long time scales. To address this, we adapt Native Sparse Attention (NSA) to video-language models. Our method, VideoNSA, adapts Qwen2.5-VL through end-to-end training on a 216K video instruction dataset. We employ a hardware-aware hybrid approach to attention, preserving dense attention for text, while employing NSA for video. Compared to token-compression and training-free sparse baselines, VideoNSA achieves improved performance on long-video understanding, temporal reasoning, and spatial benchmarks. Further ablation analysis reveals four key findings: (1) reliable scaling to 128K tokens; (2) an optimal global-local attention allocation at a fixed budget; (3) task-dependent branch usage patterns; and (4) the learnable combined sparse attention help induce dynamic attention sinks.
AuroraLong: Bringing RNNs Back to Efficient Open-Ended Video Understanding
Jul 03, 2025The challenge of long video understanding lies in its high computational complexity and prohibitive memory cost, since the memory and computation required by transformer-based LLMs scale quadratically with input sequence length. We propose AuroraLong to address this challenge by replacing the LLM component in MLLMs with a linear RNN language model that handles input sequence of arbitrary length with constant-size hidden states. To further increase throughput and efficiency, we combine visual token merge with linear RNN models by reordering the visual tokens by their sizes in ascending order. Despite having only 2B parameters and being trained exclusively on public data, AuroraLong achieves performance comparable to Transformer-based models of similar size trained on private datasets across multiple video benchmarks. This demonstrates the potential of efficient, linear RNNs to democratize long video understanding by lowering its computational entry barrier. To our best knowledge, we are the first to use a linear RNN based LLM backbone in a LLaVA-like model for open-ended video understanding.
Video-MMLU: A Massive Multi-Discipline Lecture Understanding Benchmark
Apr 20, 2025



Recent advancements in language multimodal models (LMMs) for video have demonstrated their potential for understanding video content, yet the task of comprehending multi-discipline lectures remains largely unexplored. We introduce Video-MMLU, a massive benchmark designed to evaluate the capabilities of LMMs in understanding Multi-Discipline Lectures. We evaluate over 90 open-source and proprietary models, ranging from 0.5B to 40B parameters. Our results highlight the limitations of current models in addressing the cognitive challenges presented by these lectures, especially in tasks requiring both perception and reasoning. Additionally, we explore how the number of visual tokens and the large language models influence performance, offering insights into the interplay between multimodal perception and reasoning in lecture comprehension.
Meissonic: Revitalizing Masked Generative Transformers for Efficient High-Resolution Text-to-Image Synthesis
Oct 10, 2024



Diffusion models, such as Stable Diffusion, have made significant strides in visual generation, yet their paradigm remains fundamentally different from autoregressive language models, complicating the development of unified language-vision models. Recent efforts like LlamaGen have attempted autoregressive image generation using discrete VQVAE tokens, but the large number of tokens involved renders this approach inefficient and slow. In this work, we present Meissonic, which elevates non-autoregressive masked image modeling (MIM) text-to-image to a level comparable with state-of-the-art diffusion models like SDXL. By incorporating a comprehensive suite of architectural innovations, advanced positional encoding strategies, and optimized sampling conditions, Meissonic substantially improves MIM's performance and efficiency. Additionally, we leverage high-quality training data, integrate micro-conditions informed by human preference scores, and employ feature compression layers to further enhance image fidelity and resolution. Our model not only matches but often exceeds the performance of existing models like SDXL in generating high-quality, high-resolution images. Extensive experiments validate Meissonic's capabilities, demonstrating its potential as a new standard in text-to-image synthesis. We release a model checkpoint capable of producing $1024 \times 1024$ resolution images.
AuroraCap: Efficient, Performant Video Detailed Captioning and a New Benchmark
Oct 04, 2024



Video detailed captioning is a key task which aims to generate comprehensive and coherent textual descriptions of video content, benefiting both video understanding and generation. In this paper, we propose AuroraCap, a video captioner based on a large multimodal model. We follow the simplest architecture design without additional parameters for temporal modeling. To address the overhead caused by lengthy video sequences, we implement the token merging strategy, reducing the number of input visual tokens. Surprisingly, we found that this strategy results in little performance loss. AuroraCap shows superior performance on various video and image captioning benchmarks, for example, obtaining a CIDEr of 88.9 on Flickr30k, beating GPT-4V (55.3) and Gemini-1.5 Pro (82.2). However, existing video caption benchmarks only include simple descriptions, consisting of a few dozen words, which limits research in this field. Therefore, we develop VDC, a video detailed captioning benchmark with over one thousand carefully annotated structured captions. In addition, we propose a new LLM-assisted metric VDCscore for bettering evaluation, which adopts a divide-and-conquer strategy to transform long caption evaluation into multiple short question-answer pairs. With the help of human Elo ranking, our experiments show that this benchmark better correlates with human judgments of video detailed captioning quality.
MovieChat+: Question-aware Sparse Memory for Long Video Question Answering
Apr 26, 2024Recently, integrating video foundation models and large language models to build a video understanding system can overcome the limitations of specific pre-defined vision tasks. Yet, existing methods either employ complex spatial-temporal modules or rely heavily on additional perception models to extract temporal features for video understanding, and they only perform well on short videos. For long videos, the computational complexity and memory costs associated with long-term temporal connections are significantly increased, posing additional challenges.Taking advantage of the Atkinson-Shiffrin memory model, with tokens in Transformers being employed as the carriers of memory in combination with our specially designed memory mechanism, we propose MovieChat to overcome these challenges. We lift pre-trained multi-modal large language models for understanding long videos without incorporating additional trainable temporal modules, employing a zero-shot approach. MovieChat achieves state-of-the-art performance in long video understanding, along with the released MovieChat-1K benchmark with 1K long video, 2K temporal grounding labels, and 14K manual annotations for validation of the effectiveness of our method. The code along with the dataset can be accessed via the following https://github.com/rese1f/MovieChat.
Devil in the Number: Towards Robust Multi-modality Data Filter
Sep 24, 2023



In order to appropriately filter multi-modality data sets on a web-scale, it becomes crucial to employ suitable filtering methods to boost performance and reduce training costs. For instance, LAION papers employs the CLIP score filter to select data with CLIP scores surpassing a certain threshold. On the other hand, T-MARS achieves high-quality data filtering by detecting and masking text within images and then filtering by CLIP score. Through analyzing the dataset, we observe a significant proportion of redundant information, such as numbers, present in the textual content. Our experiments on a subset of the data unveil the profound impact of these redundant elements on the CLIP scores. A logical approach would involve reevaluating the CLIP scores after eliminating these influences. Experimentally, our text-based CLIP filter outperforms the top-ranked method on the ``small scale" of DataComp (a data filtering benchmark) on ImageNet distribution shifts, achieving a 3.6% performance improvement. The results also demonstrate that our proposed text-masked filter outperforms the original CLIP score filter when selecting the top 40% of the data. The impact of numbers on CLIP and their handling provide valuable insights for improving the effectiveness of CLIP training, including language rewrite techniques.
MovieChat: From Dense Token to Sparse Memory for Long Video Understanding
Jul 31, 2023



Recently, integrating video foundation models and large language models to build a video understanding system overcoming the limitations of specific pre-defined vision tasks. Yet, existing systems can only handle videos with very few frames. For long videos, the computation complexity, memory cost, and long-term temporal connection are the remaining challenges. Inspired by Atkinson-Shiffrin memory model, we develop an memory mechanism including a rapidly updated short-term memory and a compact thus sustained long-term memory. We employ tokens in Transformers as the carriers of memory. MovieChat achieves state-of-the-art performace in long video understanding.