 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiSplat: Manipulation Trajectory Synthesis from Monocular Video via Decoupled 3D Gaussian Splatting
Jun 09, 2026Reconstructing dynamic and interactive 3D scenes from real-world observations remains a fundamental challenge in computer vision and robotics. While recent advances in 3D Gaussian Splatting have enabled high-fidelity static reconstruction, extending it to interactive environments with articulated robots and manipulable objects remains difficult due to complex contact interactions and abrupt pose changes. To address these challenges, we introduce ManiSplat, a unified framework that reconstructs controllable and decoupled Gaussian digital twins directly from monocular ego-view robotic videos. Our method introduces a Graph-Structured Disentangled Representation that separates the robot, objects, and background into independently optimizable Gaussian subfields organized within a scene graph. To ensure stability, we propose a Task-Oriented Spatio-Temporal Alignment module that leverages the inherent logic of manipulation tasks-alternating between Motion and Skill phases-to construct accurate pseudo-ground-truth trajectories. Finally, a joint photometric-geometric optimization ensures the reconstructed scenes are temporally coherent, physically consistent, and simulation-ready. Extensive experiments demonstrate that our approach reconstructs interaction-driven dynamic scenes with high fidelity and controllability, effectively supporting downstream robotic tasks and policy learning.
Verifier-Free RL for LLMs via Intrinsic Gradient-Norm Reward
May 11, 2026While Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a promising post-training paradigm for Large Language Models (LLMs), its dependency on the gold label or domain-specific verifiers limits its scalability to new tasks and domains. In this work, we propose Verifier-free Intrinsic Gradient-Norm Reward (VIGOR), a simple reward that uses only the policy model itself. Given a prompt, VIGOR samples a group of completions and assigns higher within-group rewards to outputs that induce smaller $\ell_2$ norms of the teacher-forced negative log-likelihood gradients under the current parameters. Intuitively, lower gradient norms suggest the completion aligns better with the current policy, serving as an intrinsic preference signal for policy optimization. To make this intrinsic signal practical for RL, we correct the systematic length bias of averaged token-level gradients with a $\sqrt{T}$ scaling, and apply group-wise rank shaping to stabilize reward scales across prompts. Across mathematical reasoning benchmarks, VIGOR outperforms the state-of-the-art Reinforcement Learning from Internal Feedback (RLIF) baseline, and it also exhibits cross-domain transfer to code benchmarks when trained only on math data. For instance, on Qwen2.5-7B-Base post-trained on MATH, VIGOR improves the average math accuracy by +3.31% and the average code accuracy by +1.91% over this baseline, while exhibiting more stable training dynamics. The code is available at https://github.com/ZJUSCL/VIGOR.
PianoFlow: Music-Aware Streaming Piano Motion Generation with Bimanual Coordination
Apr 14, 2026Audio-driven bimanual piano motion generation requires precise modeling of complex musical structures and dynamic cross-hand coordination. However, existing methods often rely on acoustic-only representations lacking symbolic priors, employ inflexible interaction mechanisms, and are limited to computationally expensive short-sequence generation. To address these limitations, we propose PianoFlow, a flow-matching framework for precise and coordinated bimanual piano motion synthesis. Our approach strategically leverages MIDI as a privileged modality during training, distilling these structured musical priors to achieve deep semantic understanding while maintaining audio-only inference. Furthermore, we introduce an asymmetric role-gated interaction module to explicitly capture dynamic cross-hand coordination through role-aware attention and temporal gating. To enable real-time streaming generation for arbitrarily long sequences, we design an autoregressive flow continuation scheme that ensures seamless cross-chunk temporal coherence. Extensive experiments on the PianoMotion10M dataset demonstrate that PianoFlow achieves superior quantitative and qualitative performance, while accelerating inference by over 9\times compared to previous methods.
See, Act, Adapt: Active Perception for Unsupervised Cross-Domain Visual Adaptation via Personalized VLM-Guided Agent
Feb 27, 2026Pre-trained perception models excel in generic image domains but degrade significantly in novel environments like indoor scenes. The conventional remedy is fine-tuning on downstream data which incurs catastrophic forgetting of prior knowledge and demands costly, scene-specific annotations. We propose a paradigm shift through Sea$^2$ (See, Act, Adapt): rather than adapting the perception modules themselves, we adapt how they are deployed through an intelligent pose-control agent. Sea$^2$ keeps all perception modules frozen, requiring no downstream labels during training, and uses only scalar perceptual feedback to navigate the agent toward informative viewpoints. Specially, we transform a vision-language model (VLM) into a low-level pose controller through a two-stage training pipeline: first fine-tuning it on rule-based exploration trajectories that systematically probe indoor scenes, and then refining the policy via unsupervised reinforcement learning that constructs rewards from the perception module's outputs and confidence. Unlike prior active perception methods that couple exploration with specific models or collect data for retraining them, Sea$^2$ directly leverages off-the-shelf perception models for various tasks without the need for retraining. We conducted experiments on three visual perception tasks, including visual grounding, segmentation and 3D box estimation, with performance improvements of 13.54%, 15.92% and 27.68% respectively on dataset ReplicaCAD.
MovieTeller: Tool-augmented Movie Synopsis with ID Consistent Progressive Abstraction
Feb 26, 2026With the explosive growth of digital entertainment, automated video summarization has become indispensable for applications such as content indexing, personalized recommendation, and efficient media archiving. Automatic synopsis generation for long-form videos, such as movies and TV series, presents a significant challenge for existing Vision-Language Models (VLMs). While proficient at single-image captioning, these general-purpose models often exhibit critical failures in long-duration contexts, primarily a lack of ID-consistent character identification and a fractured narrative coherence. To overcome these limitations, we propose MovieTeller, a novel framework for generating movie synopses via tool-augmented progressive abstraction. Our core contribution is a training-free, tool-augmented, fact-grounded generation process. Instead of requiring costly model fine-tuning, our framework directly leverages off-the-shelf models in a plug-and-play manner. We first invoke a specialized face recognition model as an external "tool" to establish Factual Groundings--precise character identities and their corresponding bounding boxes. These groundings are then injected into the prompt to steer the VLM's reasoning, ensuring the generated scene descriptions are anchored to verifiable facts. Furthermore, our progressive abstraction pipeline decomposes the summarization of a full-length movie into a multi-stage process, effectively mitigating the context length limitations of current VLMs. Experiments demonstrate that our approach yields significant improvements in factual accuracy, character consistency, and overall narrative coherence compared to end-to-end baselines.
DynaHOI: Benchmarking Hand-Object Interaction for Dynamic Target
Feb 12, 2026Most existing hand motion generation benchmarks for hand-object interaction (HOI) focus on static objects, leaving dynamic scenarios with moving targets and time-critical coordination largely untested. To address this gap, we introduce the DynaHOI-Gym, a unified online closed-loop platform with parameterized motion generators and rollout-based metrics for dynamic capture evaluation. Built on DynaHOI-Gym, we release DynaHOI-10M, a large-scale benchmark with 10M frames and 180K hand capture trajectories, whose target motions are organized into 8 major categories and 22 fine-grained subcategories. We also provide a simple observe-before-act baseline (ObAct) that integrates short-term observations with the current frame via spatiotemporal attention to predict actions, achieving an 8.1% improvement in location success rate.
Hand3R: Online 4D Hand-Scene Reconstruction in the Wild
Feb 03, 2026For Embodied AI, jointly reconstructing dynamic hands and the dense scene context is crucial for understanding physical interaction. However, most existing methods recover isolated hands in local coordinates, overlooking the surrounding 3D environment. To address this, we present Hand3R, the first online framework for joint 4D hand-scene reconstruction from monocular video. Hand3R synergizes a pre-trained hand expert with a 4D scene foundation model via a scene-aware visual prompting mechanism. By injecting high-fidelity hand priors into a persistent scene memory, our approach enables simultaneous reconstruction of accurate hand meshes and dense metric-scale scene geometry in a single forward pass. Experiments demonstrate that Hand3R bypasses the reliance on offline optimization and delivers competitive performance in both local hand reconstruction and global positioning.
$M^3-Verse$: A "Spot the Difference" Challenge for Large Multimodal Models
Dec 21, 2025Modern Large Multimodal Models (LMMs) have demonstrated extraordinary ability in static image and single-state spatial-temporal understanding. However, their capacity to comprehend the dynamic changes of objects within a shared spatial context between two distinct video observations, remains largely unexplored. This ability to reason about transformations within a consistent environment is particularly crucial for advancements in the field of spatial intelligence. In this paper, we introduce $M^3-Verse$, a Multi-Modal, Multi-State, Multi-Dimensional benchmark, to formally evaluate this capability. It is built upon paired videos that provide multi-perspective observations of an indoor scene before and after a state change. The benchmark contains a total of 270 scenes and 2,932 questions, which are categorized into over 50 subtasks that probe 4 core capabilities. We evaluate 16 state-of-the-art LMMs and observe their limitations in tracking state transitions. To address these challenges, we further propose a simple yet effective baseline that achieves significant performance improvements in multi-state perception. $M^3-Verse$ thus provides a challenging new testbed to catalyze the development of next-generation models with a more holistic understanding of our dynamic visual world. You can get the construction pipeline from https://github.com/Wal-K-aWay/M3-Verse_pipeline and full benchmark data from https://www.modelscope.cn/datasets/WalKaWay/M3-Verse.
RecurGS: Interactive Scene Modeling via Discrete-State Recurrent Gaussian Fusion
Dec 20, 2025Recent advances in 3D scene representations have enabled high-fidelity novel view synthesis, yet adapting to discrete scene changes and constructing interactive 3D environments remain open challenges in vision and robotics. Existing approaches focus solely on updating a single scene without supporting novel-state synthesis. Others rely on diffusion-based object-background decoupling that works on one state at a time and cannot fuse information across multiple observations. To address these limitations, we introduce RecurGS, a recurrent fusion framework that incrementally integrates discrete Gaussian scene states into a single evolving representation capable of interaction. RecurGS detects object-level changes across consecutive states, aligns their geometric motion using semantic correspondence and Lie-algebra based SE(3) refinement, and performs recurrent updates that preserve historical structures through replay supervision. A voxelized, visibility-aware fusion module selectively incorporates newly observed regions while keeping stable areas fixed, mitigating catastrophic forgetting and enabling efficient long-horizon updates. RecurGS supports object-level manipulation, synthesizes novel scene states without requiring additional scans, and maintains photorealistic fidelity across evolving environments. Extensive experiments across synthetic and real-world datasets demonstrate that our framework delivers high-quality reconstructions with substantially improved update efficiency, providing a scalable step toward continuously interactive Gaussian worlds.
CORE: Compact Object-centric REpresentations as a New Paradigm for Token Merging in LVLMs
Nov 18, 2025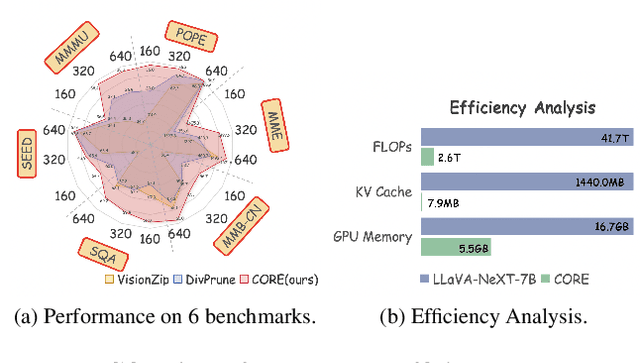
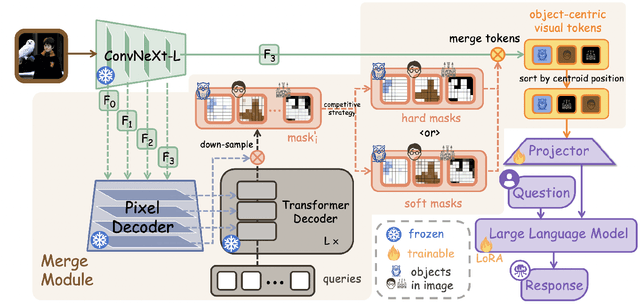
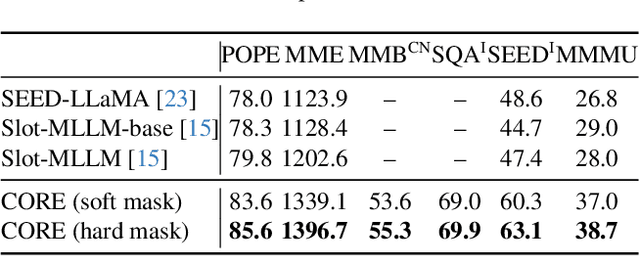
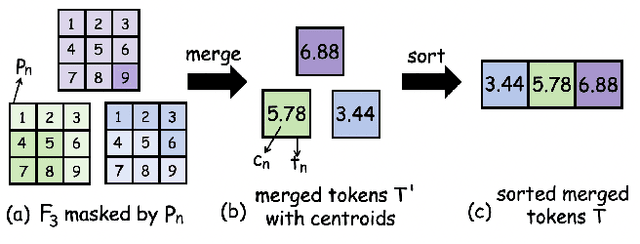
Large Vision-Language Models (LVLMs) usually suffer from prohibitive computational and memory costs due to the quadratic growth of visual tokens with image resolution. Existing token compression methods, while varied, often lack a high-level semantic understanding, leading to suboptimal merges, information redundancy, or context loss. To address these limitations, we introduce CORE (Compact Object-centric REpresentations), a new paradigm for visual token compression. CORE leverages an efficient segmentation decoder to generate object masks, which serve as a high-level semantic prior to guide the merging of visual tokens into a compact set of object-centric representations. Furthermore, a novel centroid-guided sorting mechanism restores a coherent spatial order to the merged tokens, preserving vital positional information. Extensive experiments show that CORE not only establishes a new state-of-the-art on six authoritative benchmarks for fixed-rate compression, but also achieves dramatic efficiency gains in adaptive-rate settings. Even under extreme compression, after aggressively retaining with only 2.2% of all visual tokens, CORE still maintains 97.4% of baseline performance. Our work demonstrates the superiority of object-centric representations for efficient and effective LVLM processing.