 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTritonBench: Benchmarking Large Language Model Capabilities for Generating Triton Operators
Feb 20, 2025Triton, a high-level Python-like language designed for building efficient GPU kernels, is widely adopted in deep learning frameworks due to its portability, flexibility, and accessibility. However, programming and parallel optimization still require considerable trial and error from Triton developers. Despite advances in large language models (LLMs) for conventional code generation, these models struggle to generate accurate, performance-optimized Triton code, as they lack awareness of its specifications and the complexities of GPU programming. More critically, there is an urgent need for systematic evaluations tailored to Triton. In this work, we introduce TritonBench, the first comprehensive benchmark for Triton operator generation. TritonBench features two evaluation channels: a curated set of 184 real-world operators from GitHub and a collection of operators aligned with PyTorch interfaces. Unlike conventional code benchmarks prioritizing functional correctness, TritonBench also profiles efficiency performance on widely deployed GPUs aligned with industry applications. Our study reveals that current state-of-the-art code LLMs struggle to generate efficient Triton operators, highlighting a significant gap in high-performance code generation. TritonBench will be available at https://github.com/thunlp/TritonBench.
APB: Accelerating Distributed Long-Context Inference by Passing Compressed Context Blocks across GPUs
Feb 17, 2025While long-context inference is crucial for advancing large language model (LLM) applications, its prefill speed remains a significant bottleneck. Current approaches, including sequence parallelism strategies and compute reduction through approximate attention mechanisms, still fall short of delivering optimal inference efficiency. This hinders scaling the inputs to longer sequences and processing long-context queries in a timely manner. To address this, we introduce APB, an efficient long-context inference framework that leverages multi-host approximate attention to enhance prefill speed by reducing compute and enhancing parallelism simultaneously. APB introduces a communication mechanism for essential key-value pairs within a sequence parallelism framework, enabling a faster inference speed while maintaining task performance. We implement APB by incorporating a tailored FlashAttn kernel alongside optimized distribution strategies, supporting diverse models and parallelism configurations. APB achieves speedups of up to 9.2x, 4.2x, and 1.6x compared with FlashAttn, RingAttn, and StarAttn, respectively, without any observable task performance degradation. We provide the implementation and experiment code of APB in https://github.com/thunlp/APB.
LimSim Series: An Autonomous Driving Simulation Platform for Validation and Enhancement
Feb 13, 2025Closed-loop simulation environments play a crucial role in the validation and enhancement of autonomous driving systems (ADS). However, certain challenges warrant significant attention, including balancing simulation accuracy with duration, reconciling functionality with practicality, and establishing comprehensive evaluation mechanisms. This paper addresses these challenges by introducing the LimSim Series, a comprehensive simulation platform designed to support the rapid deployment and efficient iteration of ADS. The LimSim Series integrates multi-type information from road networks, employs human-like decision-making and planning algorithms for background vehicles, and introduces the concept of the Area of Interest (AoI) to optimize computational resources. The platform offers a variety of baseline algorithms and user-friendly interfaces, facilitating flexible validation of multiple technical pipelines. Additionally, the LimSim Series incorporates multi-dimensional evaluation metrics, delivering thorough insights into system performance, thus enabling researchers to promptly identify issues for further improvements. Experiments demonstrate that the LimSim Series is compatible with modular, end-to-end, and VLM-based knowledge-driven systems. It can assist in the iteration and updating of ADS by evaluating performance across various scenarios. The code of the LimSim Series is released at: https://github.com/PJLab-ADG/LimSim.
Process Reinforcement through Implicit Rewards
Feb 03, 2025



Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
LearningFlow: Automated Policy Learning Workflow for Urban Driving with Large Language Models
Jan 09, 2025Recent advancements in reinforcement learning (RL) demonstrate the significant potential in autonomous driving. Despite this promise, challenges such as the manual design of reward functions and low sample efficiency in complex environments continue to impede the development of safe and effective driving policies. To tackle these issues, we introduce LearningFlow, an innovative automated policy learning workflow tailored to urban driving. This framework leverages the collaboration of multiple large language model (LLM) agents throughout the RL training process. LearningFlow includes a curriculum sequence generation process and a reward generation process, which work in tandem to guide the RL policy by generating tailored training curricula and reward functions. Particularly, each process is supported by an analysis agent that evaluates training progress and provides critical insights to the generation agent. Through the collaborative efforts of these LLM agents, LearningFlow automates policy learning across a series of complex driving tasks, and it significantly reduces the reliance on manual reward function design while enhancing sample efficiency. Comprehensive experiments are conducted in the high-fidelity CARLA simulator, along with comparisons with other existing methods, to demonstrate the efficacy of our proposed approach. The results demonstrate that LearningFlow excels in generating rewards and curricula. It also achieves superior performance and robust generalization across various driving tasks, as well as commendable adaptation to different RL algorithms.
Densing Law of LLMs
Dec 05, 2024



Large Language Models (LLMs) have emerged as a milestone in artificial intelligence, and their performance can improve as the model size increases. However, this scaling brings great challenges to training and inference efficiency, particularly for deploying LLMs in resource-constrained environments, and the scaling trend is becoming increasingly unsustainable. This paper introduces the concept of ``\textit{capacity density}'' as a new metric to evaluate the quality of the LLMs across different scales and describes the trend of LLMs in terms of both effectiveness and efficiency. To calculate the capacity density of a given target LLM, we first introduce a set of reference models and develop a scaling law to predict the downstream performance of these reference models based on their parameter sizes. We then define the \textit{effective parameter size} of the target LLM as the parameter size required by a reference model to achieve equivalent performance, and formalize the capacity density as the ratio of the effective parameter size to the actual parameter size of the target LLM. Capacity density provides a unified framework for assessing both model effectiveness and efficiency. Our further analysis of recent open-source base LLMs reveals an empirical law (the densing law)that the capacity density of LLMs grows exponentially over time. More specifically, using some widely used benchmarks for evaluation, the capacity density of LLMs doubles approximately every three months. The law provides new perspectives to guide future LLM development, emphasizing the importance of improving capacity density to achieve optimal results with minimal computational overhead.
Fancy123: One Image to High-Quality 3D Mesh Generation via Plug-and-Play Deformation
Nov 25, 2024



Generating 3D meshes from a single image is an important but ill-posed task. Existing methods mainly adopt 2D multiview diffusion models to generate intermediate multiview images, and use the Large Reconstruction Model (LRM) to create the final meshes. However, the multiview images exhibit local inconsistencies, and the meshes often lack fidelity to the input image or look blurry. We propose Fancy123, featuring two enhancement modules and an unprojection operation to address the above three issues, respectively. The appearance enhancement module deforms the 2D multiview images to realign misaligned pixels for better multiview consistency. The fidelity enhancement module deforms the 3D mesh to match the input image. The unprojection of the input image and deformed multiview images onto LRM's generated mesh ensures high clarity, discarding LRM's predicted blurry-looking mesh colors. Extensive qualitative and quantitative experiments verify Fancy123's SoTA performance with significant improvement. Also, the two enhancement modules are plug-and-play and work at inference time, allowing seamless integration into various existing single-image-to-3D methods.
KBAlign: Efficient Self Adaptation on Specific Knowledge Bases
Nov 25, 2024



Humans can utilize techniques to quickly acquire knowledge from specific materials in advance, such as creating self-assessment questions, enabling us to achieving related tasks more efficiently. In contrast, large language models (LLMs) usually relies on retrieval-augmented generation to exploit knowledge materials in an instant manner, or requires external signals such as human preference data and stronger LLM annotations to conduct knowledge adaptation. To unleash the self-learning potential of LLMs, we propose KBAlign, an approach designed for efficient adaptation to downstream tasks involving knowledge bases. Our method utilizes iterative training with self-annotated data such as Q&A pairs and revision suggestions, enabling the model to grasp the knowledge content efficiently. Experimental results on multiple datasets demonstrate the effectiveness of our approach, significantly boosting model performance in downstream tasks that require specific knowledge at a low cost. Notably, our approach achieves over 90% of the performance improvement that can be obtained by using GPT-4-turbo annotation, while relying entirely on self-supervision. We release our experimental data, models, and process analyses to the community for further exploration (https://github.com/thunlp/KBAlign).
Flexible electrical impedance tomography for tactile interfaces
Nov 20, 2024



Flexible electrical impedance tomography (EIT) is an emerging technology for tactile sensing in human-machine interfaces (HMI). It offers a unique alternative to traditional array-based tactile sensors with its flexible, scalable, and cost-effective one-piece design. This paper proposes a lattice-patterned flexible EIT tactile sensor with a hydrogel-based conductive layer, designed for enhanced sensitivity while maintaining durability. We conducted simulation studies to explore the influence of lattice width and conductive layer thickness on sensor performance, establishing optimized sensor design parameters for enhanced functionality. Experimental evaluations demonstrate the sensor's capacity to detect diverse tactile patterns with a high accuracy. The practical utility of the sensor is demonstrated through its integration within an HMI setup to control a virtual game, showcasing its potential for dynamic, multi-functional tactile interactions in real-time applications. This study reinforces the potential of EIT-based flexible tactile sensors, establishing a foundation for future advancements in wearable, adaptable HMI technologies.
SignEye: Traffic Sign Interpretation from Vehicle First-Person View
Nov 18, 2024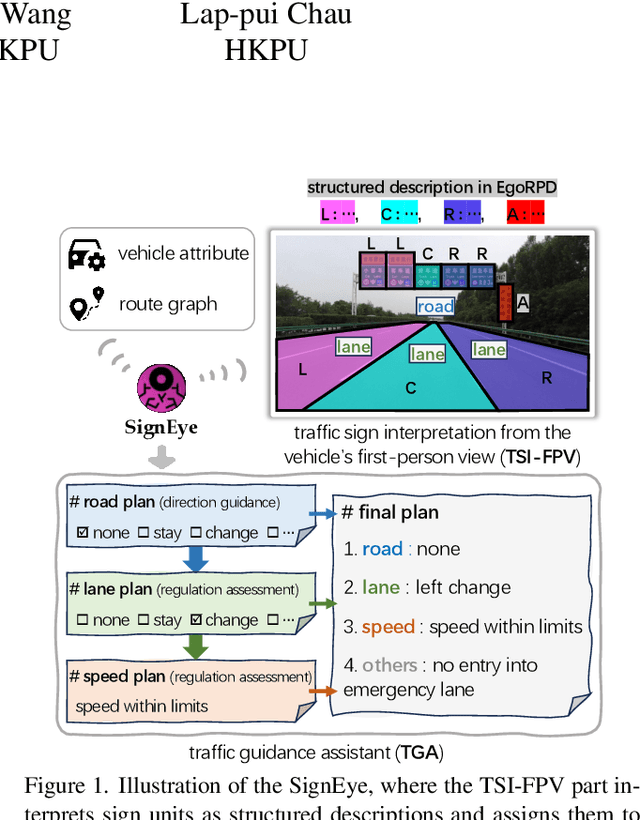

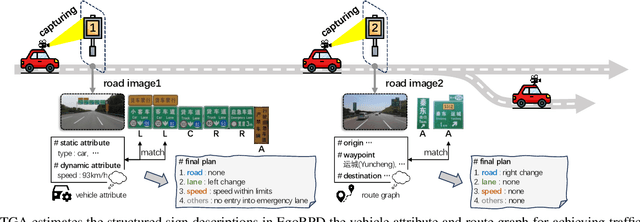

Traffic signs play a key role in assisting autonomous driving systems (ADS) by enabling the assessment of vehicle behavior in compliance with traffic regulations and providing navigation instructions. However, current works are limited to basic sign understanding without considering the egocentric vehicle's spatial position, which fails to support further regulation assessment and direction navigation. Following the above issues, we introduce a new task: traffic sign interpretation from the vehicle's first-person view, referred to as TSI-FPV. Meanwhile, we develop a traffic guidance assistant (TGA) scenario application to re-explore the role of traffic signs in ADS as a complement to popular autonomous technologies (such as obstacle perception). Notably, TGA is not a replacement for electronic map navigation; rather, TGA can be an automatic tool for updating it and complementing it in situations such as offline conditions or temporary sign adjustments. Lastly, a spatial and semantic logic-aware stepwise reasoning pipeline (SignEye) is constructed to achieve the TSI-FPV and TGA, and an application-specific dataset (Traffic-CN) is built. Experiments show that TSI-FPV and TGA are achievable via our SignEye trained on Traffic-CN. The results also demonstrate that the TGA can provide complementary information to ADS beyond existing popular autonomous technologies.