 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning on LLM Back Generation Treebank for Cross-domain Constituency Parsing
May 27, 2025Cross-domain constituency parsing is still an unsolved challenge in computational linguistics since the available multi-domain constituency treebank is limited. We investigate automatic treebank generation by large language models (LLMs) in this paper. The performance of LLMs on constituency parsing is poor, therefore we propose a novel treebank generation method, LLM back generation, which is similar to the reverse process of constituency parsing. LLM back generation takes the incomplete cross-domain constituency tree with only domain keyword leaf nodes as input and fills the missing words to generate the cross-domain constituency treebank. Besides, we also introduce a span-level contrastive learning pre-training strategy to make full use of the LLM back generation treebank for cross-domain constituency parsing. We verify the effectiveness of our LLM back generation treebank coupled with contrastive learning pre-training on five target domains of MCTB. Experimental results show that our approach achieves state-of-the-art performance on average results compared with various baselines.
ChartEdit: How Far Are MLLMs From Automating Chart Analysis? Evaluating MLLMs' Capability via Chart Editing
May 17, 2025Although multimodal large language models (MLLMs) show promise in generating chart rendering code, chart editing presents a greater challenge. This difficulty stems from its nature as a labor-intensive task for humans that also demands MLLMs to integrate chart understanding, complex reasoning, and precise intent interpretation. While many MLLMs claim such editing capabilities, current assessments typically rely on limited case studies rather than robust evaluation methodologies, highlighting the urgent need for a comprehensive evaluation framework. In this work, we propose ChartEdit, a new high-quality benchmark designed for chart editing tasks. This benchmark comprises $1,405$ diverse editing instructions applied to $233$ real-world charts, with each instruction-chart instance having been manually annotated and validated for accuracy. Utilizing ChartEdit, we evaluate the performance of 10 mainstream MLLMs across two types of experiments, assessing them at both the code and chart levels. The results suggest that large-scale models can generate code to produce images that partially match the reference images. However, their ability to generate accurate edits according to the instructions remains limited. The state-of-the-art (SOTA) model achieves a score of only $59.96$, highlighting significant challenges in precise modification. In contrast, small-scale models, including chart-domain models, struggle both with following editing instructions and generating overall chart images, underscoring the need for further development in this area. Code is available at https://github.com/xxlllz/ChartEdit.
TritonBench: Benchmarking Large Language Model Capabilities for Generating Triton Operators
Feb 20, 2025Triton, a high-level Python-like language designed for building efficient GPU kernels, is widely adopted in deep learning frameworks due to its portability, flexibility, and accessibility. However, programming and parallel optimization still require considerable trial and error from Triton developers. Despite advances in large language models (LLMs) for conventional code generation, these models struggle to generate accurate, performance-optimized Triton code, as they lack awareness of its specifications and the complexities of GPU programming. More critically, there is an urgent need for systematic evaluations tailored to Triton. In this work, we introduce TritonBench, the first comprehensive benchmark for Triton operator generation. TritonBench features two evaluation channels: a curated set of 184 real-world operators from GitHub and a collection of operators aligned with PyTorch interfaces. Unlike conventional code benchmarks prioritizing functional correctness, TritonBench also profiles efficiency performance on widely deployed GPUs aligned with industry applications. Our study reveals that current state-of-the-art code LLMs struggle to generate efficient Triton operators, highlighting a significant gap in high-performance code generation. TritonBench will be available at https://github.com/thunlp/TritonBench.
LLM-enhanced Self-training for Cross-domain Constituency Parsing
Nov 05, 2023Self-training has proven to be an effective approach for cross-domain tasks, and in this study, we explore its application to cross-domain constituency parsing. Traditional self-training methods rely on limited and potentially low-quality raw corpora. To overcome this limitation, we propose enhancing self-training with the large language model (LLM) to generate domain-specific raw corpora iteratively. For the constituency parsing, we introduce grammar rules that guide the LLM in generating raw corpora and establish criteria for selecting pseudo instances. Our experimental results demonstrate that self-training for constituency parsing, equipped with an LLM, outperforms traditional methods regardless of the LLM's performance. Moreover, the combination of grammar rules and confidence criteria for pseudo-data selection yields the highest performance in the cross-domain constituency parsing.
Word Graph Guided Summarization for Radiology Findings
Dec 18, 2021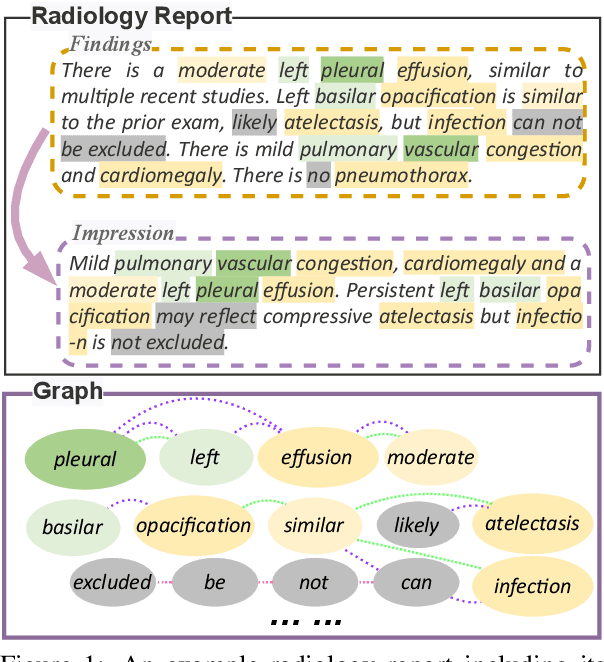
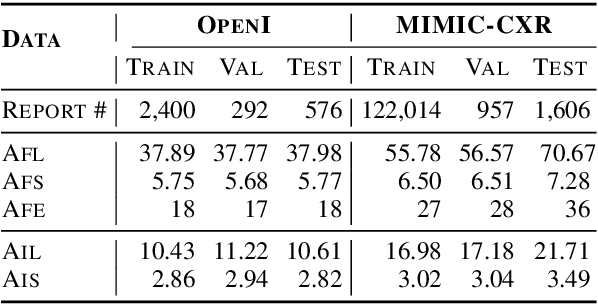
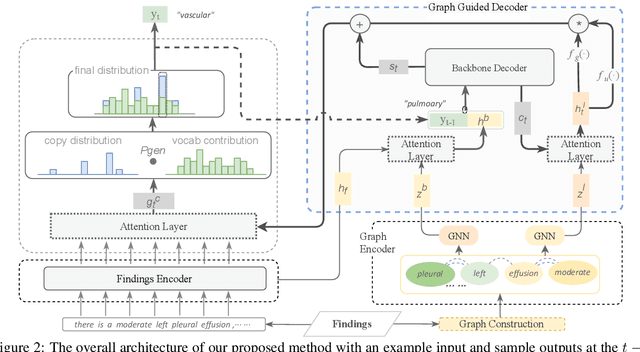
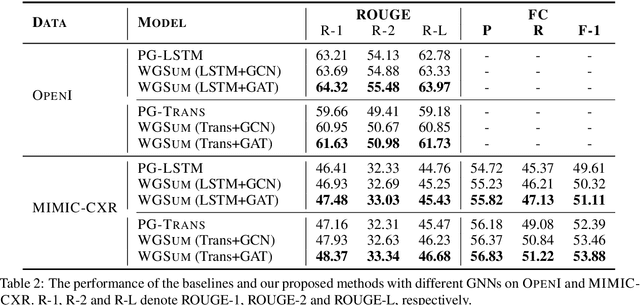
Radiology reports play a critical role in communicating medical findings to physicians. In each report, the impression section summarizes essential radiology findings. In clinical practice, writing impression is highly demanded yet time-consuming and prone to errors for radiologists. Therefore, automatic impression generation has emerged as an attractive research direction to facilitate such clinical practice. Existing studies mainly focused on introducing salient word information to the general text summarization framework to guide the selection of the key content in radiology findings. However, for this task, a model needs not only capture the important words in findings but also accurately describe their relations so as to generate high-quality impressions. In this paper, we propose a novel method for automatic impression generation, where a word graph is constructed from the findings to record the critical words and their relations, then a Word Graph guided Summarization model (WGSum) is designed to generate impressions with the help of the word graph. Experimental results on two datasets, OpenI and MIMIC-CXR, confirm the validity and effectiveness of our proposed approach, where the state-of-the-art results are achieved on both datasets. Further experiments are also conducted to analyze the impact of different graph designs to the performance of our method.