 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasking Stale Observations Helps Search Agents -- Until It Doesn't: A Regime Map and Its Mechanism
May 29, 2026Long-horizon search agents accumulate large amounts of retrieved content across many tool calls, making context-budget efficiency increasingly important. A minimal intervention is to mask stale observations from the context as the trajectory progresses, but it remains unclear when this form of context management helps and why. We study observation masking through a systematic sweep over various agent backbones (4B to 284B parameters) and three retrievers on offline and live-web agentic search benchmarks. We find that the accuracy gain from masking follows an asymmetric inverted-U shape when plotted against the model's accuracy without context management: a plateau under weak retrievers, a peak when a strong retriever meets a mid-capacity model, and a sharp collapse when the model is saturated. This pattern reflects the interaction between retriever recall and the model's implicit filtering capacity, rather than either factor in isolation. Mechanistically, masking implements a token-for-turn trade-off: it removes observations the model has largely stopped attending to and pages the agent rarely re-opens. The added turns help when they convert failures into successes, but they fail when masking removes evidence the model would otherwise have used. We therefore reframe context management as a regime-dependent intervention and provide a holistic perspective for analyzing context use in agentic deep search. We release our scaffold and trajectories here (https://github.com/i-DeepSearch/observation-masking) to support future research.
Bad Seeing or Bad Thinking? Rewarding Perception for Vision-Language Reasoning
May 13, 2026Achieving robust perception-reasoning synergy is a central goal for advanced Vision-Language Models (VLMs). Recent advancements have pursued this goal via architectural designs or agentic workflows. However, these approaches are often limited by static textual reasoning or complicated by the significant compute and engineering burden of external agentic complexity. Worse, this heavy investment does not yield proportional gains, often witnessing a "seesaw effect" on perception and reasoning. This motivates a fundamental rethinking of the true bottleneck. In this paper, we argue that the root cause of this trade-off is an ambiguity in modality credit assignment: when a VLM fails, is it due to flawed perception ("bad seeing") or flawed logic ("bad thinking")? To resolve this, we introduce a reinforcement learning framework that improves perception-reasoning synergy by reliably rewarding the perception fidelity. We explicitly decompose the generation process into interleaved perception and reasoning steps. This decoupling enables targeted supervision on perception. Crucially, we introduce Perception Verification (PV), leveraging a "blindfolded reasoning" proxy to reward perceptual fidelity independently of reasoning outcomes. Furthermore, to scale training across free-form VL tasks, we propose Structured Verbal Verification, which replaces high-variance LLM judging with structured algorithmic execution. These techniques are integrated into a Modality-Aware Credit Assignment (MoCA) mechanism, which routes rewards to the specific source of error -- either bad seeing or bad thinking -- enabling a single VLM to achieve simultaneous performance gains across a wide task spectrum.
CogDoc: Towards Unified thinking in Documents
Dec 14, 2025Current document reasoning paradigms are constrained by a fundamental trade-off between scalability (processing long-context documents) and fidelity (capturing fine-grained, multimodal details). To bridge this gap, we propose CogDoc, a unified coarse-to-fine thinking framework that mimics human cognitive processes: a low-resolution "Fast Reading" phase for scalable information localization,followed by a high-resolution "Focused Thinking" phase for deep reasoning. We conduct a rigorous investigation into post-training strategies for the unified thinking framework, demonstrating that a Direct Reinforcement Learning (RL) approach outperforms RL with Supervised Fine-Tuning (SFT) initialization. Specifically, we find that direct RL avoids the "policy conflict" observed in SFT. Empirically, our 7B model achieves state-of-the-art performance within its parameter class, notably surpassing significantly larger proprietary models (e.g., GPT-4o) on challenging, visually rich document benchmarks.
Emergent Hierarchical Reasoning in LLMs through Reinforcement Learning
Sep 03, 2025

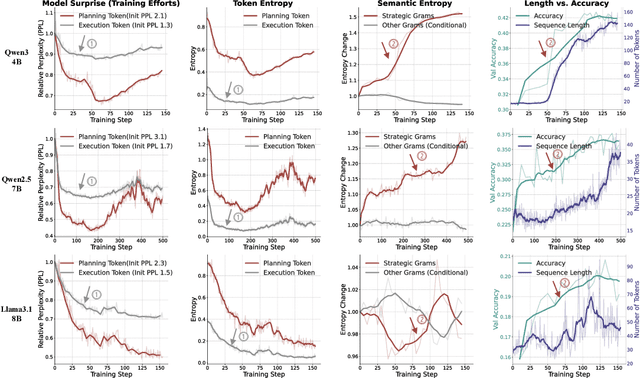

Reinforcement Learning (RL) has proven highly effective at enhancing the complex reasoning abilities of Large Language Models (LLMs), yet underlying mechanisms driving this success remain largely opaque. Our analysis reveals that puzzling phenomena like ``aha moments", ``length-scaling'' and entropy dynamics are not disparate occurrences but hallmarks of an emergent reasoning hierarchy, akin to the separation of high-level strategic planning from low-level procedural execution in human cognition. We uncover a compelling two-phase dynamic: initially, a model is constrained by procedural correctness and must improve its low-level skills. The learning bottleneck then decisively shifts, with performance gains being driven by the exploration and mastery of high-level strategic planning. This insight exposes a core inefficiency in prevailing RL algorithms like GRPO, which apply optimization pressure agnostically and dilute the learning signal across all tokens. To address this, we propose HIerarchy-Aware Credit Assignment (HICRA), an algorithm that concentrates optimization efforts on high-impact planning tokens. HICRA significantly outperforms strong baselines, demonstrating that focusing on this strategic bottleneck is key to unlocking advanced reasoning. Furthermore, we validate semantic entropy as a superior compass for measuring strategic exploration over misleading metrics such as token-level entropy.
Process Reinforcement through Implicit Rewards
Feb 03, 2025



Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
Leveraging Frequent Query Substructures to Generate Formal Queries for Complex Question Answering
Aug 29, 2019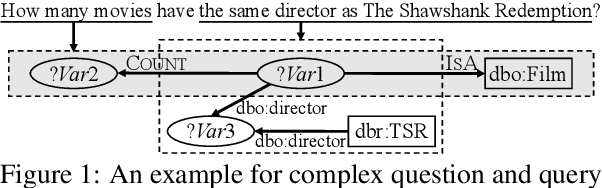

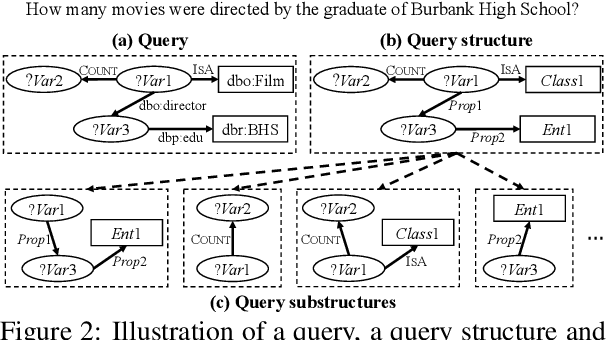

Formal query generation aims to generate correct executable queries for question answering over knowledge bases (KBs), given entity and relation linking results. Current approaches build universal paraphrasing or ranking models for the whole questions, which are likely to fail in generating queries for complex, long-tail questions. In this paper, we propose SubQG, a new query generation approach based on frequent query substructures, which helps rank the existing (but nonsignificant) query structures or build new query structures. Our experiments on two benchmark datasets show that our approach significantly outperforms the existing ones, especially for complex questions. Also, it achieves promising performance with limited training data and noisy entity/relation linking results.