 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDAA-Diff: CT-Guided Multi-Dose Adaptive Attention Diffusion Model for PET Denoising
May 08, 2025Acquiring high-quality Positron Emission Tomography (PET) images requires administering high-dose radiotracers, which increases radiation exposure risks. Generating standard-dose PET (SPET) from low-dose PET (LPET) has become a potential solution. However, previous studies have primarily focused on single low-dose PET denoising, neglecting two critical factors: discrepancies in dose response caused by inter-patient variability, and complementary anatomical constraints derived from CT images. In this work, we propose a novel CT-Guided Multi-dose Adaptive Attention Denoising Diffusion Model (MDAA-Diff) for multi-dose PET denoising. Our approach integrates anatomical guidance and dose-level adaptation to achieve superior denoising performance under low-dose conditions. Specifically, this approach incorporates a CT-Guided High-frequency Wavelet Attention (HWA) module, which uses wavelet transforms to separate high-frequency anatomical boundary features from CT images. These extracted features are then incorporated into PET imaging through an adaptive weighted fusion mechanism to enhance edge details. Additionally, we propose the Dose-Adaptive Attention (DAA) module, a dose-conditioned enhancement mechanism that dynamically integrates dose levels into channel-spatial attention weight calculation. Extensive experiments on 18F-FDG and 68Ga-FAPI datasets demonstrate that MDAA-Diff outperforms state-of-the-art approaches in preserving diagnostic quality under reduced-dose conditions. Our code is publicly available.
Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
May 08, 2025



Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.
Optimized Lattice-Structured Flexible EIT Sensor for Tactile Reconstruction and Classification
Apr 30, 2025Flexible electrical impedance tomography (EIT) offers a promising alternative to traditional tactile sensing approaches, enabling low-cost, scalable, and deformable sensor designs. Here, we propose an optimized lattice-structured flexible EIT tactile sensor incorporating a hydrogel-based conductive layer, systematically designed through three-dimensional coupling field simulations to optimize structural parameters for enhanced sensitivity and robustness. By tuning the lattice channel width and conductive layer thickness, we achieve significant improvements in tactile reconstruction quality and classification performance. Experimental results demonstrate high-quality tactile reconstruction with correlation coefficients up to 0.9275, peak signal-to-noise ratios reaching 29.0303 dB, and structural similarity indexes up to 0.9660, while maintaining low relative errors down to 0.3798. Furthermore, the optimized sensor accurately classifies 12 distinct tactile stimuli with an accuracy reaching 99.6%. These results highlight the potential of simulation-guided structural optimization for advancing flexible EIT-based tactile sensors toward practical applications in wearable systems, robotics, and human-machine interfaces.
Context-Aware Adaptive Sampling for Intelligent Data Acquisition Systems Using DQN
Apr 12, 2025
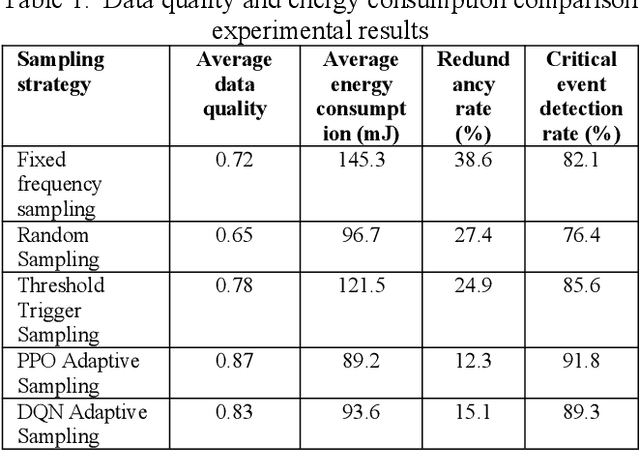


Multi-sensor systems are widely used in the Internet of Things, environmental monitoring, and intelligent manufacturing. However, traditional fixed-frequency sampling strategies often lead to severe data redundancy, high energy consumption, and limited adaptability, failing to meet the dynamic sensing needs of complex environments. To address these issues, this paper proposes a DQN-based multi-sensor adaptive sampling optimization method. By leveraging a reinforcement learning framework to learn the optimal sampling strategy, the method balances data quality, energy consumption, and redundancy. We first model the multi-sensor sampling task as a Markov Decision Process (MDP), then employ a Deep Q-Network to optimize the sampling policy. Experiments on the Intel Lab Data dataset confirm that, compared with fixed-frequency sampling, threshold-triggered sampling, and other reinforcement learning approaches, DQN significantly improves data quality while lowering average energy consumption and redundancy rates. Moreover, in heterogeneous multi-sensor environments, DQN-based adaptive sampling shows enhanced robustness, maintaining superior data collection performance even in the presence of interference factors. These findings demonstrate that DQN-based adaptive sampling can enhance overall data acquisition efficiency in multi-sensor systems, providing a new solution for efficient and intelligent sensing.
HarmonySeg: Tubular Structure Segmentation with Deep-Shallow Feature Fusion and Growth-Suppression Balanced Loss
Apr 10, 2025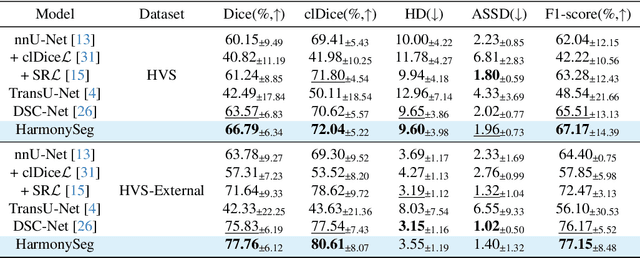

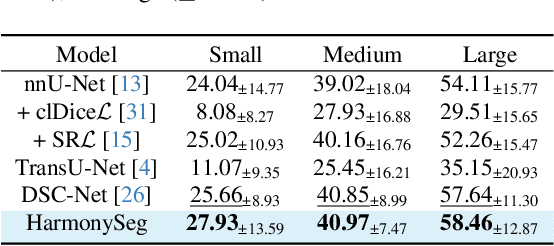
Accurate segmentation of tubular structures in medical images, such as vessels and airway trees, is crucial for computer-aided diagnosis, radiotherapy, and surgical planning. However, significant challenges exist in algorithm design when faced with diverse sizes, complex topologies, and (often) incomplete data annotation of these structures. We address these difficulties by proposing a new tubular structure segmentation framework named HarmonySeg. First, we design a deep-to-shallow decoder network featuring flexible convolution blocks with varying receptive fields, which enables the model to effectively adapt to tubular structures of different scales. Second, to highlight potential anatomical regions and improve the recall of small tubular structures, we incorporate vesselness maps as auxiliary information. These maps are aligned with image features through a shallow-and-deep fusion module, which simultaneously eliminates unreasonable candidates to maintain high precision. Finally, we introduce a topology-preserving loss function that leverages contextual and shape priors to balance the growth and suppression of tubular structures, which also allows the model to handle low-quality and incomplete annotations. Extensive quantitative experiments are conducted on four public datasets. The results show that our model can accurately segment 2D and 3D tubular structures and outperform existing state-of-the-art methods. External validation on a private dataset also demonstrates good generalizability.
Edge Approximation Text Detector
Apr 05, 2025



Pursuing efficient text shape representations helps scene text detection models focus on compact foreground regions and optimize the contour reconstruction steps to simplify the whole detection pipeline. Current approaches either represent irregular shapes via box-to-polygon strategy or decomposing a contour into pieces for fitting gradually, the deficiency of coarse contours or complex pipelines always exists in these models. Considering the above issues, we introduce EdgeText to fit text contours compactly while alleviating excessive contour rebuilding processes. Concretely, it is observed that the two long edges of texts can be regarded as smooth curves. It allows us to build contours via continuous and smooth edges that cover text regions tightly instead of fitting piecewise, which helps avoid the two limitations in current models. Inspired by this observation, EdgeText formulates the text representation as the edge approximation problem via parameterized curve fitting functions. In the inference stage, our model starts with locating text centers, and then creating curve functions for approximating text edges relying on the points. Meanwhile, truncation points are determined based on the location features. In the end, extracting curve segments from curve functions by using the pixel coordinate information brought by truncation points to reconstruct text contours. Furthermore, considering the deep dependency of EdgeText on text edges, a bilateral enhanced perception (BEP) module is designed. It encourages our model to pay attention to the recognition of edge features. Additionally, to accelerate the learning of the curve function parameters, we introduce a proportional integral loss (PI-loss) to force the proposed model to focus on the curve distribution and avoid being disturbed by text scales.
Improving Harmful Text Detection with Joint Retrieval and External Knowledge
Apr 03, 2025Harmful text detection has become a crucial task in the development and deployment of large language models, especially as AI-generated content continues to expand across digital platforms. This study proposes a joint retrieval framework that integrates pre-trained language models with knowledge graphs to improve the accuracy and robustness of harmful text detection. Experimental results demonstrate that the joint retrieval approach significantly outperforms single-model baselines, particularly in low-resource training scenarios and multilingual environments. The proposed method effectively captures nuanced harmful content by leveraging external contextual information, addressing the limitations of traditional detection models. Future research should focus on optimizing computational efficiency, enhancing model interpretability, and expanding multimodal detection capabilities to better tackle evolving harmful content patterns. This work contributes to the advancement of AI safety, ensuring more trustworthy and reliable content moderation systems.
Cost-Optimal Grouped-Query Attention for Long-Context LLMs
Mar 12, 2025Building effective and efficient Transformer-based large language models (LLMs) has recently become a research focus, requiring maximizing model language capabilities and minimizing training and deployment costs. Existing efforts have primarily described complex relationships among model performance, parameter size, and data size, as well as searched for the optimal compute allocation to train LLMs. However, they overlook the impacts of context length and attention head configuration (the number of query and key-value heads in grouped-query attention) on training and inference. In this paper, we systematically compare models with different parameter sizes, context lengths, and attention head configurations in terms of model performance, computational cost, and memory cost. Then, we extend the existing scaling methods, which are based solely on parameter size and training compute, to guide the construction of cost-optimal LLMs during both training and inference. Our quantitative scaling studies show that, when processing sufficiently long sequences, a larger model with fewer attention heads can achieve a lower loss while incurring lower computational and memory costs. Our findings provide valuable insights for developing practical LLMs, especially in long-context processing scenarios. We will publicly release our code and data.
Traffic Regulation-aware Path Planning with Regulation Databases and Vision-Language Models
Mar 12, 2025



This paper introduces and tests a framework integrating traffic regulation compliance into automated driving systems (ADS). The framework enables ADS to follow traffic laws and make informed decisions based on the driving environment. Using RGB camera inputs and a vision-language model (VLM), the system generates descriptive text to support a regulation-aware decision-making process, ensuring legal and safe driving practices. This information is combined with a machine-readable ADS regulation database to guide future driving plans within legal constraints. Key features include: 1) a regulation database supporting ADS decision-making, 2) an automated process using sensor input for regulation-aware path planning, and 3) validation in both simulated and real-world environments. Particularly, the real-world vehicle tests not only assess the framework's performance but also evaluate the potential and challenges of VLMs to solve complex driving problems by integrating detection, reasoning, and planning. This work enhances the legality, safety, and public trust in ADS, representing a significant step forward in the field.
FR-Spec: Accelerating Large-Vocabulary Language Models via Frequency-Ranked Speculative Sampling
Feb 20, 2025Speculative sampling has emerged as an important technique for accelerating the auto-regressive generation process of large language models (LLMs) by utilizing a draft-then-verify mechanism to produce multiple tokens per forward pass. While state-of-the-art speculative sampling methods use only a single layer and a language modeling (LM) head as the draft model to achieve impressive layer compression, their efficiency gains are substantially reduced for large-vocabulary LLMs, such as Llama-3-8B with a vocabulary of 128k tokens. To address this, we present FR-Spec, a frequency-ranked speculative sampling framework that optimizes draft candidate selection through vocabulary space compression. By constraining the draft search to a frequency-prioritized token subset, our method reduces LM Head computation overhead by 75% while ensuring the equivalence of the final output distribution. Experiments across multiple datasets demonstrate an average of 1.12$\times$ speedup over the state-of-the-art speculative sampling method EAGLE-2.