 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioral Anomaly Detection in Distributed Systems via Federated Contrastive Learning
Jun 24, 2025


This paper addresses the increasingly prominent problem of anomaly detection in distributed systems. It proposes a detection method based on federated contrastive learning. The goal is to overcome the limitations of traditional centralized approaches in terms of data privacy, node heterogeneity, and anomaly pattern recognition. The proposed method combines the distributed collaborative modeling capabilities of federated learning with the feature discrimination enhancement of contrastive learning. It builds embedding representations on local nodes and constructs positive and negative sample pairs to guide the model in learning a more discriminative feature space. Without exposing raw data, the method optimizes a global model through a federated aggregation strategy. Specifically, the method uses an encoder to represent local behavior data in high-dimensional space. This includes system logs, operational metrics, and system calls. The model is trained using both contrastive loss and classification loss to improve its ability to detect fine-grained anomaly patterns. The method is evaluated under multiple typical attack types. It is also tested in a simulated real-time data stream scenario to examine its responsiveness. Experimental results show that the proposed method outperforms existing approaches across multiple performance metrics. It demonstrates strong detection accuracy and adaptability, effectively addressing complex anomalies in distributed environments. Through careful design of key modules and optimization of the training mechanism, the proposed method achieves a balance between privacy preservation and detection performance. It offers a feasible technical path for intelligent security management in distributed systems.
Joint Graph Convolution and Sequential Modeling for Scalable Network Traffic Estimation
May 12, 2025This study focuses on the challenge of predicting network traffic within complex topological environments. It introduces a spatiotemporal modeling approach that integrates Graph Convolutional Networks (GCN) with Gated Recurrent Units (GRU). The GCN component captures spatial dependencies among network nodes, while the GRU component models the temporal evolution of traffic data. This combination allows for precise forecasting of future traffic patterns. The effectiveness of the proposed model is validated through comprehensive experiments on the real-world Abilene network traffic dataset. The model is benchmarked against several popular deep learning methods. Furthermore, a set of ablation experiments is conducted to examine the influence of various components on performance, including changes in the number of graph convolution layers, different temporal modeling strategies, and methods for constructing the adjacency matrix. Results indicate that the proposed approach achieves superior performance across multiple metrics, demonstrating robust stability and strong generalization capabilities in complex network traffic forecasting scenarios.
Towards Robust Few-Shot Text Classification Using Transformer Architectures and Dual Loss Strategies
May 09, 2025



Few-shot text classification has important application value in low-resource environments. This paper proposes a strategy that combines adaptive fine-tuning, contrastive learning, and regularization optimization to improve the classification performance of Transformer-based models. Experiments on the FewRel 2.0 dataset show that T5-small, DeBERTa-v3, and RoBERTa-base perform well in few-shot tasks, especially in the 5-shot setting, which can more effectively capture text features and improve classification accuracy. The experiment also found that there are significant differences in the classification difficulty of different relationship categories. Some categories have fuzzy semantic boundaries or complex feature distributions, making it difficult for the standard cross entropy loss to learn the discriminative information required to distinguish categories. By introducing contrastive loss and regularization loss, the generalization ability of the model is enhanced, effectively alleviating the overfitting problem in few-shot environments. In addition, the research results show that the use of Transformer models or generative architectures with stronger self-attention mechanisms can help improve the stability and accuracy of few-shot classification.
Context-Aware Adaptive Sampling for Intelligent Data Acquisition Systems Using DQN
Apr 12, 2025
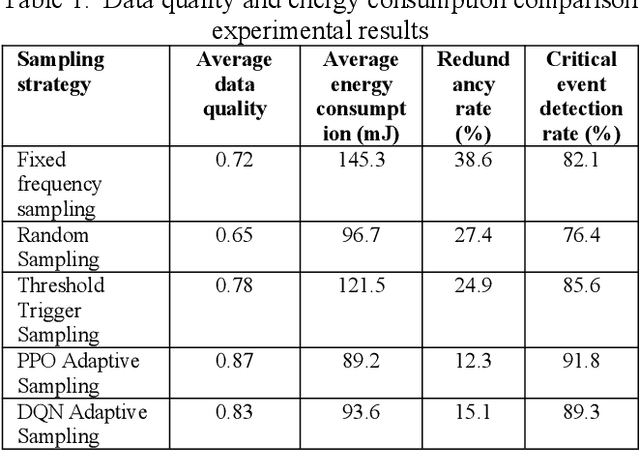


Multi-sensor systems are widely used in the Internet of Things, environmental monitoring, and intelligent manufacturing. However, traditional fixed-frequency sampling strategies often lead to severe data redundancy, high energy consumption, and limited adaptability, failing to meet the dynamic sensing needs of complex environments. To address these issues, this paper proposes a DQN-based multi-sensor adaptive sampling optimization method. By leveraging a reinforcement learning framework to learn the optimal sampling strategy, the method balances data quality, energy consumption, and redundancy. We first model the multi-sensor sampling task as a Markov Decision Process (MDP), then employ a Deep Q-Network to optimize the sampling policy. Experiments on the Intel Lab Data dataset confirm that, compared with fixed-frequency sampling, threshold-triggered sampling, and other reinforcement learning approaches, DQN significantly improves data quality while lowering average energy consumption and redundancy rates. Moreover, in heterogeneous multi-sensor environments, DQN-based adaptive sampling shows enhanced robustness, maintaining superior data collection performance even in the presence of interference factors. These findings demonstrate that DQN-based adaptive sampling can enhance overall data acquisition efficiency in multi-sensor systems, providing a new solution for efficient and intelligent sensing.