 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnbiased Gradient Estimation for Event Binning via Functional Backpropagation
Feb 13, 2026Event-based vision encodes dynamic scenes as asynchronous spatio-temporal spikes called events. To leverage conventional image processing pipelines, events are typically binned into frames. However, binning functions are discontinuous, which truncates gradients at the frame level and forces most event-based algorithms to rely solely on frame-based features. Attempts to directly learn from raw events avoid this restriction but instead suffer from biased gradient estimation due to the discontinuities of the binning operation, ultimately limiting their learning efficiency. To address this challenge, we propose a novel framework for unbiased gradient estimation of arbitrary binning functions by synthesizing weak derivatives during backpropagation while keeping the forward output unchanged. The key idea is to exploit integration by parts: lifting the target functions to functionals yields an integral form of the derivative of the binning function during backpropagation, where the cotangent function naturally arises. By reconstructing this cotangent function from the sampled cotangent vector, we compute weak derivatives that provably match long-range finite differences of both smooth and non-smooth targets. Experimentally, our method improves simple optimization-based egomotion estimation with 3.2\% lower RMS error and 1.57$\times$ faster convergence. On complex downstream tasks, we achieve 9.4\% lower EPE in self-supervised optical flow, and 5.1\% lower RMS error in SLAM, demonstrating broad benefits for event-based visual perception. Source code can be found at https://github.com/chjz1024/EventFBP.
Musical Metamerism with Time--Frequency Scattering
Feb 12, 2026The concept of metamerism originates from colorimetry, where it describes a sensation of visual similarity between two colored lights despite significant differences in spectral content. Likewise, we propose to call ``musical metamerism'' the sensation of auditory similarity which is elicited by two music fragments which differ in terms of underlying waveforms. In this technical report, we describe a method to generate musical metamers from any audio recording. Our method is based on joint time--frequency scattering in Kymatio, an open-source software in Python which enables GPU computing and automatic differentiation. The advantage of our method is that it does not require any manual preprocessing, such as transcription, beat tracking, or source separation. We provide a mathematical description of JTFS as well as some excerpts from the Kymatio source code. Lastly, we review the prior work on JTFS and draw connections with closely related algorithms, such as spectrotemporal receptive fields (STRF), modulation power spectra (MPS), and Gabor filterbank (GBFB).
Evaluating Cognitive-Behavioral Fixation via Multimodal User Viewing Patterns on Social Media
Sep 05, 2025Digital social media platforms frequently contribute to cognitive-behavioral fixation, a phenomenon in which users exhibit sustained and repetitive engagement with narrow content domains. While cognitive-behavioral fixation has been extensively studied in psychology, methods for computationally detecting and evaluating such fixation remain underexplored. To address this gap, we propose a novel framework for assessing cognitive-behavioral fixation by analyzing users' multimodal social media engagement patterns. Specifically, we introduce a multimodal topic extraction module and a cognitive-behavioral fixation quantification module that collaboratively enable adaptive, hierarchical, and interpretable assessment of user behavior. Experiments on existing benchmarks and a newly curated multimodal dataset demonstrate the effectiveness of our approach, laying the groundwork for scalable computational analysis of cognitive fixation. All code in this project is publicly available for research purposes at https://github.com/Liskie/cognitive-fixation-evaluation.
Polarization Reconfigurable Transmit-Receive Beam Alignment with Interpretable Transformer
Aug 17, 2025Recent advancement in next generation reconfigurable antenna and fluid antenna technology has influenced the wireless system with polarization reconfigurable (PR) channels to attract significant attention for promoting beneficial channel condition. We exploit the benefit of PR antennas by integrating such technology into massive multiple-input-multiple-output (MIMO) system. In particular, we aim to jointly design the polarization and beamforming vectors on both transceivers for simultaneous channel reconfiguration and beam alignment, which remarkably enhance the beamforming gain. However, joint optimization over polarization and beamforming vectors without channel state information (CSI) is a challenging task, since depolarization increases the channel dimension; whereas massive MIMO systems typically have low-dimensional pilot measurement from limited radio frequency (RF) chain. This leads to pilot overhead because the transceivers can only observe low-dimensional measurement of the high-dimension channel. This paper pursues the reduction of the pilot overhead in such systems by proposing to employ \emph{interpretable transformer}-based deep learning framework on both transceivers to actively design the polarization and beamforming vectors for pilot stage and transmission stage based on the sequence of accumulated received pilots. Numerical experiments demonstrate the significant performance gain of our proposed framework over the existing non-adaptive and active data-driven methods. Furthermore, we exploit the interpretability of our proposed framework to analyze the learning capabilities of the model.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025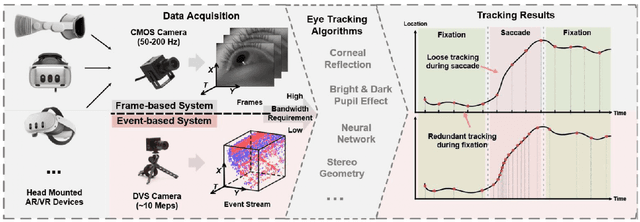
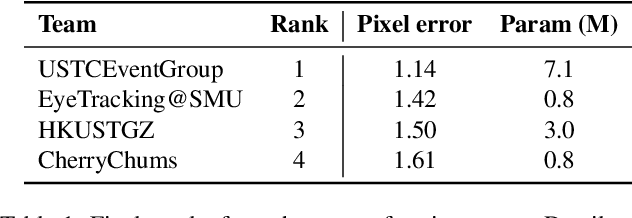
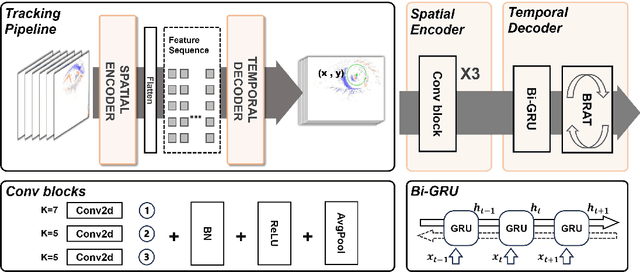

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Edge Approximation Text Detector
Apr 05, 2025



Pursuing efficient text shape representations helps scene text detection models focus on compact foreground regions and optimize the contour reconstruction steps to simplify the whole detection pipeline. Current approaches either represent irregular shapes via box-to-polygon strategy or decomposing a contour into pieces for fitting gradually, the deficiency of coarse contours or complex pipelines always exists in these models. Considering the above issues, we introduce EdgeText to fit text contours compactly while alleviating excessive contour rebuilding processes. Concretely, it is observed that the two long edges of texts can be regarded as smooth curves. It allows us to build contours via continuous and smooth edges that cover text regions tightly instead of fitting piecewise, which helps avoid the two limitations in current models. Inspired by this observation, EdgeText formulates the text representation as the edge approximation problem via parameterized curve fitting functions. In the inference stage, our model starts with locating text centers, and then creating curve functions for approximating text edges relying on the points. Meanwhile, truncation points are determined based on the location features. In the end, extracting curve segments from curve functions by using the pixel coordinate information brought by truncation points to reconstruct text contours. Furthermore, considering the deep dependency of EdgeText on text edges, a bilateral enhanced perception (BEP) module is designed. It encourages our model to pay attention to the recognition of edge features. Additionally, to accelerate the learning of the curve function parameters, we introduce a proportional integral loss (PI-loss) to force the proposed model to focus on the curve distribution and avoid being disturbed by text scales.
Chain-of-Tools: Utilizing Massive Unseen Tools in the CoT Reasoning of Frozen Language Models
Mar 21, 2025Tool learning can further broaden the usage scenarios of large language models (LLMs). However most of the existing methods either need to finetune that the model can only use tools seen in the training data, or add tool demonstrations into the prompt with lower efficiency. In this paper, we present a new Tool Learning method Chain-of-Tools. It makes full use of the powerful semantic representation capability of frozen LLMs to finish tool calling in CoT reasoning with a huge and flexible tool pool which may contain unseen tools. Especially, to validate the effectiveness of our approach in the massive unseen tool scenario, we construct a new dataset SimpleToolQuestions. We conduct experiments on two numerical reasoning benchmarks (GSM8K-XL and FuncQA) and two knowledge-based question answering benchmarks (KAMEL and SimpleToolQuestions). Experimental results show that our approach performs better than the baseline. We also identify dimensions of the model output that are critical in tool selection, enhancing the model interpretability. Our code and data are available at: https://github.com/fairyshine/Chain-of-Tools .
Event-Based Tracking Any Point with Motion-Augmented Temporal Consistency
Dec 02, 2024



Tracking Any Point (TAP) plays a crucial role in motion analysis. Video-based approaches rely on iterative local matching for tracking, but they assume linear motion during the blind time between frames, which leads to target point loss under large displacements or nonlinear motion. The high temporal resolution and motion blur-free characteristics of event cameras provide continuous, fine-grained motion information, capturing subtle variations with microsecond precision. This paper presents an event-based framework for tracking any point, which tackles the challenges posed by spatial sparsity and motion sensitivity in events through two tailored modules. Specifically, to resolve ambiguities caused by event sparsity, a motion-guidance module incorporates kinematic features into the local matching process. Additionally, a variable motion aware module is integrated to ensure temporally consistent responses that are insensitive to varying velocities, thereby enhancing matching precision. To validate the effectiveness of the approach, an event dataset for tracking any point is constructed by simulation, and is applied in experiments together with two real-world datasets. The experimental results show that the proposed method outperforms existing SOTA methods. Moreover, it achieves 150\% faster processing with competitive model parameters.
NesTools: A Dataset for Evaluating Nested Tool Learning Abilities of Large Language Models
Oct 15, 2024Large language models (LLMs) combined with tool learning have gained impressive results in real-world applications. During tool learning, LLMs may call multiple tools in nested orders, where the latter tool call may take the former response as its input parameters. However, current research on the nested tool learning capabilities is still under-explored, since the existing benchmarks lack of relevant data instances. To address this problem, we introduce NesTools to bridge the current gap in comprehensive nested tool learning evaluations. NesTools comprises a novel automatic data generation method to construct large-scale nested tool calls with different nesting structures. With manual review and refinement, the dataset is in high quality and closely aligned with real-world scenarios. Therefore, NesTools can serve as a new benchmark to evaluate the nested tool learning abilities of LLMs. We conduct extensive experiments on 22 LLMs, and provide in-depth analyses with NesTools, which shows that current LLMs still suffer from the complex nested tool learning task.
Double-Side Polarization and Beamforming Alignment in Polarization Reconfigurable MISO System with Deep Neural Networks
Sep 30, 2024Polarization reconfigurable (PR) antennas enhance spectrum and energy efficiency between next-generation node B(gNB) and user equipment (UE). This is achieved by tuning the polarization vectors for each antenna element based on channel state information (CSI). On the other hand, degree of freedom increased by PR antennas yields a challenge in channel estimation with pilot training overhead. This paper pursues the reduction of pilot overhead, and proposes to employ deep neural networks (DNNs) on both transceiver ends to directly optimize the polarization and beamforming vectors based on the received pilots without the explicit channel estimation. Numerical experiments show that the proposed method significantly outperforms the conventional first-estimate-then-optimize scheme by maximum of 20% in beamforming gain.