 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Aware Adaptive Sampling for Intelligent Data Acquisition Systems Using DQN
Apr 12, 2025
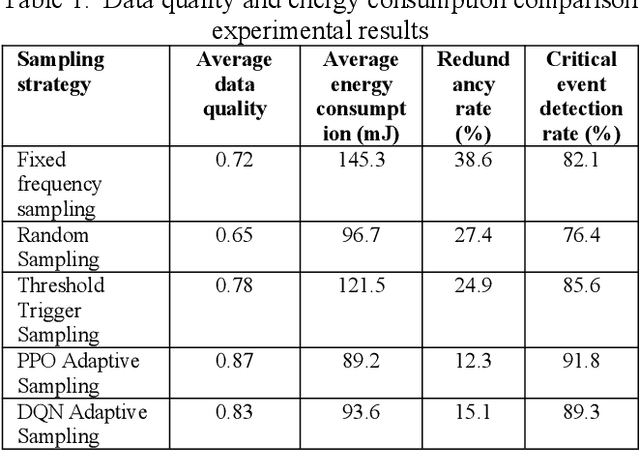


Multi-sensor systems are widely used in the Internet of Things, environmental monitoring, and intelligent manufacturing. However, traditional fixed-frequency sampling strategies often lead to severe data redundancy, high energy consumption, and limited adaptability, failing to meet the dynamic sensing needs of complex environments. To address these issues, this paper proposes a DQN-based multi-sensor adaptive sampling optimization method. By leveraging a reinforcement learning framework to learn the optimal sampling strategy, the method balances data quality, energy consumption, and redundancy. We first model the multi-sensor sampling task as a Markov Decision Process (MDP), then employ a Deep Q-Network to optimize the sampling policy. Experiments on the Intel Lab Data dataset confirm that, compared with fixed-frequency sampling, threshold-triggered sampling, and other reinforcement learning approaches, DQN significantly improves data quality while lowering average energy consumption and redundancy rates. Moreover, in heterogeneous multi-sensor environments, DQN-based adaptive sampling shows enhanced robustness, maintaining superior data collection performance even in the presence of interference factors. These findings demonstrate that DQN-based adaptive sampling can enhance overall data acquisition efficiency in multi-sensor systems, providing a new solution for efficient and intelligent sensing.
A Deep Learning Framework for Boundary-Aware Semantic Segmentation
Mar 28, 2025As a fundamental task in computer vision, semantic segmentation is widely applied in fields such as autonomous driving, remote sensing image analysis, and medical image processing. In recent years, Transformer-based segmentation methods have demonstrated strong performance in global feature modeling. However, they still struggle with blurred target boundaries and insufficient recognition of small targets. To address these issues, this study proposes a Mask2Former-based semantic segmentation algorithm incorporating a boundary enhancement feature bridging module (BEFBM). The goal is to improve target boundary accuracy and segmentation consistency. Built upon the Mask2Former framework, this method constructs a boundary-aware feature map and introduces a feature bridging mechanism. This enables effective cross-scale feature fusion, enhancing the model's ability to focus on target boundaries. Experiments on the Cityscapes dataset demonstrate that, compared to mainstream segmentation methods, the proposed approach achieves significant improvements in metrics such as mIOU, mDICE, and mRecall. It also exhibits superior boundary retention in complex scenes. Visual analysis further confirms the model's advantages in fine-grained regions. Future research will focus on optimizing computational efficiency and exploring its potential in other high-precision segmentation tasks.
A Structured Reasoning Framework for Unbalanced Data Classification Using Probabilistic Models
Feb 05, 2025

This paper studies a Markov network model for unbalanced data, aiming to solve the problems of classification bias and insufficient minority class recognition ability of traditional machine learning models in environments with uneven class distribution. By constructing joint probability distribution and conditional dependency, the model can achieve global modeling and reasoning optimization of sample categories. The study introduced marginal probability estimation and weighted loss optimization strategies, combined with regularization constraints and structured reasoning methods, effectively improving the generalization ability and robustness of the model. In the experimental stage, a real credit card fraud detection dataset was selected and compared with models such as logistic regression, support vector machine, random forest and XGBoost. The experimental results show that the Markov network performs well in indicators such as weighted accuracy, F1 score, and AUC-ROC, significantly outperforming traditional classification models, demonstrating its strong decision-making ability and applicability in unbalanced data scenarios. Future research can focus on efficient model training, structural optimization, and deep learning integration in large-scale unbalanced data environments and promote its wide application in practical applications such as financial risk control, medical diagnosis, and intelligent monitoring.
Object Detection for Medical Image Analysis: Insights from the RT-DETR Model
Jan 27, 2025



Deep learning has emerged as a transformative approach for solving complex pattern recognition and object detection challenges. This paper focuses on the application of a novel detection framework based on the RT-DETR model for analyzing intricate image data, particularly in areas such as diabetic retinopathy detection. Diabetic retinopathy, a leading cause of vision loss globally, requires accurate and efficient image analysis to identify early-stage lesions. The proposed RT-DETR model, built on a Transformer-based architecture, excels at processing high-dimensional and complex visual data with enhanced robustness and accuracy. Comparative evaluations with models such as YOLOv5, YOLOv8, SSD, and DETR demonstrate that RT-DETR achieves superior performance across precision, recall, mAP50, and mAP50-95 metrics, particularly in detecting small-scale objects and densely packed targets. This study underscores the potential of Transformer-based models like RT-DETR for advancing object detection tasks, offering promising applications in medical imaging and beyond.