 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Vision-Language Model Purified Semi-Supervised Semantic Segmentation for Remote Sensing Images
Jan 30, 2026The semi-supervised semantic segmentation (S4) can learn rich visual knowledge from low-cost unlabeled images. However, traditional S4 architectures all face the challenge of low-quality pseudo-labels, especially for the teacher-student framework.We propose a novel SemiEarth model that introduces vision-language models (VLMs) to address the S4 issues for the remote sensing (RS) domain. Specifically, we invent a VLM pseudo-label purifying (VLM-PP) structure to purify the teacher network's pseudo-labels, achieving substantial improvements. Especially in multi-class boundary regions of RS images, the VLM-PP module can significantly improve the quality of pseudo-labels generated by the teacher, thereby correctly guiding the student model's learning. Moreover, since VLM-PP equips VLMs with open-world capabilities and is independent of the S4 architecture, it can correct mispredicted categories in low-confidence pseudo-labels whenever a discrepancy arises between its prediction and the pseudo-label. We conducted extensive experiments on multiple RS datasets, which demonstrate that our SemiEarth achieves SOTA performance. More importantly, unlike previous SOTA RS S4 methods, our model not only achieves excellent performance but also offers good interpretability. The code is released at https://github.com/wangshanwen001/SemiEarth.
ToolWeaver: Weaving Collaborative Semantics for Scalable Tool Use in Large Language Models
Jan 29, 2026Prevalent retrieval-based tool-use pipelines struggle with a dual semantic challenge: their retrievers often employ encoders that fail to capture complex semantics, while the Large Language Model (LLM) itself lacks intrinsic tool knowledge from its natural language pretraining. Generative methods offer a powerful alternative by unifying selection and execution, tasking the LLM to directly learn and generate tool identifiers. However, the common practice of mapping each tool to a unique new token introduces substantial limitations: it creates a scalability and generalization crisis, as the vocabulary size explodes and each tool is assigned a semantically isolated token. This approach also creates a semantic bottleneck that hinders the learning of collaborative tool relationships, as the model must infer them from sparse co-occurrences of monolithic tool IDs within a vast library. To address these limitations, we propose ToolWeaver, a novel generative tool learning framework that encodes tools into hierarchical sequences. This approach makes vocabulary expansion logarithmic to the number of tools. Crucially, it enables the model to learn collaborative patterns from the dense co-occurrence of shared codes, rather than the sparse co-occurrence of monolithic tool IDs. We generate these structured codes through a novel tokenization process designed to weave together a tool's intrinsic semantics with its extrinsic co-usage patterns. These structured codes are then integrated into the LLM through a generative alignment stage, where the model is fine-tuned to produce the hierarchical code sequences. Evaluation results with nearly 47,000 tools show that ToolWeaver significantly outperforms state-of-the-art methods, establishing a more scalable, generalizable, and semantically-aware foundation for advanced tool-augmented agents.
Predict the Retrieval! Test time adaptation for Retrieval Augmented Generation
Jan 16, 2026Retrieval-Augmented Generation (RAG) has emerged as a powerful approach for enhancing large language models' question-answering capabilities through the integration of external knowledge. However, when adapting RAG systems to specialized domains, challenges arise from distribution shifts, resulting in suboptimal generalization performance. In this work, we propose TTARAG, a test-time adaptation method that dynamically updates the language model's parameters during inference to improve RAG system performance in specialized domains. Our method introduces a simple yet effective approach where the model learns to predict retrieved content, enabling automatic parameter adjustment to the target domain. Through extensive experiments across six specialized domains, we demonstrate that TTARAG achieves substantial performance improvements over baseline RAG systems. Code available at https://github.com/sunxin000/TTARAG.
ADHint: Adaptive Hints with Difficulty Priors for Reinforcement Learning
Dec 15, 2025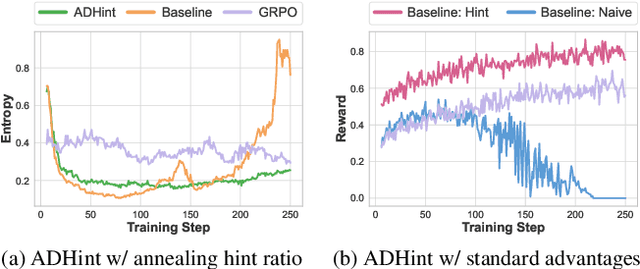
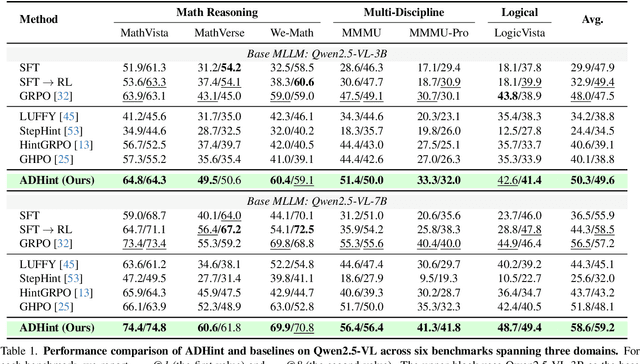
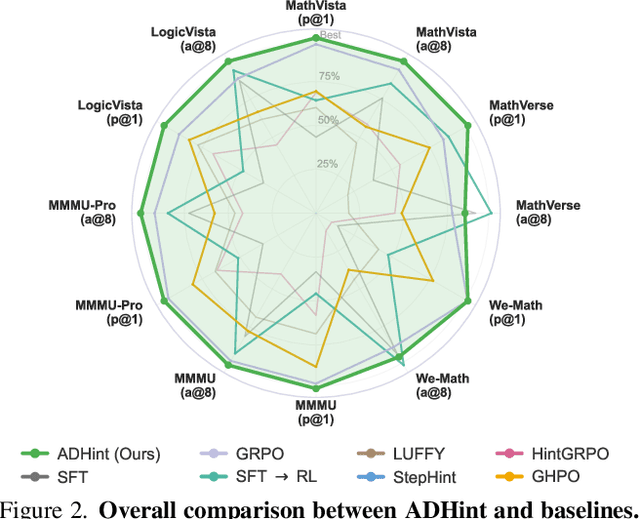
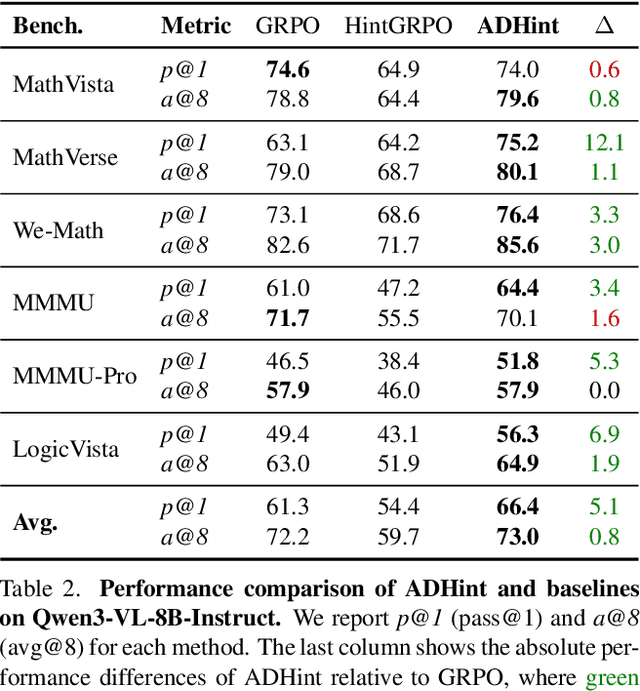
To combine the advantages of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), recent methods have integrated ''hints'' into post-training, which are prefix segments of complete reasoning trajectories, aiming for powerful knowledge expansion and reasoning generalization. However, existing hint-based RL methods typically ignore difficulty when scheduling hint ratios and estimating relative advantages, leading to unstable learning and excessive imitation of off-policy hints. In this work, we propose ADHint, which treats difficulty as a key factor in both hint-ratio schedule and relative-advantage estimation to achieve a better trade-off between exploration and imitation. Specifically, we propose Adaptive Hint with Sample Difficulty Prior, which evaluates each sample's difficulty under the policy model and accordingly schedules an appropriate hint ratio to guide its rollouts. We also introduce Consistency-based Gradient Modulation and Selective Masking for Hint Preservation to modulate token-level gradients within hints, preventing biased and destructive updates. Additionally, we propose Advantage Estimation with Rollout Difficulty Posterior, which leverages the relative difficulty of rollouts with and without hints to estimate their respective advantages, thereby achieving more balanced updates. Extensive experiments across diverse modalities, model scales, and domains demonstrate that ADHint delivers superior reasoning ability and out-of-distribution generalization, consistently surpassing existing methods in both pass@1 and avg@8. Our code and dataset will be made publicly available upon paper acceptance.
KBQA-R1: Reinforcing Large Language Models for Knowledge Base Question Answering
Dec 10, 2025Knowledge Base Question Answering (KBQA) challenges models to bridge the gap between natural language and strict knowledge graph schemas by generating executable logical forms. While Large Language Models (LLMs) have advanced this field, current approaches often struggle with a dichotomy of failure: they either generate hallucinated queries without verifying schema existence or exhibit rigid, template-based reasoning that mimics synthesized traces without true comprehension of the environment. To address these limitations, we present \textbf{KBQA-R1}, a framework that shifts the paradigm from text imitation to interaction optimization via Reinforcement Learning. Treating KBQA as a multi-turn decision process, our model learns to navigate the knowledge base using a list of actions, leveraging Group Relative Policy Optimization (GRPO) to refine its strategies based on concrete execution feedback rather than static supervision. Furthermore, we introduce \textbf{Referenced Rejection Sampling (RRS)}, a data synthesis method that resolves cold-start challenges by strictly aligning reasoning traces with ground-truth action sequences. Extensive experiments on WebQSP, GrailQA, and GraphQuestions demonstrate that KBQA-R1 achieves state-of-the-art performance, effectively grounding LLM reasoning in verifiable execution.
Quality Assurance of LLM-generated Code: Addressing Non-Functional Quality Characteristics
Nov 13, 2025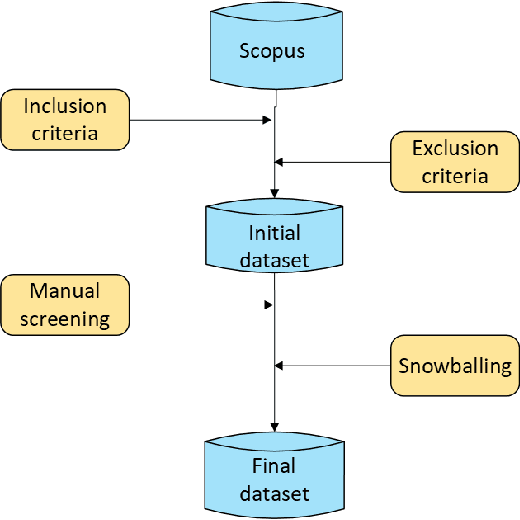
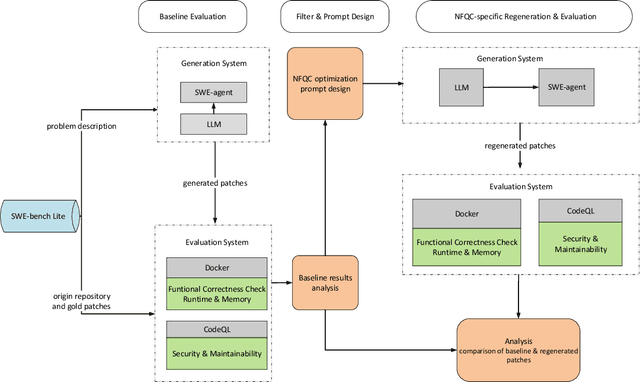
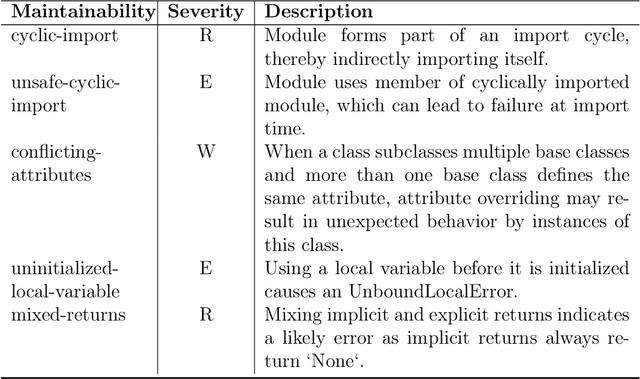

In recent years, LLMs have been widely integrated into software engineering workflows, supporting tasks like code generation. However, while these models often generate functionally correct outputs, we still lack a systematic understanding and evaluation of their non-functional qualities. Existing studies focus mainly on whether generated code passes the tests rather than whether it passes with quality. Guided by the ISO/IEC 25010 quality model, this study conducted three complementary investigations: a systematic review of 108 papers, two industry workshops with practitioners from multiple organizations, and an empirical analysis of patching real-world software issues using three LLMs. Motivated by insights from both the literature and practitioners, the empirical study examined the quality of generated patches on security, maintainability, and performance efficiency. Across the literature, we found that security and performance efficiency dominate academic attention, while maintainability and other qualities are understudied. In contrast, industry experts prioritize maintainability and readability, warning that generated code may accelerate the accumulation of technical debt. In our evaluation of functionally correct patches generated by three LLMs, improvements in one quality dimension often come at the cost of others. Runtime and memory results further show high variance across models and optimization strategies. Overall, our findings reveal a mismatch between academic focus, industry priorities, and model performance, highlighting the urgent need to integrate quality assurance mechanisms into LLM code generation pipelines to ensure that future generated code not only passes tests but truly passes with quality.
Cross-Layer Vision Smoothing: Enhancing Visual Understanding via Sustained Focus on Key Objects in Large Vision-Language Models
Sep 16, 2025Large Vision-Language Models (LVLMs) can accurately locate key objects in images, yet their attention to these objects tends to be very brief. Motivated by the hypothesis that sustained focus on key objects can improve LVLMs' visual capabilities, we propose Cross-Layer Vision Smoothing (CLVS). The core idea of CLVS is to incorporate a vision memory that smooths the attention distribution across layers. Specifically, we initialize this vision memory with position-unbiased visual attention in the first layer. In subsequent layers, the model's visual attention jointly considers the vision memory from previous layers, while the memory is updated iteratively, thereby maintaining smooth attention on key objects. Given that visual understanding primarily occurs in the early and middle layers of the model, we use uncertainty as an indicator of completed visual understanding and terminate the smoothing process accordingly. Experiments on four benchmarks across three LVLMs confirm the effectiveness and generalizability of our method. CLVS achieves state-of-the-art performance on a variety of visual understanding tasks, with particularly significant improvements in relation and attribute understanding.
Bootstrap Deep Spectral Clustering with Optimal Transport
Aug 06, 2025Spectral clustering is a leading clustering method. Two of its major shortcomings are the disjoint optimization process and the limited representation capacity. To address these issues, we propose a deep spectral clustering model (named BootSC), which jointly learns all stages of spectral clustering -- affinity matrix construction, spectral embedding, and $k$-means clustering -- using a single network in an end-to-end manner. BootSC leverages effective and efficient optimal-transport-derived supervision to bootstrap the affinity matrix and the cluster assignment matrix. Moreover, a semantically-consistent orthogonal re-parameterization technique is introduced to orthogonalize spectral embeddings, significantly enhancing the discrimination capability. Experimental results indicate that BootSC achieves state-of-the-art clustering performance. For example, it accomplishes a notable 16\% NMI improvement over the runner-up method on the challenging ImageNet-Dogs dataset. Our code is available at https://github.com/spdj2271/BootSC.
MultiJustice: A Chinese Dataset for Multi-Party, Multi-Charge Legal Prediction
Jul 09, 2025Legal judgment prediction offers a compelling method to aid legal practitioners and researchers. However, the research question remains relatively under-explored: Should multiple defendants and charges be treated separately in LJP? To address this, we introduce a new dataset namely multi-person multi-charge prediction (MPMCP), and seek the answer by evaluating the performance of several prevailing legal large language models (LLMs) on four practical legal judgment scenarios: (S1) single defendant with a single charge, (S2) single defendant with multiple charges, (S3) multiple defendants with a single charge, and (S4) multiple defendants with multiple charges. We evaluate the dataset across two LJP tasks, i.e., charge prediction and penalty term prediction. We have conducted extensive experiments and found that the scenario involving multiple defendants and multiple charges (S4) poses the greatest challenges, followed by S2, S3, and S1. The impact varies significantly depending on the model. For example, in S4 compared to S1, InternLM2 achieves approximately 4.5% lower F1-score and 2.8% higher LogD, while Lawformer demonstrates around 19.7% lower F1-score and 19.0% higher LogD. Our dataset and code are available at https://github.com/lololo-xiao/MultiJustice-MPMCP.