 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDV-SFT: Direct Vision Supervision for Fine-Grained Visual Understanding
May 26, 2026Multimodal large language models are typically trained end-to-end to predict ground-truth answers, yet supervision signals are applied exclusively to text tokens. Visual tokens, the core carriers of visual information, are optimized only implicitly as part of the context, leading to coarse-grained visual understanding. Prior works attempt to supervise visual inputs but inevitably rely on auxiliary components such as additional decoders or forward passes, because visual tokens lack readily interpretable labels. This limits their practical applicability. In this work, we propose \textbf{D}irect \textbf{V}ision \textbf{S}upervised \textbf{F}ine-\textbf{T}uning (DV-SFT), which constructs explicit, token-level supervision for visual tokens and trains them through the same next-token prediction objective used for text. Specifically, we exploit the direct vision--text correspondence in OCR-related scenarios and automatically label each visual token with the word in its corresponding image patch. DV-SFT treats the MLLM as a black box, requiring no architectural modifications or additional forward passes. Extensive experiments demonstrate the superiority of direct vision supervision. DV-SFT consistently outperforms standard SFT across three in-domain and four out-of-domain benchmarks. Further analyses show that vision supervision effectively enhances fine-grained visual understanding and achieves higher multimodal alignment efficiency.
Revisiting Reinforcement Learning with Verifiable Rewards from a Contrastive Perspective
May 13, 2026RLVR has become a widely adopted paradigm for improving LLMs' reasoning capabilities, and GRPO is one of its most representative algorithms. In this paper, we first show that GRPO admits an equivalent discriminative reformulation as a weighted positive-negative score difference. Under this view, GRPO increases sequence-level scores of verified positive rollouts and decreases those of negative rollouts, where the scores are averages of clipped token-level importance sampling ratios. This reformulation reveals two structural limitations of GRPO: likelihood-misaligned scoring, where clipped ratio-based surrogate scores are optimized instead of generation likelihoods, and score-insensitive credit assignment, where rollout-level credit is assigned without accounting for relative score gaps between positive and negative rollouts in the same group. To address these limitations, we propose ConSPO, a framework for Contrastive Sequence-level Policy Optimization in RLVR. ConSPO replaces GRPO's clipped ratio-based scores with length-normalized sequence log-probabilities, aligning the optimized rollout scores with the likelihoods used in autoregressive generation. It then optimizes a group-wise InfoNCE-style objective that contrasts each positive rollout against negative distractors from the same group, enabling credit assignment to depend on their relative scores. This contrastive formulation amplifies updates for poorly separated positives while concentrating suppressive updates on high-scoring negatives. Moreover, ConSPO introduces a curriculum-scheduled margin, guiding optimization from coarse positive-negative ordering in early training toward stronger separation in later stages. Extensive evaluations across diverse backbone models, parameter scales, and training datasets show that ConSPO consistently outperforms several strong RLVR baselines on challenging mathematical reasoning benchmarks.
ADHint: Adaptive Hints with Difficulty Priors for Reinforcement Learning
Dec 15, 2025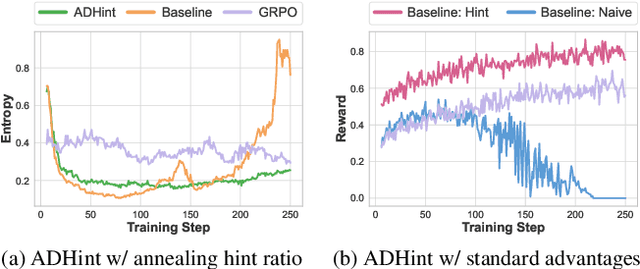
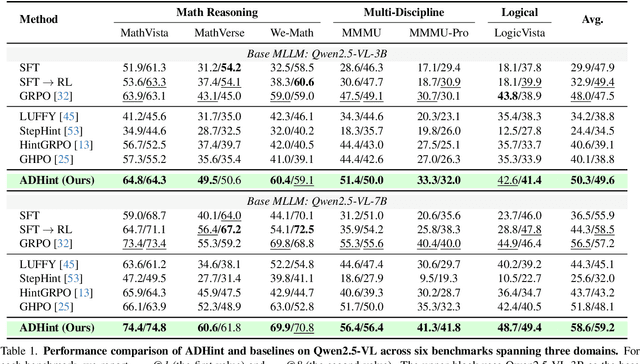
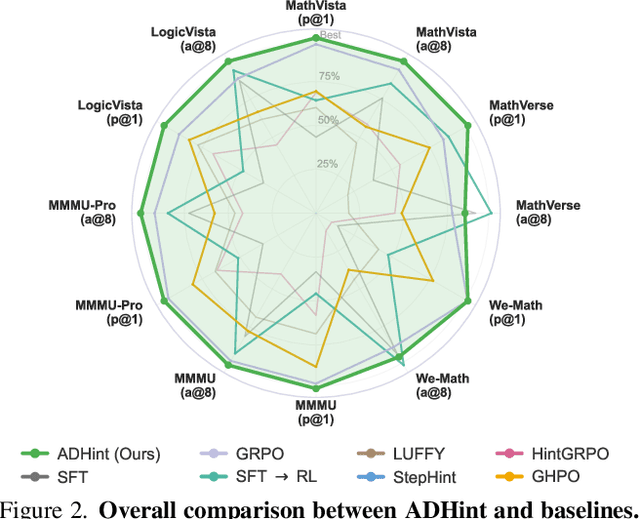
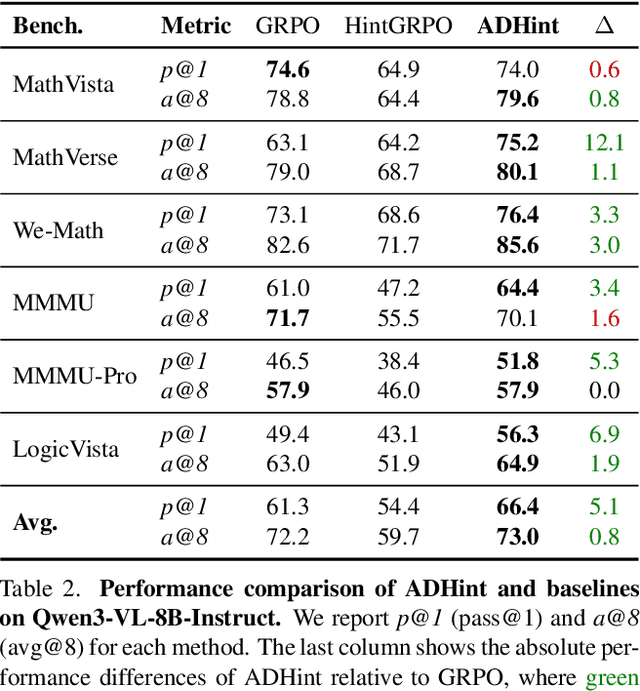
To combine the advantages of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), recent methods have integrated ''hints'' into post-training, which are prefix segments of complete reasoning trajectories, aiming for powerful knowledge expansion and reasoning generalization. However, existing hint-based RL methods typically ignore difficulty when scheduling hint ratios and estimating relative advantages, leading to unstable learning and excessive imitation of off-policy hints. In this work, we propose ADHint, which treats difficulty as a key factor in both hint-ratio schedule and relative-advantage estimation to achieve a better trade-off between exploration and imitation. Specifically, we propose Adaptive Hint with Sample Difficulty Prior, which evaluates each sample's difficulty under the policy model and accordingly schedules an appropriate hint ratio to guide its rollouts. We also introduce Consistency-based Gradient Modulation and Selective Masking for Hint Preservation to modulate token-level gradients within hints, preventing biased and destructive updates. Additionally, we propose Advantage Estimation with Rollout Difficulty Posterior, which leverages the relative difficulty of rollouts with and without hints to estimate their respective advantages, thereby achieving more balanced updates. Extensive experiments across diverse modalities, model scales, and domains demonstrate that ADHint delivers superior reasoning ability and out-of-distribution generalization, consistently surpassing existing methods in both pass@1 and avg@8. Our code and dataset will be made publicly available upon paper acceptance.
Cross-Layer Vision Smoothing: Enhancing Visual Understanding via Sustained Focus on Key Objects in Large Vision-Language Models
Sep 16, 2025Large Vision-Language Models (LVLMs) can accurately locate key objects in images, yet their attention to these objects tends to be very brief. Motivated by the hypothesis that sustained focus on key objects can improve LVLMs' visual capabilities, we propose Cross-Layer Vision Smoothing (CLVS). The core idea of CLVS is to incorporate a vision memory that smooths the attention distribution across layers. Specifically, we initialize this vision memory with position-unbiased visual attention in the first layer. In subsequent layers, the model's visual attention jointly considers the vision memory from previous layers, while the memory is updated iteratively, thereby maintaining smooth attention on key objects. Given that visual understanding primarily occurs in the early and middle layers of the model, we use uncertainty as an indicator of completed visual understanding and terminate the smoothing process accordingly. Experiments on four benchmarks across three LVLMs confirm the effectiveness and generalizability of our method. CLVS achieves state-of-the-art performance on a variety of visual understanding tasks, with particularly significant improvements in relation and attribute understanding.
Aligning Attention Distribution to Information Flow for Hallucination Mitigation in Large Vision-Language Models
May 20, 2025



Due to the unidirectional masking mechanism, Decoder-Only models propagate information from left to right. LVLMs (Large Vision-Language Models) follow the same architecture, with visual information gradually integrated into semantic representations during forward propagation. Through systematic analysis, we observe that over 80\% of the visual information is absorbed into the semantic representations. However, the model's attention still predominantly focuses on the visual representations. This misalignment between the attention distribution and the actual information flow undermines the model's visual understanding ability and contributes to hallucinations. To address this issue, we enhance the model's visual understanding by leveraging the core information embedded in semantic representations. Specifically, we identify attention heads that focus on core semantic representations based on their attention distributions. Then, through a two-stage optimization paradigm, we propagate the advantages of these attention heads across the entire model, aligning the attention distribution with the actual information flow. We evaluate our method on three image captioning benchmarks using five different LVLMs, demonstrating its effectiveness in significantly reducing hallucinations. Further experiments reveal a trade-off between reduced hallucinations and richer details. Notably, our method allows for manual adjustment of the model's conservativeness, enabling flexible control to meet diverse real-world requirements. Code will be released once accepted.
Mitigate Language Priors in Large Vision-Language Models by Cross-Images Contrastive Decoding
May 19, 2025Language priors are a major cause of hallucinations in Large Vision-Language Models (LVLMs), often leading to text that is linguistically plausible but visually inconsistent. Recent work explores contrastive decoding as a training-free solution, but these methods typically construct negative visual contexts from the original image, resulting in visual information loss and distorted distribution. Motivated by the observation that language priors stem from the LLM backbone and remain consistent across images, we propose Cross-Images Contrastive Decoding (CICD), a simple yet effective training-free method that uses different images to construct negative visual contexts. We further analyze the cross-image behavior of language priors and introduce a distinction between essential priors (supporting fluency) and detrimental priors (causing hallucinations), enabling selective suppression. By selectively preserving essential priors and suppressing detrimental ones, our method reduces hallucinations while maintaining coherent and fluent language generation. Experiments on four benchmarks and six LVLMs across three model families confirm the effectiveness and generalizability of CICD, especially in image captioning, where language priors are particularly pronounced. Code will be released upon acceptance.
Opening the black box of deep learning
May 22, 2018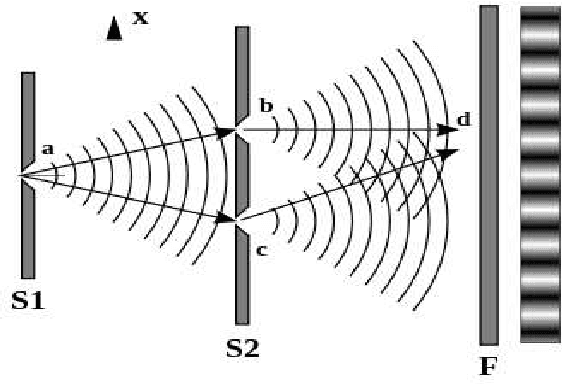
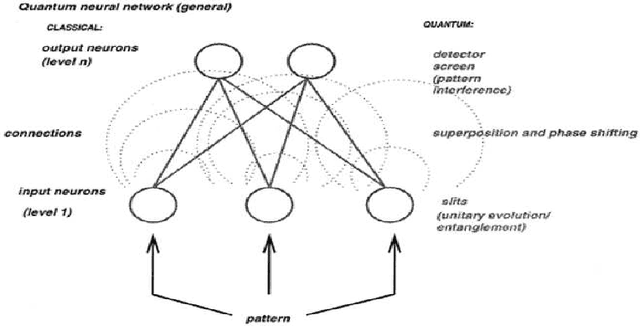

The great success of deep learning shows that its technology contains profound truth, and understanding its internal mechanism not only has important implications for the development of its technology and effective application in various fields, but also provides meaningful insights into the understanding of human brain mechanism. At present, most of the theoretical research on deep learning is based on mathematics. This dissertation proposes that the neural network of deep learning is a physical system, examines deep learning from three different perspectives: microscopic, macroscopic, and physical world views, answers multiple theoretical puzzles in deep learning by using physics principles. For example, from the perspective of quantum mechanics and statistical physics, this dissertation presents the calculation methods for convolution calculation, pooling, normalization, and Restricted Boltzmann Machine, as well as the selection of cost functions, explains why deep learning must be deep, what characteristics are learned in deep learning, why Convolutional Neural Networks do not have to be trained layer by layer, and the limitations of deep learning, etc., and proposes the theoretical direction and basis for the further development of deep learning now and in the future. The brilliance of physics flashes in deep learning, we try to establish the deep learning technology based on the scientific theory of physics.