 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAVE: Re-Allocating Visual Attention in Large Multimodal Models
May 18, 2026Large multimodal models (LMMs) inherit the self-attention mechanism of pretrained language backbones, yet standard attention can exhibit suboptimal allocation, including cross-modal misallocation between textual and visual evidence and intra-visual imbalance among visual tokens. We propose RAVE (Re-Allocating Visual Attention), a lightweight pair-gating mechanism that adds a learned query--key bias to pre-softmax attention scores over visual keys, derived from pre-RoPE query and key features. RAVE requires no architectural modification to the backbone and can be trained end-to-end with the rest of the model. Across a suite of multimodal benchmarks, RAVE improves over standard attention by an average of 3 points, with the largest gains on perception-intensive tasks -- including multilingual OCR, chart understanding, document VQA, and scene text VQA -- where accurate visual grounding is critical.
Revisiting Reinforcement Learning with Verifiable Rewards from a Contrastive Perspective
May 13, 2026RLVR has become a widely adopted paradigm for improving LLMs' reasoning capabilities, and GRPO is one of its most representative algorithms. In this paper, we first show that GRPO admits an equivalent discriminative reformulation as a weighted positive-negative score difference. Under this view, GRPO increases sequence-level scores of verified positive rollouts and decreases those of negative rollouts, where the scores are averages of clipped token-level importance sampling ratios. This reformulation reveals two structural limitations of GRPO: likelihood-misaligned scoring, where clipped ratio-based surrogate scores are optimized instead of generation likelihoods, and score-insensitive credit assignment, where rollout-level credit is assigned without accounting for relative score gaps between positive and negative rollouts in the same group. To address these limitations, we propose ConSPO, a framework for Contrastive Sequence-level Policy Optimization in RLVR. ConSPO replaces GRPO's clipped ratio-based scores with length-normalized sequence log-probabilities, aligning the optimized rollout scores with the likelihoods used in autoregressive generation. It then optimizes a group-wise InfoNCE-style objective that contrasts each positive rollout against negative distractors from the same group, enabling credit assignment to depend on their relative scores. This contrastive formulation amplifies updates for poorly separated positives while concentrating suppressive updates on high-scoring negatives. Moreover, ConSPO introduces a curriculum-scheduled margin, guiding optimization from coarse positive-negative ordering in early training toward stronger separation in later stages. Extensive evaluations across diverse backbone models, parameter scales, and training datasets show that ConSPO consistently outperforms several strong RLVR baselines on challenging mathematical reasoning benchmarks.
ADHint: Adaptive Hints with Difficulty Priors for Reinforcement Learning
Dec 15, 2025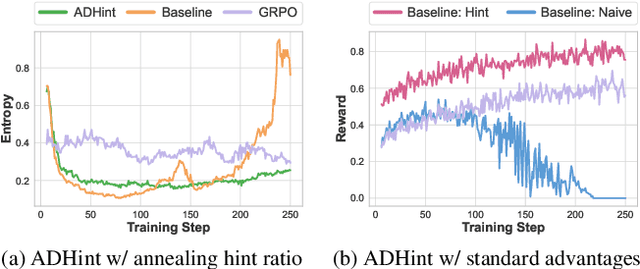
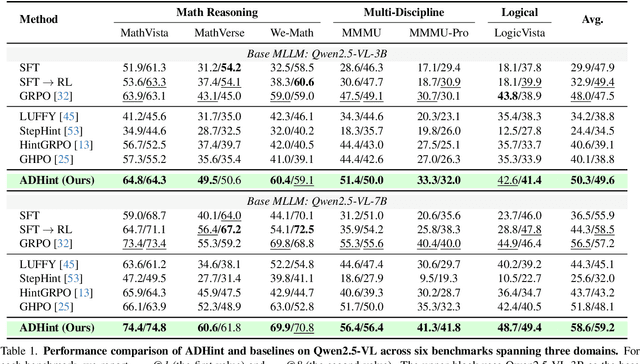
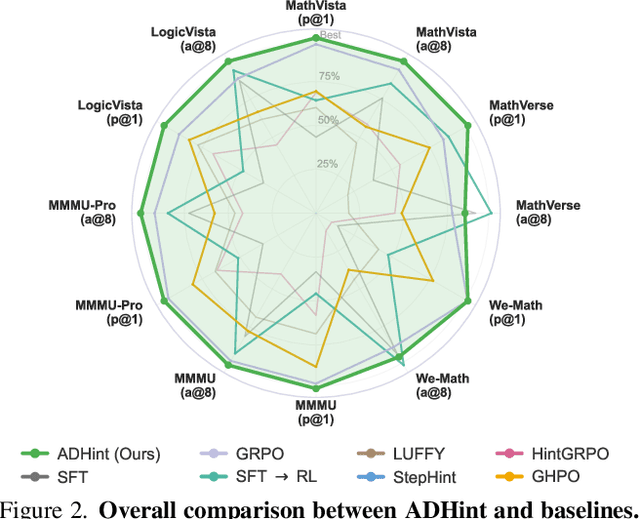
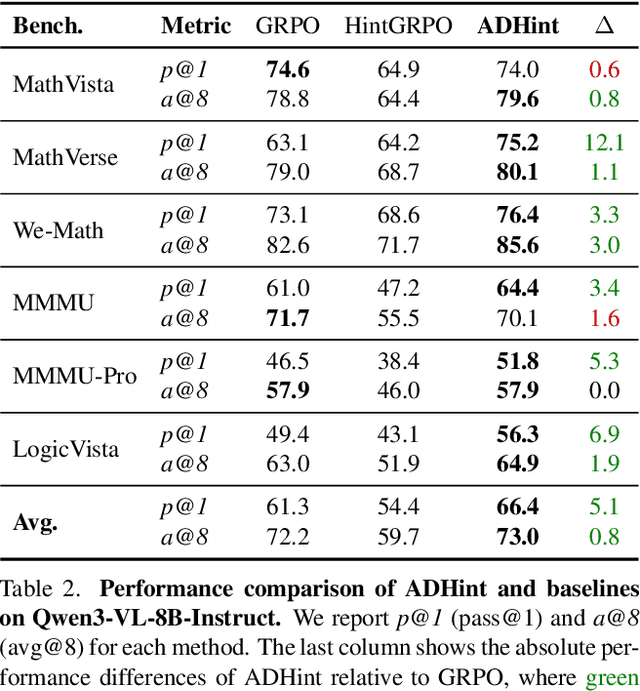
To combine the advantages of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), recent methods have integrated ''hints'' into post-training, which are prefix segments of complete reasoning trajectories, aiming for powerful knowledge expansion and reasoning generalization. However, existing hint-based RL methods typically ignore difficulty when scheduling hint ratios and estimating relative advantages, leading to unstable learning and excessive imitation of off-policy hints. In this work, we propose ADHint, which treats difficulty as a key factor in both hint-ratio schedule and relative-advantage estimation to achieve a better trade-off between exploration and imitation. Specifically, we propose Adaptive Hint with Sample Difficulty Prior, which evaluates each sample's difficulty under the policy model and accordingly schedules an appropriate hint ratio to guide its rollouts. We also introduce Consistency-based Gradient Modulation and Selective Masking for Hint Preservation to modulate token-level gradients within hints, preventing biased and destructive updates. Additionally, we propose Advantage Estimation with Rollout Difficulty Posterior, which leverages the relative difficulty of rollouts with and without hints to estimate their respective advantages, thereby achieving more balanced updates. Extensive experiments across diverse modalities, model scales, and domains demonstrate that ADHint delivers superior reasoning ability and out-of-distribution generalization, consistently surpassing existing methods in both pass@1 and avg@8. Our code and dataset will be made publicly available upon paper acceptance.
FedRec+: Enhancing Privacy and Addressing Heterogeneity in Federated Recommendation Systems
Oct 31, 2023Preserving privacy and reducing communication costs for edge users pose significant challenges in recommendation systems. Although federated learning has proven effective in protecting privacy by avoiding data exchange between clients and servers, it has been shown that the server can infer user ratings based on updated non-zero gradients obtained from two consecutive rounds of user-uploaded gradients. Moreover, federated recommendation systems (FRS) face the challenge of heterogeneity, leading to decreased recommendation performance. In this paper, we propose FedRec+, an ensemble framework for FRS that enhances privacy while addressing the heterogeneity challenge. FedRec+ employs optimal subset selection based on feature similarity to generate near-optimal virtual ratings for pseudo items, utilizing only the user's local information. This approach reduces noise without incurring additional communication costs. Furthermore, we utilize the Wasserstein distance to estimate the heterogeneity and contribution of each client, and derive optimal aggregation weights by solving a defined optimization problem. Experimental results demonstrate the state-of-the-art performance of FedRec+ across various reference datasets.
Diversity Boosted Learning for Domain Generalization with Large Number of Domains
Jul 28, 2022

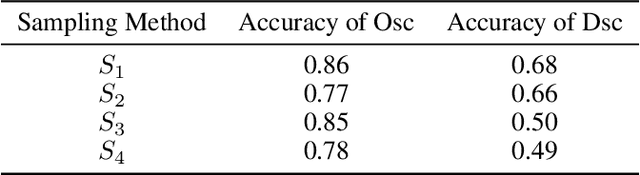
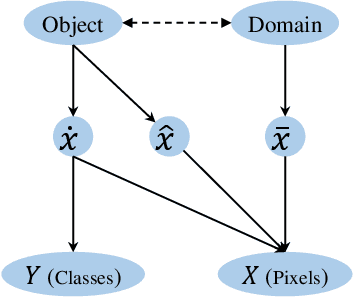
Machine learning algorithms minimizing the average training loss usually suffer from poor generalization performance due to the greedy exploitation of correlations among the training data, which are not stable under distributional shifts. It inspires various works for domain generalization (DG), where a series of methods, such as Causal Matching and FISH, work by pairwise domain operations. They would need $O(n^2)$ pairwise domain operations with $n$ domains, where each one is often highly expensive. Moreover, while a common objective in the DG literature is to learn invariant representations against domain-induced spurious correlations, we highlight the importance of mitigating spurious correlations caused by objects. Based on the observation that diversity helps mitigate spurious correlations, we propose a Diversity boosted twO-level saMplIng framework (DOMI) utilizing Determinantal Point Processes (DPPs) to efficiently sample the most informative ones among large number of domains. We show that DOMI helps train robust models against spurious correlations from both domain-side and object-side, substantially enhancing the performance of the backbone DG algorithms on rotated MNIST, rotated Fashion MNIST, and iwildcam datasets.