 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Instance Shadow Detection
Nov 23, 2022



Video instance shadow detection aims to simultaneously detect, segment, associate, and track paired shadow-object associations in videos. This work has three key contributions to the task. First, we design SSIS-Track, a new framework to extract shadow-object associations in videos with paired tracking and without category specification; especially, we strive to maintain paired tracking even the objects/shadows are temporarily occluded for several frames. Second, we leverage both labeled images and unlabeled videos, and explore temporal coherence by augmenting the tracking ability via an association cycle consistency loss to optimize SSIS-Track's performance. Last, we build $\textit{SOBA-VID}$, a new dataset with 232 unlabeled videos of ${5,863}$ frames for training and 60 labeled videos of ${1,182}$ frames for testing. Experimental results show that SSIS-Track surpasses baselines built from SOTA video tracking and instance-shadow-detection methods by a large margin. In the end, we showcase several video-level applications.
Sparse2Dense: Learning to Densify 3D Features for 3D Object Detection
Nov 23, 2022



LiDAR-produced point clouds are the major source for most state-of-the-art 3D object detectors. Yet, small, distant, and incomplete objects with sparse or few points are often hard to detect. We present Sparse2Dense, a new framework to efficiently boost 3D detection performance by learning to densify point clouds in latent space. Specifically, we first train a dense point 3D detector (DDet) with a dense point cloud as input and design a sparse point 3D detector (SDet) with a regular point cloud as input. Importantly, we formulate the lightweight plug-in S2D module and the point cloud reconstruction module in SDet to densify 3D features and train SDet to produce 3D features, following the dense 3D features in DDet. So, in inference, SDet can simulate dense 3D features from regular (sparse) point cloud inputs without requiring dense inputs. We evaluate our method on the large-scale Waymo Open Dataset and the Waymo Domain Adaptation Dataset, showing its high performance and efficiency over the state of the arts.
InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions
Nov 13, 2022



Compared to the great progress of large-scale vision transformers (ViTs) in recent years, large-scale models based on convolutional neural networks (CNNs) are still in an early state. This work presents a new large-scale CNN-based foundation model, termed InternImage, which can obtain the gain from increasing parameters and training data like ViTs. Different from the recent CNNs that focus on large dense kernels, InternImage takes deformable convolution as the core operator, so that our model not only has the large effective receptive field required for downstream tasks such as detection and segmentation, but also has the adaptive spatial aggregation conditioned by input and task information. As a result, the proposed InternImage reduces the strict inductive bias of traditional CNNs and makes it possible to learn stronger and more robust patterns with large-scale parameters from massive data like ViTs. The effectiveness of our model is proven on challenging benchmarks including ImageNet, COCO, and ADE20K. It is worth mentioning that InternImage-H achieved a new record 65.4 mAP on COCO test-dev and 62.9 mIoU on ADE20K, outperforming current leading CNNs and ViTs. The code will be released at https://github.com/OpenGVLab/InternImage.
Demystify Transformers & Convolutions in Modern Image Deep Networks
Nov 10, 2022



Recent success of vision transformers has inspired a series of vision backbones with novel feature transformation paradigms, which report steady performance gain. Although the novel feature transformation designs are often claimed as the source of gain, some backbones may benefit from advanced engineering techniques, which makes it hard to identify the real gain from the key feature transformation operators. In this paper, we aim to identify real gain of popular convolution and attention operators and make an in-depth study of them. We observe that the main difference among these feature transformation modules, e.g., attention or convolution, lies in the way of spatial feature aggregation, or the so-called "spatial token mixer" (STM). Hence, we first elaborate a unified architecture to eliminate the unfair impact of different engineering techniques, and then fit STMs into this architecture for comparison. Based on various experiments on upstream/downstream tasks and the analysis of inductive bias, we find that the engineering techniques boost the performance significantly, but the performance gap still exists among different STMs. The detailed analysis also reveals some interesting findings of different STMs, such as effective receptive fields and invariance tests. The code and trained models will be publicly available at https://github.com/OpenGVLab/STM-Evaluation
Learning Shadow Correspondence for Video Shadow Detection
Jul 30, 2022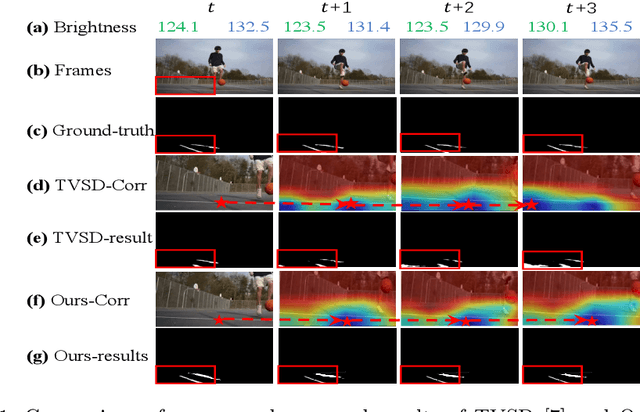
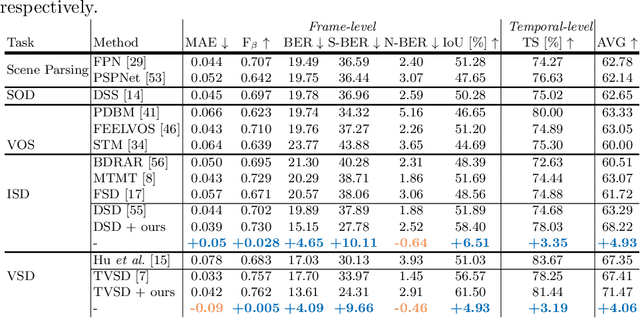

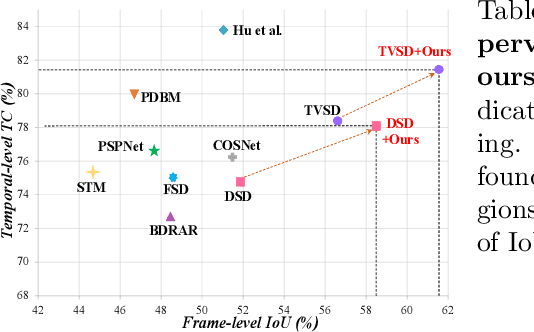
Video shadow detection aims to generate consistent shadow predictions among video frames. However, the current approaches suffer from inconsistent shadow predictions across frames, especially when the illumination and background textures change in a video. We make an observation that the inconsistent predictions are caused by the shadow feature inconsistency, i.e., the features of the same shadow regions show dissimilar proprieties among the nearby frames.In this paper, we present a novel Shadow-Consistent Correspondence method (SC-Cor) to enhance pixel-wise similarity of the specific shadow regions across frames for video shadow detection. Our proposed SC-Cor has three main advantages. Firstly, without requiring the dense pixel-to-pixel correspondence labels, SC-Cor can learn the pixel-wise correspondence across frames in a weakly-supervised manner. Secondly, SC-Cor considers intra-shadow separability, which is robust to the variant textures and illuminations in videos. Finally, SC-Cor is a plug-and-play module that can be easily integrated into existing shadow detectors with no extra computational cost. We further design a new evaluation metric to evaluate the temporal stability of the video shadow detection results. Experimental results show that SC-Cor outperforms the prior state-of-the-art method, by 6.51% on IoU and 3.35% on the newly introduced temporal stability metric.
NUWA-Infinity: Autoregressive over Autoregressive Generation for Infinite Visual Synthesis
Jul 20, 2022
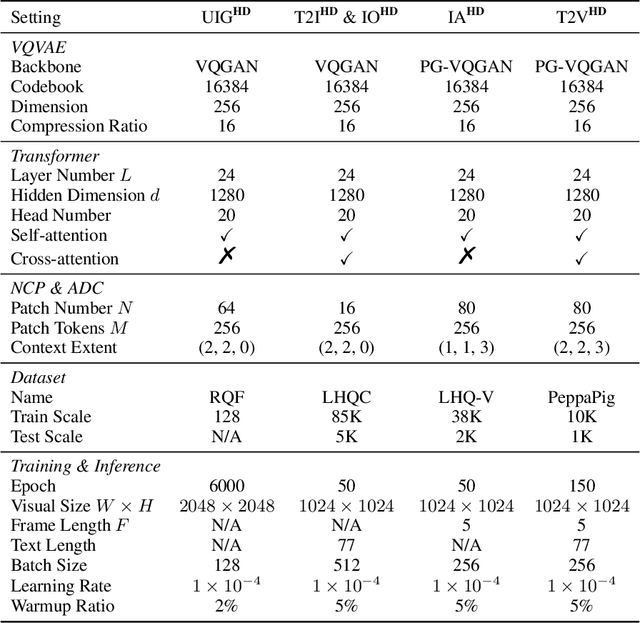


In this paper, we present NUWA-Infinity, a generative model for infinite visual synthesis, which is defined as the task of generating arbitrarily-sized high-resolution images or long-duration videos. An autoregressive over autoregressive generation mechanism is proposed to deal with this variable-size generation task, where a global patch-level autoregressive model considers the dependencies between patches, and a local token-level autoregressive model considers dependencies between visual tokens within each patch. A Nearby Context Pool (NCP) is introduced to cache-related patches already generated as the context for the current patch being generated, which can significantly save computation costs without sacrificing patch-level dependency modeling. An Arbitrary Direction Controller (ADC) is used to decide suitable generation orders for different visual synthesis tasks and learn order-aware positional embeddings. Compared to DALL-E, Imagen and Parti, NUWA-Infinity can generate high-resolution images with arbitrary sizes and support long-duration video generation additionally. Compared to NUWA, which also covers images and videos, NUWA-Infinity has superior visual synthesis capabilities in terms of resolution and variable-size generation. The GitHub link is https://github.com/microsoft/NUWA. The homepage link is https://nuwa-infinity.microsoft.com.
Instance Shadow Detection with A Single-Stage Detector
Jul 11, 2022



This paper formulates a new problem, instance shadow detection, which aims to detect shadow instance and the associated object instance that cast each shadow in the input image. To approach this task, we first compile a new dataset with the masks for shadow instances, object instances, and shadow-object associations. We then design an evaluation metric for quantitative evaluation of the performance of instance shadow detection. Further, we design a single-stage detector to perform instance shadow detection in an end-to-end manner, where the bidirectional relation learning module and the deformable maskIoU head are proposed in the detector to directly learn the relation between shadow instances and object instances and to improve the accuracy of the predicted masks. Finally, we quantitatively and qualitatively evaluate our method on the benchmark dataset of instance shadow detection and show the applicability of our method on light direction estimation and photo editing.
Dynamic Message Propagation Network for RGB-D Salient Object Detection
Jun 20, 2022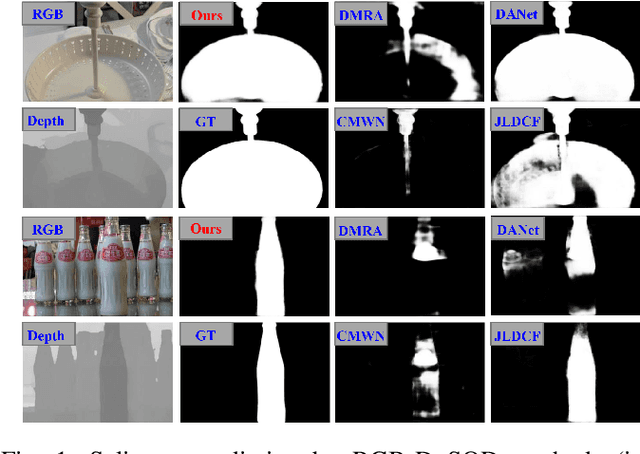
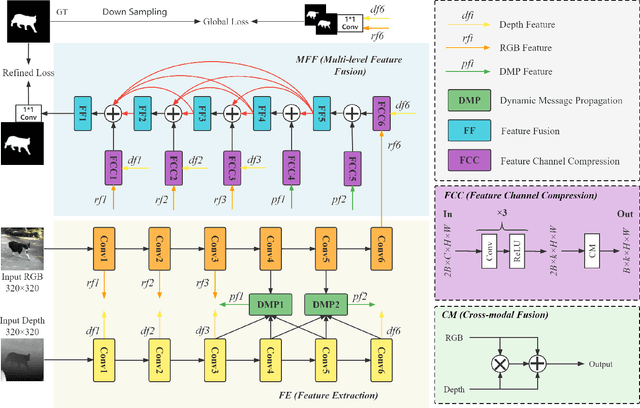
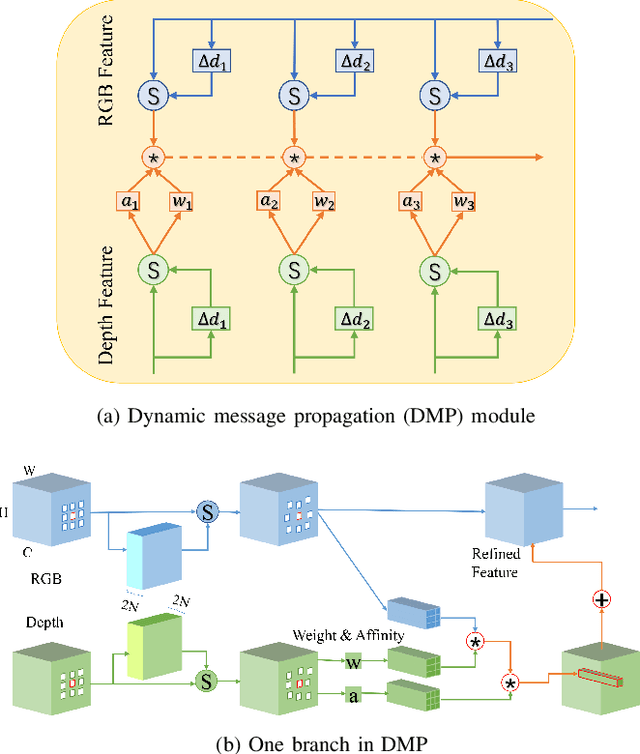
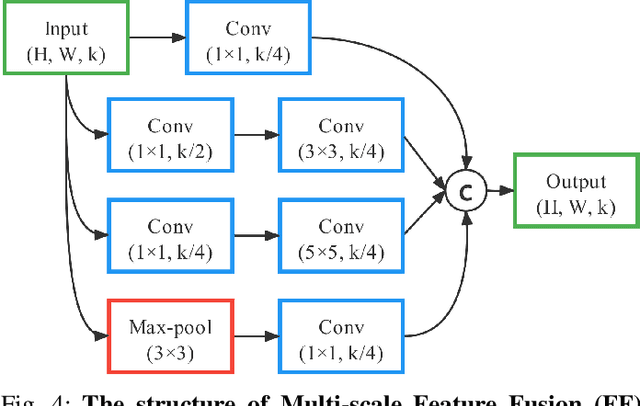
This paper presents a novel deep neural network framework for RGB-D salient object detection by controlling the message passing between the RGB images and depth maps on the feature level and exploring the long-range semantic contexts and geometric information on both RGB and depth features to infer salient objects. To achieve this, we formulate a dynamic message propagation (DMP) module with the graph neural networks and deformable convolutions to dynamically learn the context information and to automatically predict filter weights and affinity matrices for message propagation control. We further embed this module into a Siamese-based network to process the RGB image and depth map respectively and design a multi-level feature fusion (MFF) module to explore the cross-level information between the refined RGB and depth features. Compared with 17 state-of-the-art methods on six benchmark datasets for RGB-D salient object detection, experimental results show that our method outperforms all the others, both quantitatively and visually.
GLIPv2: Unifying Localization and Vision-Language Understanding
Jun 12, 2022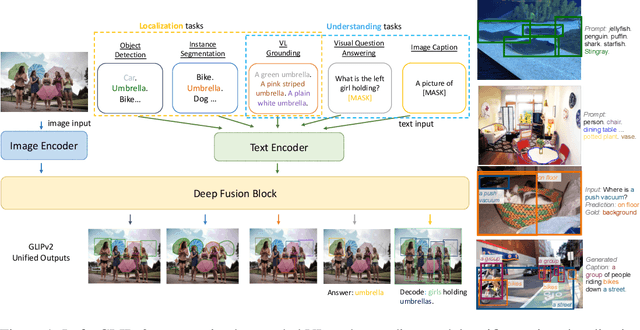
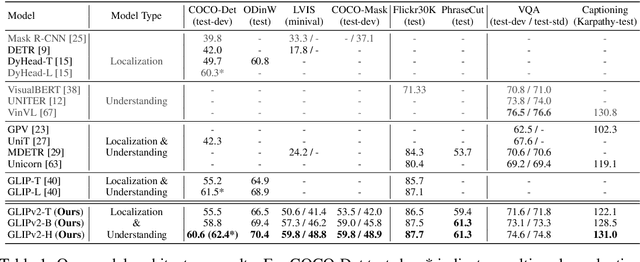
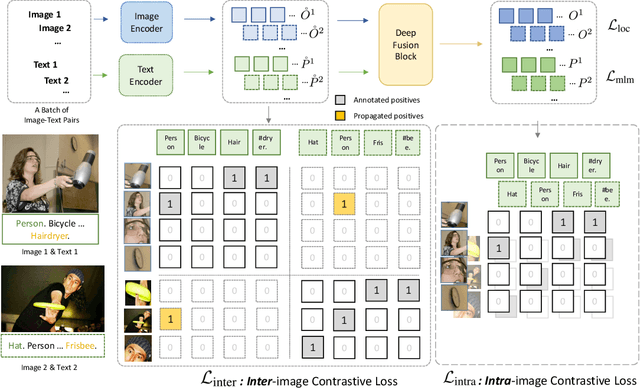
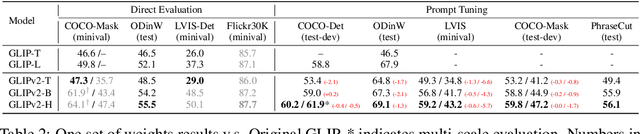
We present GLIPv2, a grounded VL understanding model, that serves both localization tasks (e.g., object detection, instance segmentation) and Vision-Language (VL) understanding tasks (e.g., VQA, image captioning). GLIPv2 elegantly unifies localization pre-training and Vision-Language Pre-training (VLP) with three pre-training tasks: phrase grounding as a VL reformulation of the detection task, region-word contrastive learning as a novel region-word level contrastive learning task, and the masked language modeling. This unification not only simplifies the previous multi-stage VLP procedure but also achieves mutual benefits between localization and understanding tasks. Experimental results show that a single GLIPv2 model (all model weights are shared) achieves near SoTA performance on various localization and understanding tasks. The model also shows (1) strong zero-shot and few-shot adaption performance on open-vocabulary object detection tasks and (2) superior grounding capability on VL understanding tasks. Code will be released at https://github.com/microsoft/GLIP.
GIT: A Generative Image-to-text Transformer for Vision and Language
May 31, 2022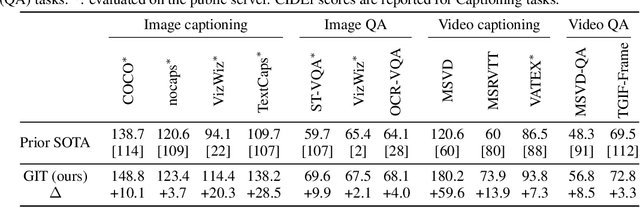

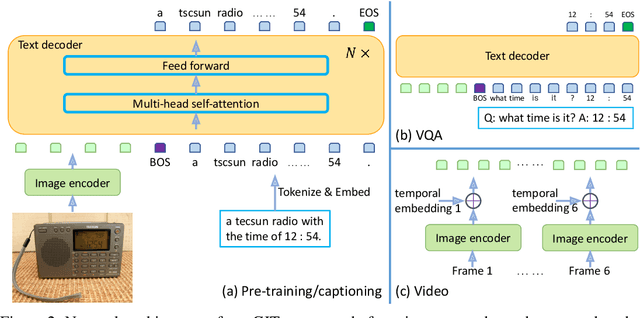
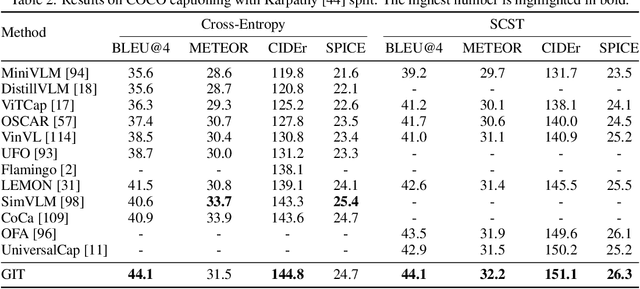
In this paper, we design and train a Generative Image-to-text Transformer, GIT, to unify vision-language tasks such as image/video captioning and question answering. While generative models provide a consistent network architecture between pre-training and fine-tuning, existing work typically contains complex structures (uni/multi-modal encoder/decoder) and depends on external modules such as object detectors/taggers and optical character recognition (OCR). In GIT, we simplify the architecture as one image encoder and one text decoder under a single language modeling task. We also scale up the pre-training data and the model size to boost the model performance. Without bells and whistles, our GIT establishes new state of the arts on 12 challenging benchmarks with a large margin. For instance, our model surpasses the human performance for the first time on TextCaps (138.2 vs. 125.5 in CIDEr). Furthermore, we present a new scheme of generation-based image classification and scene text recognition, achieving decent performance on standard benchmarks.