 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatryoshka Query Transformer for Large Vision-Language Models
May 29, 2024Large Vision-Language Models (LVLMs) typically encode an image into a fixed number of visual tokens (e.g., 576) and process these tokens with a language model. Despite their strong performance, LVLMs face challenges in adapting to varying computational constraints. This raises the question: can we achieve flexibility in the number of visual tokens to suit different tasks and computational resources? We answer this with an emphatic yes. Inspired by Matryoshka Representation Learning, we introduce the Matryoshka Query Transformer (MQT), capable of encoding an image into m visual tokens during inference, where m can be any number up to a predefined maximum. This is achieved by employing a query transformer with M latent query tokens to compress the visual embeddings. During each training step, we randomly select m <= M latent query tokens and train the model using only these first m tokens, discarding the rest. Combining MQT with LLaVA, we train a single model once, and flexibly and drastically reduce the number of inference-time visual tokens while maintaining similar or better performance compared to training independent models for each number of tokens. Our model, MQT-LLAVA, matches LLaVA-1.5 performance across 11 benchmarks using a maximum of 256 tokens instead of LLaVA's fixed 576. Reducing to 16 tokens (8x less TFLOPs) only sacrifices the performance by 2.4 points on MMBench. On certain tasks such as ScienceQA and MMMU, we can even go down to only 2 visual tokens with performance drops of just 3% and 6% each. Our exploration of the trade-off between the accuracy and computational cost brought about by the number of visual tokens facilitates future research to achieve the best of both worlds.
Tailoring Self-Rationalizers with Multi-Reward Distillation
Nov 06, 2023Large language models (LMs) are capable of generating free-text rationales to aid question answering. However, prior work 1) suggests that useful self-rationalization is emergent only at significant scales (e.g., 175B parameter GPT-3); and 2) focuses largely on downstream performance, ignoring the semantics of the rationales themselves, e.g., are they faithful, true, and helpful for humans? In this work, we enable small-scale LMs (approx. 200x smaller than GPT-3) to generate rationales that not only improve downstream task performance, but are also more plausible, consistent, and diverse, assessed both by automatic and human evaluation. Our method, MaRio (Multi-rewArd RatIOnalization), is a multi-reward conditioned self-rationalization algorithm that optimizes multiple distinct properties like plausibility, diversity and consistency. Results on five difficult question-answering datasets StrategyQA, QuaRel, OpenBookQA, NumerSense and QASC show that not only does MaRio improve task accuracy, but it also improves the self-rationalization quality of small LMs across the aforementioned axes better than a supervised fine-tuning (SFT) baseline. Extensive human evaluations confirm that MaRio rationales are preferred vs. SFT rationales, as well as qualitative improvements in plausibility and consistency.
DesCo: Learning Object Recognition with Rich Language Descriptions
Jun 24, 2023



Recent development in vision-language approaches has instigated a paradigm shift in learning visual recognition models from language supervision. These approaches align objects with language queries (e.g. "a photo of a cat") and improve the models' adaptability to identify novel objects and domains. Recently, several studies have attempted to query these models with complex language expressions that include specifications of fine-grained semantic details, such as attributes, shapes, textures, and relations. However, simply incorporating language descriptions as queries does not guarantee accurate interpretation by the models. In fact, our experiments show that GLIP, the state-of-the-art vision-language model for object detection, often disregards contextual information in the language descriptions and instead relies heavily on detecting objects solely by their names. To tackle the challenges, we propose a new description-conditioned (DesCo) paradigm of learning object recognition models with rich language descriptions consisting of two major innovations: 1) we employ a large language model as a commonsense knowledge engine to generate rich language descriptions of objects based on object names and the raw image-text caption; 2) we design context-sensitive queries to improve the model's ability in deciphering intricate nuances embedded within descriptions and enforce the model to focus on context rather than object names alone. On two novel object detection benchmarks, LVIS and OminiLabel, under the zero-shot detection setting, our approach achieves 34.8 APr minival (+9.1) and 29.3 AP (+3.6), respectively, surpassing the prior state-of-the-art models, GLIP and FIBER, by a large margin.
Symbolic Chain-of-Thought Distillation: Small Models Can Also "Think" Step-by-Step
Jun 24, 2023



Chain-of-thought prompting (e.g., "Let's think step-by-step") primes large language models to verbalize rationalization for their predictions. While chain-of-thought can lead to dramatic performance gains, benefits appear to emerge only for sufficiently large models (beyond 50B parameters). We show that orders-of-magnitude smaller models (125M -- 1.3B parameters) can still benefit from chain-of-thought prompting. To achieve this, we introduce Symbolic Chain-of-Thought Distillation (SCoTD), a method to train a smaller student model on rationalizations sampled from a significantly larger teacher model. Experiments across several commonsense benchmarks show that: 1) SCoTD enhances the performance of the student model in both supervised and few-shot settings, and especially for challenge sets; 2) sampling many reasoning chains per instance from the teacher is paramount; and 3) after distillation, student chain-of-thoughts are judged by humans as comparable to the teacher, despite orders of magnitude fewer parameters. We test several hypotheses regarding what properties of chain-of-thought samples are important, e.g., diversity vs. teacher likelihood vs. open-endedness. We release our corpus of chain-of-thought samples and code.
MetaVL: Transferring In-Context Learning Ability From Language Models to Vision-Language Models
Jun 02, 2023



Large-scale language models have shown the ability to adapt to a new task via conditioning on a few demonstrations (i.e., in-context learning). However, in the vision-language domain, most large-scale pre-trained vision-language (VL) models do not possess the ability to conduct in-context learning. How can we enable in-context learning for VL models? In this paper, we study an interesting hypothesis: can we transfer the in-context learning ability from the language domain to VL domain? Specifically, we first meta-trains a language model to perform in-context learning on NLP tasks (as in MetaICL); then we transfer this model to perform VL tasks by attaching a visual encoder. Our experiments suggest that indeed in-context learning ability can be transferred cross modalities: our model considerably improves the in-context learning capability on VL tasks and can even compensate for the size of the model significantly. On VQA, OK-VQA, and GQA, our method could outperform the baseline model while having 20 times fewer parameters.
GLIPv2: Unifying Localization and Vision-Language Understanding
Jun 12, 2022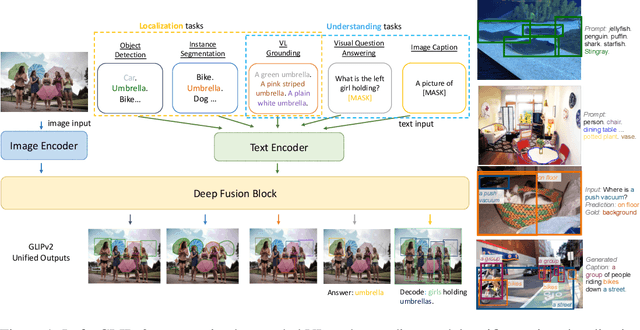
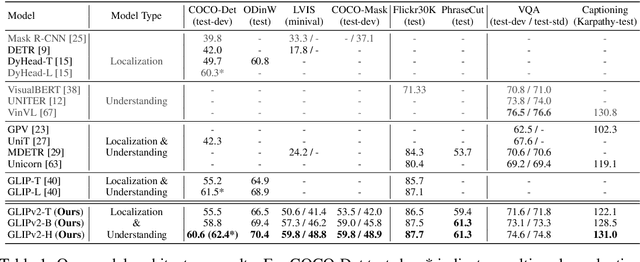
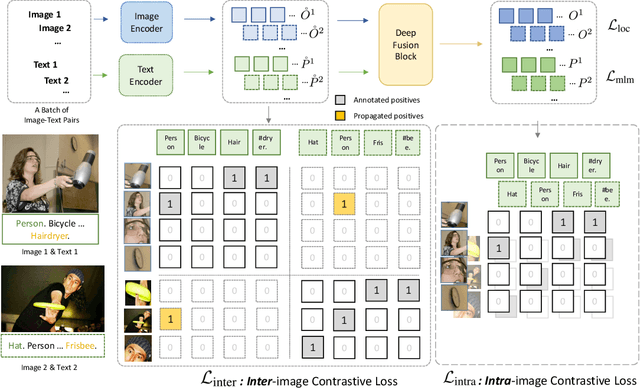
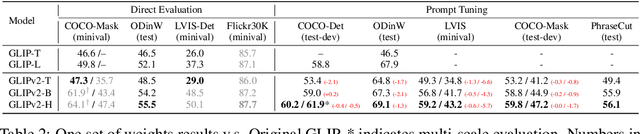
We present GLIPv2, a grounded VL understanding model, that serves both localization tasks (e.g., object detection, instance segmentation) and Vision-Language (VL) understanding tasks (e.g., VQA, image captioning). GLIPv2 elegantly unifies localization pre-training and Vision-Language Pre-training (VLP) with three pre-training tasks: phrase grounding as a VL reformulation of the detection task, region-word contrastive learning as a novel region-word level contrastive learning task, and the masked language modeling. This unification not only simplifies the previous multi-stage VLP procedure but also achieves mutual benefits between localization and understanding tasks. Experimental results show that a single GLIPv2 model (all model weights are shared) achieves near SoTA performance on various localization and understanding tasks. The model also shows (1) strong zero-shot and few-shot adaption performance on open-vocabulary object detection tasks and (2) superior grounding capability on VL understanding tasks. Code will be released at https://github.com/microsoft/GLIP.
DisinfoMeme: A Multimodal Dataset for Detecting Meme Intentionally Spreading Out Disinformation
May 25, 2022
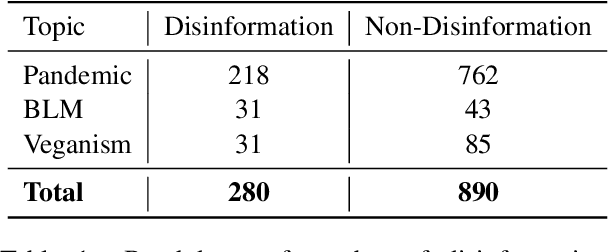

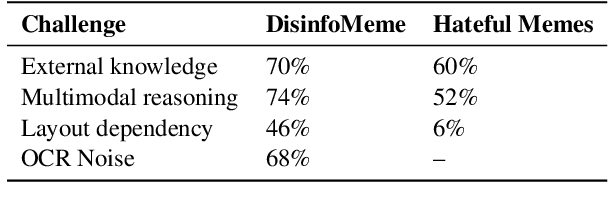
Disinformation has become a serious problem on social media. In particular, given their short format, visual attraction, and humorous nature, memes have a significant advantage in dissemination among online communities, making them an effective vehicle for the spread of disinformation. We present DisinfoMeme to help detect disinformation memes. The dataset contains memes mined from Reddit covering three current topics: the COVID-19 pandemic, the Black Lives Matter movement, and veganism/vegetarianism. The dataset poses multiple unique challenges: limited data and label imbalance, reliance on external knowledge, multimodal reasoning, layout dependency, and noise from OCR. We test multiple widely-used unimodal and multimodal models on this dataset. The experiments show that the room for improvement is still huge for current models.
On the Paradox of Learning to Reason from Data
May 24, 2022
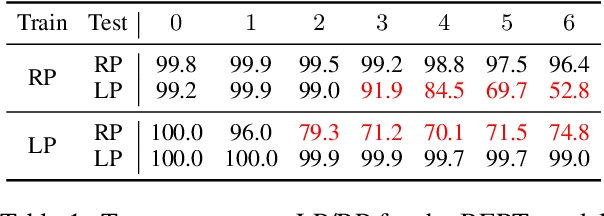
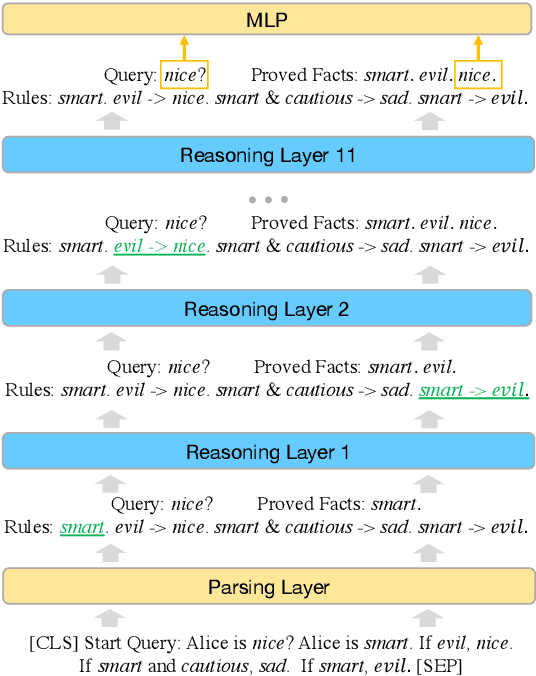

Logical reasoning is needed in a wide range of NLP tasks. Can a BERT model be trained end-to-end to solve logical reasoning problems presented in natural language? We attempt to answer this question in a confined problem space where there exists a set of parameters that perfectly simulates logical reasoning. We make observations that seem to contradict each other: BERT attains near-perfect accuracy on in-distribution test examples while failing to generalize to other data distributions over the exact same problem space. Our study provides an explanation for this paradox: instead of learning to emulate the correct reasoning function, BERT has in fact learned statistical features that inherently exist in logical reasoning problems. We also show that it is infeasible to jointly remove statistical features from data, illustrating the difficulty of learning to reason in general. Our result naturally extends to other neural models and unveils the fundamental difference between learning to reason and learning to achieve high performance on NLP benchmarks using statistical features.
GeoMLAMA: Geo-Diverse Commonsense Probing on Multilingual Pre-Trained Language Models
May 24, 2022
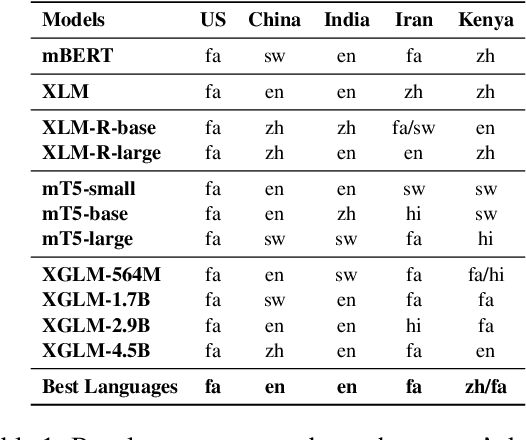
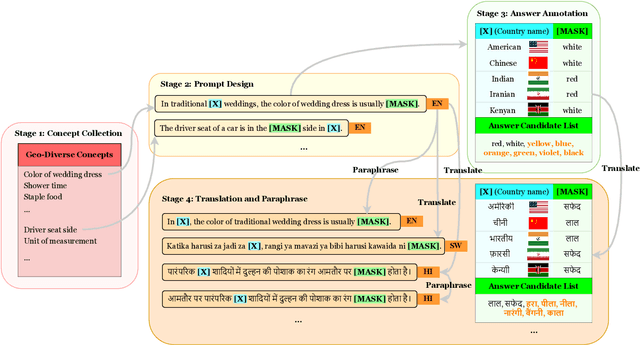
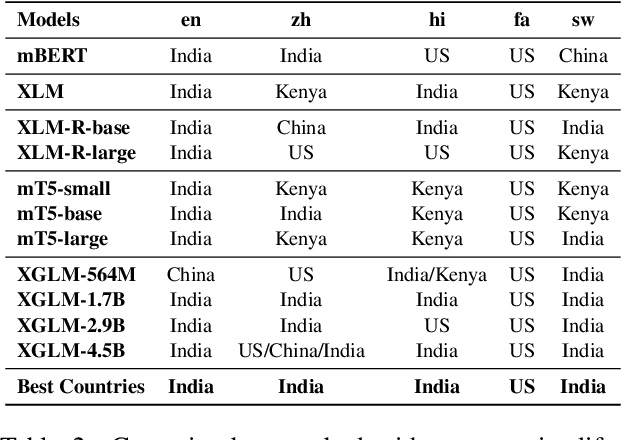
Recent work has shown that Pre-trained Language Models (PLMs) have the ability to store the relational knowledge from pre-training data in their model parameters. However, it is not clear up to what extent do PLMs store geo-diverse commonsense knowledge, the knowledge associated with a culture and only shared locally. For instance, the color of bridal dress is white in American weddings whereas it is red in Chinese weddings. Here, we wish to probe if PLMs can predict red and white as the color of the bridal dress when queried for American and Chinese weddings, respectively. To this end, we introduce a framework for geo-diverse commonsense probing on multilingual PLMs (mPLMs) and introduce a corresponding benchmark Geo-diverse Commonsense Multilingual Language Model Analysis (GeoMLAMA) dataset. GeoMLAMA contains 3125 prompts in English, Chinese, Hindi, Persian, and Swahili, with a wide coverage of concepts shared by people from American, Chinese, Indian, Iranian and Kenyan cultures. We benchmark 11 standard mPLMs which include variants of mBERT, XLM, mT5, and XGLM on GeoMLAMA. Interestingly, we find that 1) larger mPLM variants do not necessarily store geo-diverse concepts better than its smaller variant; 2) mPLMs are not intrinsically biased towards knowledge from the Western countries (the United States); 3) the native language of a country may not be the best language to probe its knowledge and 4) a language may better probe knowledge about a non-native country than its native country.
ELEVATER: A Benchmark and Toolkit for Evaluating Language-Augmented Visual Models
Apr 20, 2022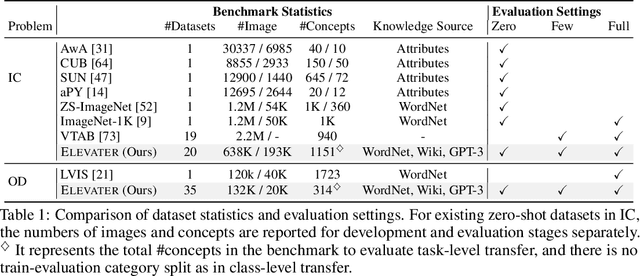

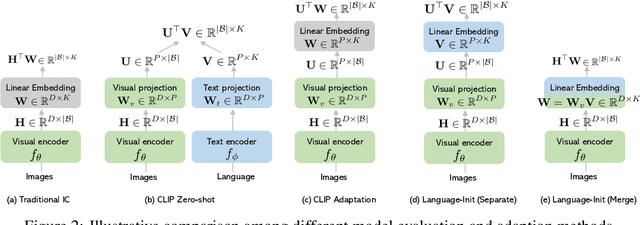
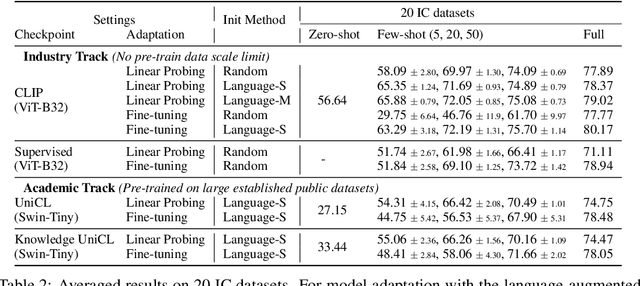
Learning visual representations from natural language supervision has recently shown great promise in a number of pioneering works. In general, these language-augmented visual models demonstrate strong transferability to a variety of datasets/tasks. However, it remains a challenge to evaluate the transferablity of these foundation models due to the lack of easy-to-use toolkits for fair benchmarking. To tackle this, we build ELEVATER (Evaluation of Language-augmented Visual Task-level Transfer), the first benchmark to compare and evaluate pre-trained language-augmented visual models. Several highlights include: (i) Datasets. As downstream evaluation suites, it consists of 20 image classification datasets and 35 object detection datasets, each of which is augmented with external knowledge. (ii) Toolkit. An automatic hyper-parameter tuning toolkit is developed to ensure the fairness in model adaption. To leverage the full power of language-augmented visual models, novel language-aware initialization methods are proposed to significantly improve the adaption performance. (iii) Metrics. A variety of evaluation metrics are used, including sample-efficiency (zero-shot and few-shot) and parameter-efficiency (linear probing and full model fine-tuning). We will release our toolkit and evaluation platforms for the research community.