 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards DS-NER: Unveiling and Addressing Latent Noise in Distant Annotations
May 18, 2025Distantly supervised named entity recognition (DS-NER) has emerged as a cheap and convenient alternative to traditional human annotation methods, enabling the automatic generation of training data by aligning text with external resources. Despite the many efforts in noise measurement methods, few works focus on the latent noise distribution between different distant annotation methods. In this work, we explore the effectiveness and robustness of DS-NER by two aspects: (1) distant annotation techniques, which encompasses both traditional rule-based methods and the innovative large language model supervision approach, and (2) noise assessment, for which we introduce a novel framework. This framework addresses the challenges by distinctly categorizing them into the unlabeled-entity problem (UEP) and the noisy-entity problem (NEP), subsequently providing specialized solutions for each. Our proposed method achieves significant improvements on eight real-world distant supervision datasets originating from three different data sources and involving four distinct annotation techniques, confirming its superiority over current state-of-the-art methods.
DIDS: Domain Impact-aware Data Sampling for Large Language Model Training
Apr 17, 2025



Large language models (LLMs) are commonly trained on multi-domain datasets, where domain sampling strategies significantly impact model performance due to varying domain importance across downstream tasks. Existing approaches for optimizing domain-level sampling strategies struggle with maintaining intra-domain consistency and accurately measuring domain impact. In this paper, we present Domain Impact-aware Data Sampling (DIDS). To ensure intra-domain consistency, a gradient clustering algorithm is proposed to group training data based on their learning effects, where a proxy language model and dimensionality reduction are employed to reduce computational overhead. To accurately measure domain impact, we develop a Fisher Information Matrix (FIM) guided metric that quantifies how domain-specific parameter updates affect the model's output distributions on downstream tasks, with theoretical guarantees. Furthermore, to determine optimal sampling ratios, DIDS combines both the FIM-guided domain impact assessment and loss learning trajectories that indicate domain-specific potential, while accounting for diminishing marginal returns. Extensive experiments demonstrate that DIDS achieves 3.4% higher average performance while maintaining comparable training efficiency.
A Pilot Empirical Study on When and How to Use Knowledge Graphs as Retrieval Augmented Generation
Feb 28, 2025The integration of Knowledge Graphs (KGs) into the Retrieval Augmented Generation (RAG) framework has attracted significant interest, with early studies showing promise in mitigating hallucinations and improving model accuracy. However, a systematic understanding and comparative analysis of the rapidly emerging KG-RAG methods are still lacking. This paper seeks to lay the foundation for systematically answering the question of when and how to use KG-RAG by analyzing their performance in various application scenarios associated with different technical configurations. After outlining the mind map using KG-RAG framework and summarizing its popular pipeline, we conduct a pilot empirical study of KG-RAG works to reimplement and evaluate 6 KG-RAG methods across 7 datasets in diverse scenarios, analyzing the impact of 9 KG-RAG configurations in combination with 17 LLMs. Our results underscore the critical role of appropriate application conditions and optimal configurations of KG-RAG components.
Top Ten Challenges Towards Agentic Neural Graph Databases
Jan 24, 2025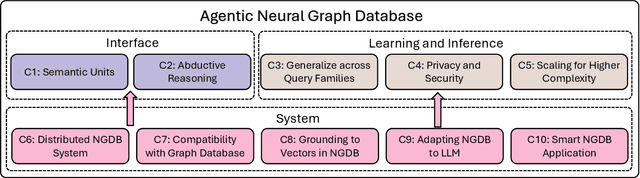
Graph databases (GDBs) like Neo4j and TigerGraph excel at handling interconnected data but lack advanced inference capabilities. Neural Graph Databases (NGDBs) address this by integrating Graph Neural Networks (GNNs) for predictive analysis and reasoning over incomplete or noisy data. However, NGDBs rely on predefined queries and lack autonomy and adaptability. This paper introduces Agentic Neural Graph Databases (Agentic NGDBs), which extend NGDBs with three core functionalities: autonomous query construction, neural query execution, and continuous learning. We identify ten key challenges in realizing Agentic NGDBs: semantic unit representation, abductive reasoning, scalable query execution, and integration with foundation models like large language models (LLMs). By addressing these challenges, Agentic NGDBs can enable intelligent, self-improving systems for modern data-driven applications, paving the way for adaptable and autonomous data management solutions.
ElasTST: Towards Robust Varied-Horizon Forecasting with Elastic Time-Series Transformer
Nov 04, 2024



Numerous industrial sectors necessitate models capable of providing robust forecasts across various horizons. Despite the recent strides in crafting specific architectures for time-series forecasting and developing pre-trained universal models, a comprehensive examination of their capability in accommodating varied-horizon forecasting during inference is still lacking. This paper bridges this gap through the design and evaluation of the Elastic Time-Series Transformer (ElasTST). The ElasTST model incorporates a non-autoregressive design with placeholders and structured self-attention masks, warranting future outputs that are invariant to adjustments in inference horizons. A tunable version of rotary position embedding is also integrated into ElasTST to capture time-series-specific periods and enhance adaptability to different horizons. Additionally, ElasTST employs a multi-scale patch design, effectively integrating both fine-grained and coarse-grained information. During the training phase, ElasTST uses a horizon reweighting strategy that approximates the effect of random sampling across multiple horizons with a single fixed horizon setting. Through comprehensive experiments and comparisons with state-of-the-art time-series architectures and contemporary foundation models, we demonstrate the efficacy of ElasTST's unique design elements. Our findings position ElasTST as a robust solution for the practical necessity of varied-horizon forecasting.
Exploring the Meaningfulness of Nearest Neighbor Search in High-Dimensional Space
Oct 08, 2024Dense high dimensional vectors are becoming increasingly vital in fields such as computer vision, machine learning, and large language models (LLMs), serving as standard representations for multimodal data. Now the dimensionality of these vector can exceed several thousands easily. Despite the nearest neighbor search (NNS) over these dense high dimensional vectors have been widely used for retrieval augmented generation (RAG) and many other applications, the effectiveness of NNS in such a high-dimensional space remains uncertain, given the possible challenge caused by the "curse of dimensionality." To address above question, in this paper, we conduct extensive NNS studies with different distance functions, such as $L_1$ distance, $L_2$ distance and angular-distance, across diverse embedding datasets, of varied types, dimensionality and modality. Our aim is to investigate factors influencing the meaningfulness of NNS. Our experiments reveal that high-dimensional text embeddings exhibit increased resilience as dimensionality rises to higher levels when compared to random vectors. This resilience suggests that text embeddings are less affected to the "curse of dimensionality," resulting in more meaningful NNS outcomes for practical use. Additionally, the choice of distance function has minimal impact on the relevance of NNS. Our study shows the effectiveness of the embedding-based data representation method and can offer opportunity for further optimization of dense vector-related applications.
Computation-friendly Graph Neural Network Design by Accumulating Knowledge on Large Language Models
Aug 13, 2024



Graph Neural Networks (GNNs), like other neural networks, have shown remarkable success but are hampered by the complexity of their architecture designs, which heavily depend on specific data and tasks. Traditionally, designing proper architectures involves trial and error, which requires intensive manual effort to optimize various components. To reduce human workload, researchers try to develop automated algorithms to design GNNs. However, both experts and automated algorithms suffer from two major issues in designing GNNs: 1) the substantial computational resources expended in repeatedly trying candidate GNN architectures until a feasible design is achieved, and 2) the intricate and prolonged processes required for humans or algorithms to accumulate knowledge of the interrelationship between graphs, GNNs, and performance. To further enhance the automation of GNN architecture design, we propose a computation-friendly way to empower Large Language Models (LLMs) with specialized knowledge in designing GNNs, thereby drastically shortening the computational overhead and development cycle of designing GNN architectures. Our framework begins by establishing a knowledge retrieval pipeline that comprehends the intercorrelations between graphs, GNNs, and performance. This pipeline converts past model design experiences into structured knowledge for LLM reference, allowing it to quickly suggest initial model proposals. Subsequently, we introduce a knowledge-driven search strategy that emulates the exploration-exploitation process of human experts, enabling quick refinement of initial proposals within a promising scope. Extensive experiments demonstrate that our framework can efficiently deliver promising (e.g., Top-5.77%) initial model proposals for unseen datasets within seconds and without any prior training and achieve outstanding search performance in a few iterations.
A Survey on Contribution Evaluation in Vertical Federated Learning
May 03, 2024Vertical Federated Learning (VFL) has emerged as a critical approach in machine learning to address privacy concerns associated with centralized data storage and processing. VFL facilitates collaboration among multiple entities with distinct feature sets on the same user population, enabling the joint training of predictive models without direct data sharing. A key aspect of VFL is the fair and accurate evaluation of each entity's contribution to the learning process. This is crucial for maintaining trust among participating entities, ensuring equitable resource sharing, and fostering a sustainable collaboration framework. This paper provides a thorough review of contribution evaluation in VFL. We categorize the vast array of contribution evaluation techniques along the VFL lifecycle, granularity of evaluation, privacy considerations, and core computational methods. We also explore various tasks in VFL that involving contribution evaluation and analyze their required evaluation properties and relation to the VFL lifecycle phases. Finally, we present a vision for the future challenges of contribution evaluation in VFL. By providing a structured analysis of the current landscape and potential advancements, this paper aims to guide researchers and practitioners in the design and implementation of more effective, efficient, and privacy-centric VFL solutions. Relevant literature and open-source resources have been compiled and are being continuously updated at the GitHub repository: \url{https://github.com/cuiyuebing/VFL_CE}.
Unifying Lane-Level Traffic Prediction from a Graph Structural Perspective: Benchmark and Baseline
Mar 22, 2024



Traffic prediction has long been a focal and pivotal area in research, witnessing both significant strides from city-level to road-level predictions in recent years. With the advancement of Vehicle-to-Everything (V2X) technologies, autonomous driving, and large-scale models in the traffic domain, lane-level traffic prediction has emerged as an indispensable direction. However, further progress in this field is hindered by the absence of comprehensive and unified evaluation standards, coupled with limited public availability of data and code. This paper extensively analyzes and categorizes existing research in lane-level traffic prediction, establishes a unified spatial topology structure and prediction tasks, and introduces a simple baseline model, GraphMLP, based on graph structure and MLP networks. We have replicated codes not publicly available in existing studies and, based on this, thoroughly and fairly assessed various models in terms of effectiveness, efficiency, and applicability, providing insights for practical applications. Additionally, we have released three new datasets and corresponding codes to accelerate progress in this field, all of which can be found on https://github.com/ShuhaoLii/TITS24LaneLevel-Traffic-Benchmark.
Deep Learning for Trajectory Data Management and Mining: A Survey and Beyond
Mar 21, 2024



Trajectory computing is a pivotal domain encompassing trajectory data management and mining, garnering widespread attention due to its crucial role in various practical applications such as location services, urban traffic, and public safety. Traditional methods, focusing on simplistic spatio-temporal features, face challenges of complex calculations, limited scalability, and inadequate adaptability to real-world complexities. In this paper, we present a comprehensive review of the development and recent advances in deep learning for trajectory computing (DL4Traj). We first define trajectory data and provide a brief overview of widely-used deep learning models. Systematically, we explore deep learning applications in trajectory management (pre-processing, storage, analysis, and visualization) and mining (trajectory-related forecasting, trajectory-related recommendation, trajectory classification, travel time estimation, anomaly detection, and mobility generation). Notably, we encapsulate recent advancements in Large Language Models (LLMs) that hold the potential to augment trajectory computing. Additionally, we summarize application scenarios, public datasets, and toolkits. Finally, we outline current challenges in DL4Traj research and propose future directions. Relevant papers and open-source resources have been collated and are continuously updated at: \href{https://github.com/yoshall/Awesome-Trajectory-Computing}{DL4Traj Repo}.