 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Progressive Learning for Efficient Training of Vision Transformers
Mar 28, 2022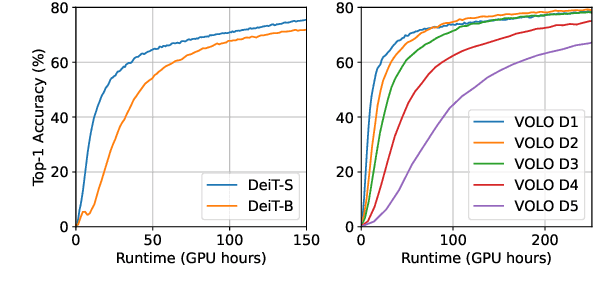
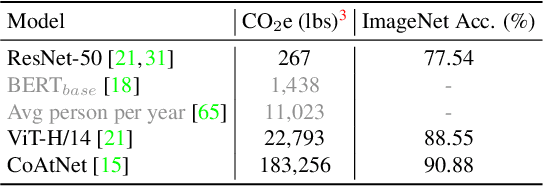
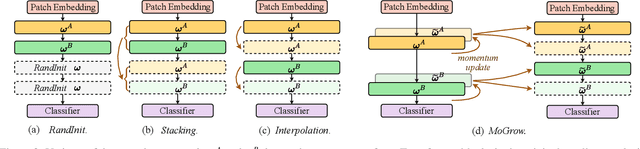
Recent advances in vision Transformers (ViTs) have come with a voracious appetite for computing power, high-lighting the urgent need to develop efficient training methods for ViTs. Progressive learning, a training scheme where the model capacity grows progressively during training, has started showing its ability in efficient training. In this paper, we take a practical step towards efficient training of ViTs by customizing and automating progressive learning. First, we develop a strong manual baseline for progressive learning of ViTs, by introducing momentum growth (MoGrow) to bridge the gap brought by model growth. Then, we propose automated progressive learning (AutoProg), an efficient training scheme that aims to achieve lossless acceleration by automatically increasing the training overload on-the-fly; this is achieved by adaptively deciding whether, where and how much should the model grow during progressive learning. Specifically, we first relax the optimization of the growth schedule to sub-network architecture optimization problem, then propose one-shot estimation of the sub-network performance via an elastic supernet. The searching overhead is reduced to minimal by recycling the parameters of the supernet. Extensive experiments of efficient training on ImageNet with two representative ViT models, DeiT and VOLO, demonstrate that AutoProg can accelerate ViTs training by up to 85.1% with no performance drop. Code: https://github.com/changlin31/AutoProg
Laneformer: Object-aware Row-Column Transformers for Lane Detection
Mar 18, 2022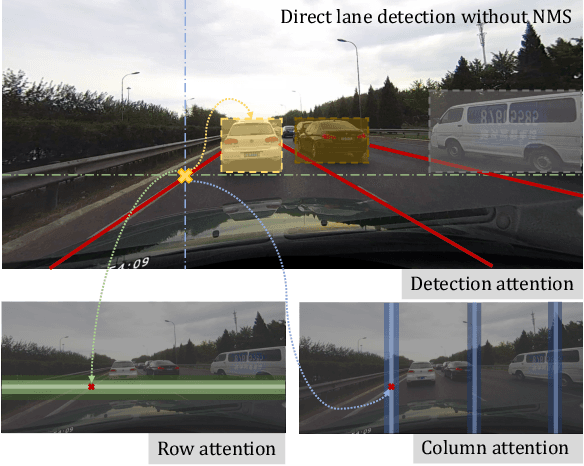
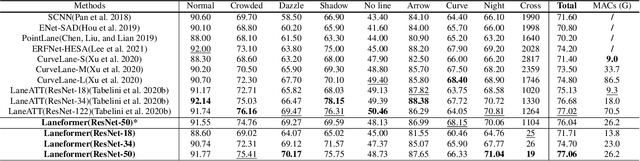
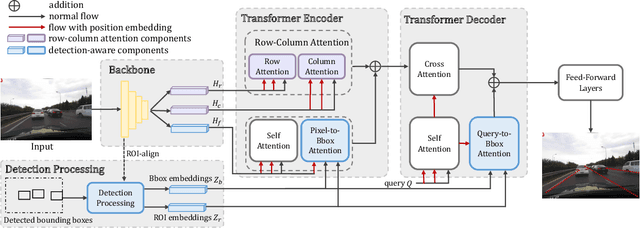
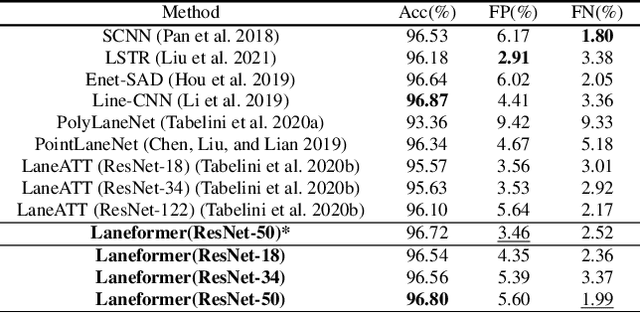
We present Laneformer, a conceptually simple yet powerful transformer-based architecture tailored for lane detection that is a long-standing research topic for visual perception in autonomous driving. The dominant paradigms rely on purely CNN-based architectures which often fail in incorporating relations of long-range lane points and global contexts induced by surrounding objects (e.g., pedestrians, vehicles). Inspired by recent advances of the transformer encoder-decoder architecture in various vision tasks, we move forwards to design a new end-to-end Laneformer architecture that revolutionizes the conventional transformers into better capturing the shape and semantic characteristics of lanes, with minimal overhead in latency. First, coupling with deformable pixel-wise self-attention in the encoder, Laneformer presents two new row and column self-attention operations to efficiently mine point context along with the lane shapes. Second, motivated by the appearing objects would affect the decision of predicting lane segments, Laneformer further includes the detected object instances as extra inputs of multi-head attention blocks in the encoder and decoder to facilitate the lane point detection by sensing semantic contexts. Specifically, the bounding box locations of objects are added into Key module to provide interaction with each pixel and query while the ROI-aligned features are inserted into Value module. Extensive experiments demonstrate our Laneformer achieves state-of-the-art performances on CULane benchmark, in terms of 77.1% F1 score. We hope our simple and effective Laneformer will serve as a strong baseline for future research in self-attention models for lane detection.
elBERto: Self-supervised Commonsense Learning for Question Answering
Mar 17, 2022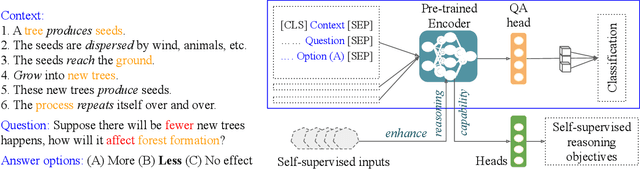

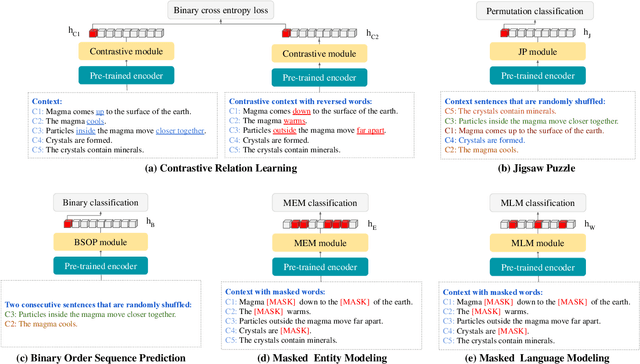
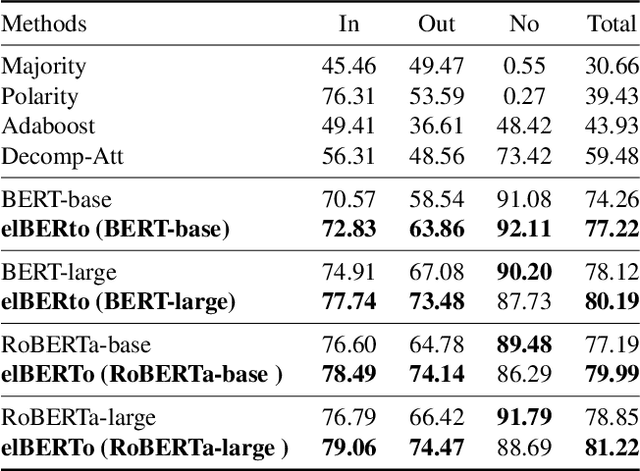
Commonsense question answering requires reasoning about everyday situations and causes and effects implicit in context. Typically, existing approaches first retrieve external evidence and then perform commonsense reasoning using these evidence. In this paper, we propose a Self-supervised Bidirectional Encoder Representation Learning of Commonsense (elBERto) framework, which is compatible with off-the-shelf QA model architectures. The framework comprises five self-supervised tasks to force the model to fully exploit the additional training signals from contexts containing rich commonsense. The tasks include a novel Contrastive Relation Learning task to encourage the model to distinguish between logically contrastive contexts, a new Jigsaw Puzzle task that requires the model to infer logical chains in long contexts, and three classic SSL tasks to maintain pre-trained models language encoding ability. On the representative WIQA, CosmosQA, and ReClor datasets, elBERto outperforms all other methods, including those utilizing explicit graph reasoning and external knowledge retrieval. Moreover, elBERto achieves substantial improvements on out-of-paragraph and no-effect questions where simple lexical similarity comparison does not help, indicating that it successfully learns commonsense and is able to leverage it when given dynamic context.
CODA: A Real-World Road Corner Case Dataset for Object Detection in Autonomous Driving
Mar 15, 2022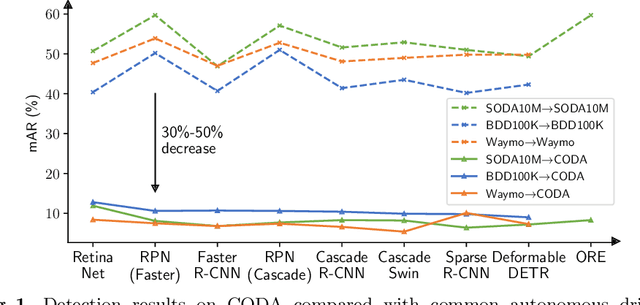
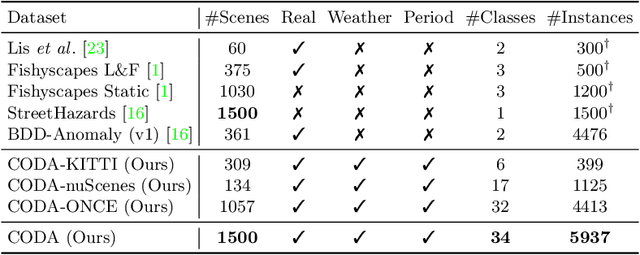

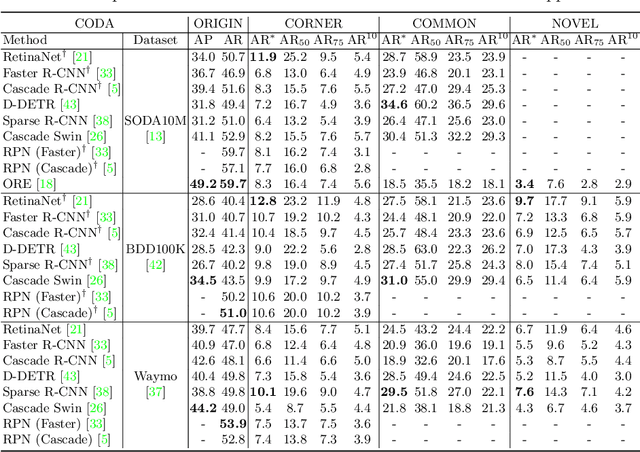
Contemporary deep-learning object detection methods for autonomous driving usually assume prefixed categories of common traffic participants, such as pedestrians and cars. Most existing detectors are unable to detect uncommon objects and corner cases (e.g., a dog crossing a street), which may lead to severe accidents in some situations, making the timeline for the real-world application of reliable autonomous driving uncertain. One main reason that impedes the development of truly reliably self-driving systems is the lack of public datasets for evaluating the performance of object detectors on corner cases. Hence, we introduce a challenging dataset named CODA that exposes this critical problem of vision-based detectors. The dataset consists of 1500 carefully selected real-world driving scenes, each containing four object-level corner cases (on average), spanning 30+ object categories. On CODA, the performance of standard object detectors trained on large-scale autonomous driving datasets significantly drops to no more than 12.8% in mAR. Moreover, we experiment with the state-of-the-art open-world object detector and find that it also fails to reliably identify the novel objects in CODA, suggesting that a robust perception system for autonomous driving is probably still far from reach. We expect our CODA dataset to facilitate further research in reliable detection for real-world autonomous driving. Our dataset will be released at https://coda-dataset.github.io.
Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework
Mar 10, 2022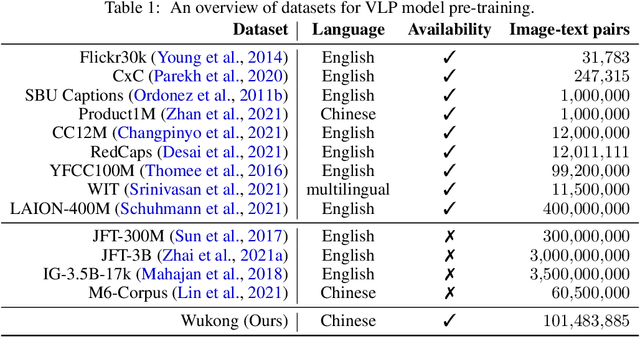
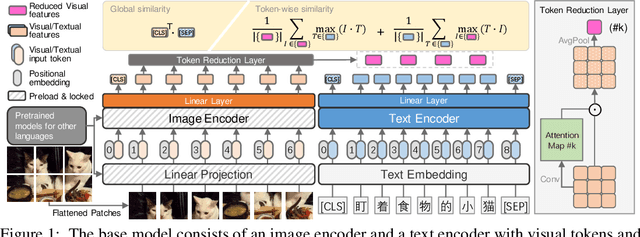


Vision-Language Pre-training (VLP) models have shown remarkable performance on various downstream tasks. Their success heavily relies on the scale of pre-trained cross-modal datasets. However, the lack of large-scale datasets and benchmarks in Chinese hinders the development of Chinese VLP models and broader multilingual applications. In this work, we release a large-scale Chinese cross-modal dataset named Wukong, containing 100 million Chinese image-text pairs from the web. Wukong aims to benchmark different multi-modal pre-training methods to facilitate the VLP research and community development. Furthermore, we release a group of models pre-trained with various image encoders (ViT-B/ViT-L/SwinT) and also apply advanced pre-training techniques into VLP such as locked-image text tuning, token-wise similarity in contrastive learning, and reduced-token interaction. Extensive experiments and a deep benchmarking of different downstream tasks are also provided. Experiments show that Wukong can serve as a promising Chinese pre-training dataset and benchmark for different cross-modal learning methods. For the zero-shot image classification task on 10 datasets, our model achieves an average accuracy of 73.03%. For the image-text retrieval task,our model achieves a mean recall of 71.6% on AIC-ICC which is 12.9% higher than the result of WenLan 2.0. More information can refer to https://wukong-dataset.github.io/wukong-dataset/.
Visual-Language Navigation Pretraining via Prompt-based Environmental Self-exploration
Mar 08, 2022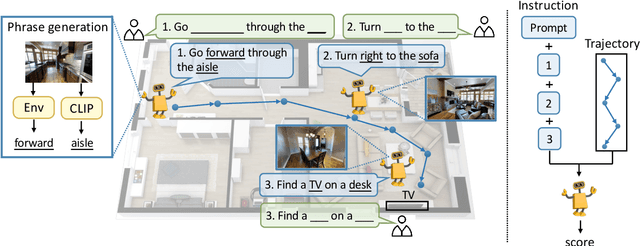

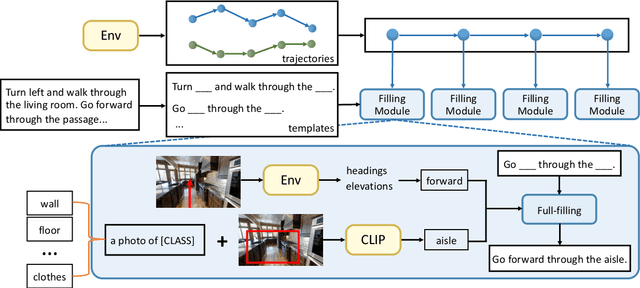
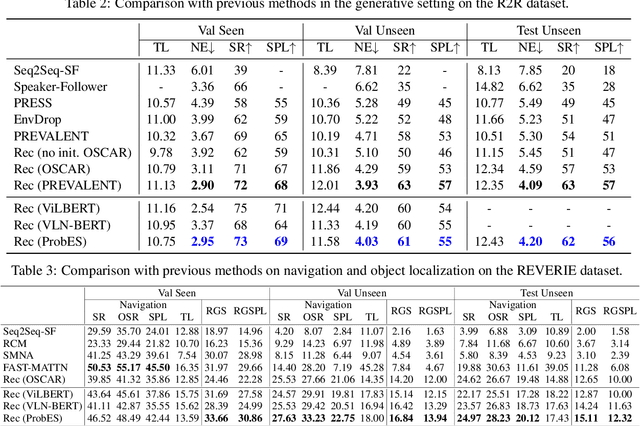
Vision-language navigation (VLN) is a challenging task due to its large searching space in the environment. To address this problem, previous works have proposed some methods of fine-tuning a large model that pretrained on large-scale datasets. However, the conventional fine-tuning methods require extra human-labeled navigation data and lack self-exploration capabilities in environments, which hinders their generalization of unseen scenes. To improve the ability of fast cross-domain adaptation, we propose Prompt-based Environmental Self-exploration (ProbES), which can self-explore the environments by sampling trajectories and automatically generates structured instructions via a large-scale cross-modal pretrained model (CLIP). Our method fully utilizes the knowledge learned from CLIP to build an in-domain dataset by self-exploration without human labeling. Unlike the conventional approach of fine-tuning, we introduce prompt-based learning to achieve fast adaptation for language embeddings, which substantially improves the learning efficiency by leveraging prior knowledge. By automatically synthesizing trajectory-instruction pairs in any environment without human supervision and efficient prompt-based learning, our model can adapt to diverse vision-language navigation tasks, including VLN and REVERIE. Both qualitative and quantitative results show that our ProbES significantly improves the generalization ability of the navigation model.
Modern Augmented Reality: Applications, Trends, and Future Directions
Feb 24, 2022



Augmented reality (AR) is one of the relatively old, yet trending areas in the intersection of computer vision and computer graphics with numerous applications in several areas, from gaming and entertainment, to education and healthcare. Although it has been around for nearly fifty years, it has seen a lot of interest by the research community in the recent years, mainly because of the huge success of deep learning models for various computer vision and AR applications, which made creating new generations of AR technologies possible. This work tries to provide an overview of modern augmented reality, from both application-level and technical perspective. We first give an overview of main AR applications, grouped into more than ten categories. We then give an overview of around 100 recent promising machine learning based works developed for AR systems, such as deep learning works for AR shopping (clothing, makeup), AR based image filters (such as Snapchat's lenses), AR animations, and more. In the end we discuss about some of the current challenges in AR domain, and the future directions in this area.
Revisiting Over-smoothing in BERT from the Perspective of Graph
Feb 17, 2022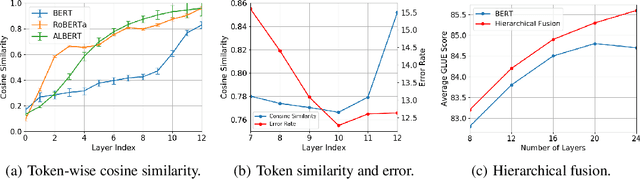
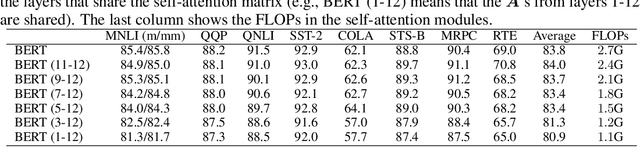
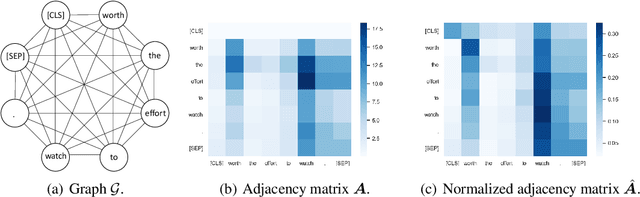
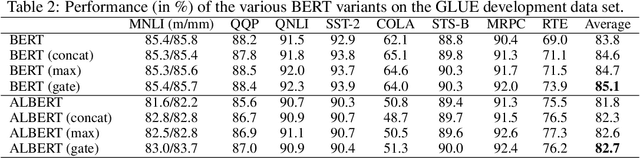
Recently over-smoothing phenomenon of Transformer-based models is observed in both vision and language fields. However, no existing work has delved deeper to further investigate the main cause of this phenomenon. In this work, we make the attempt to analyze the over-smoothing problem from the perspective of graph, where such problem was first discovered and explored. Intuitively, the self-attention matrix can be seen as a normalized adjacent matrix of a corresponding graph. Based on the above connection, we provide some theoretical analysis and find that layer normalization plays a key role in the over-smoothing issue of Transformer-based models. Specifically, if the standard deviation of layer normalization is sufficiently large, the output of Transformer stacks will converge to a specific low-rank subspace and result in over-smoothing. To alleviate the over-smoothing problem, we consider hierarchical fusion strategies, which combine the representations from different layers adaptively to make the output more diverse. Extensive experiment results on various data sets illustrate the effect of our fusion method.
Exploring Inter-Channel Correlation for Diversity-preserved KnowledgeDistillation
Feb 08, 2022

Knowledge Distillation has shown very promising abil-ity in transferring learned representation from the largermodel (teacher) to the smaller one (student).Despitemany efforts, prior methods ignore the important role ofretaining inter-channel correlation of features, leading tothe lack of capturing intrinsic distribution of the featurespace and sufficient diversity properties of features in theteacher network.To solve the issue, we propose thenovel Inter-Channel Correlation for Knowledge Distillation(ICKD), with which the diversity and homology of the fea-ture space of the student network can align with that ofthe teacher network. The correlation between these twochannels is interpreted as diversity if they are irrelevantto each other, otherwise homology. Then the student isrequired to mimic the correlation within its own embed-ding space. In addition, we introduce the grid-level inter-channel correlation, making it capable of dense predictiontasks. Extensive experiments on two vision tasks, includ-ing ImageNet classification and Pascal VOC segmentation,demonstrate the superiority of our ICKD, which consis-tently outperforms many existing methods, advancing thestate-of-the-art in the fields of Knowledge Distillation. Toour knowledge, we are the first method based on knowl-edge distillation boosts ResNet18 beyond 72% Top-1 ac-curacy on ImageNet classification. Code is available at:https://github.com/ADLab-AutoDrive/ICKD.
Contrastive Instruction-Trajectory Learning for Vision-Language Navigation
Dec 09, 2021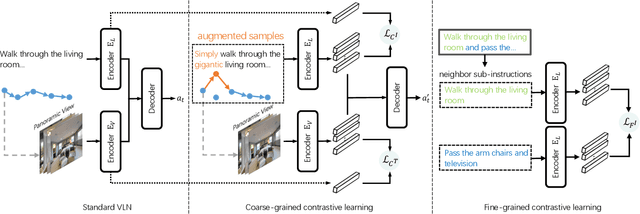
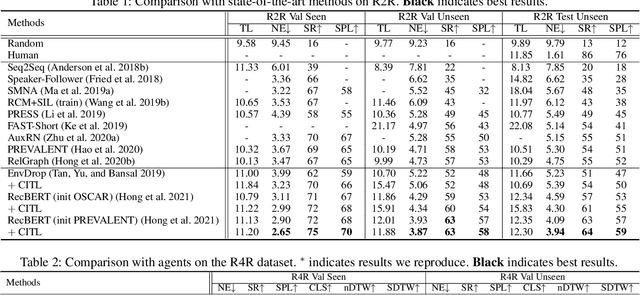
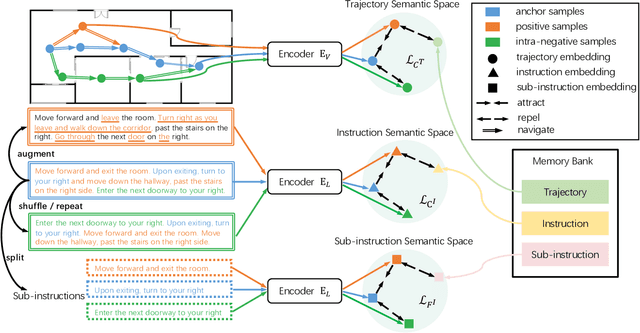
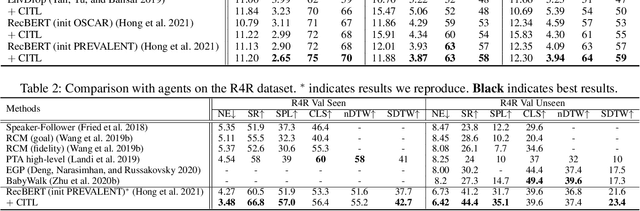
The vision-language navigation (VLN) task requires an agent to reach a target with the guidance of natural language instruction. Previous works learn to navigate step-by-step following an instruction. However, these works may fail to discriminate the similarities and discrepancies across instruction-trajectory pairs and ignore the temporal continuity of sub-instructions. These problems hinder agents from learning distinctive vision-and-language representations, harming the robustness and generalizability of the navigation policy. In this paper, we propose a Contrastive Instruction-Trajectory Learning (CITL) framework that explores invariance across similar data samples and variance across different ones to learn distinctive representations for robust navigation. Specifically, we propose: (1) a coarse-grained contrastive learning objective to enhance vision-and-language representations by contrasting semantics of full trajectory observations and instructions, respectively; (2) a fine-grained contrastive learning objective to perceive instructions by leveraging the temporal information of the sub-instructions; (3) a pairwise sample-reweighting mechanism for contrastive learning to mine hard samples and hence mitigate the influence of data sampling bias in contrastive learning. Our CITL can be easily integrated with VLN backbones to form a new learning paradigm and achieve better generalizability in unseen environments. Extensive experiments show that the model with CITL surpasses the previous state-of-the-art methods on R2R, R4R, and RxR.