 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIVERSE: Unified Video Action Models for Autonomous Driving with Flexible Mask-Modulated Modality Generation
Jul 06, 2026World Action Models (WAMs) have shown strong potential for improving action generalization in autonomous driving by using future video prediction as dense supervision for scene dynamics and temporal causality. However, it remains unclear which architecture better transfers video-modeling benefits to trajectory generation. Existing cascaded or dual-DiT designs separate video imagination from action prediction, weakening the transfer of video-learned world dynamics to the trajectory branch: the action model may still overfit dataset-specific driving priors, while the video model only indirectly regularizes planning. We propose UNIVERSE, a unified video-action model built upon a single mask-modulated Diffusion Transformer. By co-training future video latents and ego-trajectory tokens within shared generative parameters, UNIVERSE allows dense video supervision to directly shape trajectory denoising, leading to stronger cross-domain action generalization. To ensure causal validity and efficient deployment, we introduce a Modality-Decoupling Visibility Mask, which shares historical context across modalities while blocking mutual attention between future video and trajectory tokens. This prevents future-target leakage and enables trajectory-only inference by removing future-video denoising at test time, achieving a $4.3\times$ speedup over joint video-action rollout while maintaining comparable planning accuracy. The same model also supports video-only and joint video-action rollouts. Experiments show that UNIVERSE achieves 91.0 PDMS on NAVSIM (vs. 89.6 for the Two-DiT variant), and demonstrates strong zero-shot transfer to nuScenes and Bench2Drive without fine-tuning, while ablations confirm the importance of single-DiT unification, video co-training, and mask-based modality decoupling.
Pondering the Way: Spatial-perceiving World Action Model for Embodied Navigation
Jun 29, 2026Existing world model-based planners for visual navigation typically follow a verification-centric paradigm, decoupling goal intent from trajectory synthesis. This approach suffers from candidate dependence, heavy computational overhead, and inconsistencies between sampled actions and predicted visuals. To address these issues, we propose SWAM (Spatial-perceiving World Action Model), a task-centric joint observation-action generation framework. Given start and goal RGB observations, SWAM performs single-pass inference to simultaneously generate intermediate RGB-D sequences and corresponding action trajectories, promoting goal-consistent trajectory generation and improved spatial feasibility. While SWAM leverages depth pseudo-labels during training to internalize spatial priors, it requires only monocular RGB input at inference time. We further introduce a visual-guided action refinement module and a trajectory-scale regularization loss to enforce fine-grained alignment between motion and visual cues while stabilizing predictions across varying distances. Extensive experiments show that SWAM significantly outperforms state-of-the-art two-stage planners in success rate, trajectory accuracy, and inference efficiency, while demonstrating robust zero-shot generalization to unseen environments.
DriveReward: A Comprehensive Dataset and Generative Vision-Language Reward Model for Autonomous Driving
Jun 07, 2026Reward models play a pivotal role in reinforcement learning (RL) and multi-modal trajectory selection for autonomous driving. However, acquiring such rewards typically relies on hand-crafted rule-based objectives or perception ground truth, which hinders generalization for data-scaling. While Vision-Language Models (VLMs) have demonstrated feasibility as reward models in other domains, their effectiveness in driving tasks remains underexplored. In this work, we bridge this gap by (1) introducing DriveReward, a reasoning trajectory evaluation dataset rigorously labeled via temporally-grounded visual guidance, and augmented with counterfactual driving behaviors., (2) alongside a specialized Vision-Language Reward Model. To address the scarcity of failure cases in conventional datasets, we propose a counterfactual data annotation scheme to construct cases encompassing diverse driving styles and erroneous behaviors. Evaluations on our proposed benchmark reveal that even leading open-source and proprietary VLMs fail to excel across all tasks, highlighting significant room for improvement in existing models. Building on these findings, we subsequently tailor a specialized 1B reward model that outperforms larger VLMs on task-specific reward alignment. Finally, we validate our reward model's effectiveness by integrating it into RL finetuning and multi-modal trajectory scoring across multiple baselines, achieving performance comparable to rule-based reward calculations in both open-loop and closed-loop evaluation.
Discrete-WAM: Unified Discrete Vision-Action Token Editing for World-Policy Learning
Jun 04, 2026Autonomous driving requires reasoning about how ego actions shape the evolution of the surrounding world. However, most end-to-end methods rely on direct state-to-action mappings, capturing correlations without explicitly modeling action-conditioned dynamics. Conversely, continuous-latent world models often lack compositional structure for causal reasoning across counterfactual futures. We introduce Discrete-WAM, a unified latent vision-action world policy that represents future visual states and ego actions as aligned discrete tokens, enabling compositional causal reasoning across alternative futures. Built upon this unified discrete alignment, Discrete-WAM establishes a shared discrete diffusion framework with unified generative tasks, jointly formulating world modeling, world-action policy, and hierarchical decision-enabled policy, supporting compositional generalization across diverse driving scenarios. Experiments on large-scale autonomous-driving benchmarks show that Discrete-WAM achieves competitive performance while supporting controllable generation and counterfactual reasoning, offering a principled path toward more reliable decision-making.
LVDrive: Latent Visual Representation Enhanced Vision-Language-Action Autonomous Driving Model
May 21, 2026Vision-Language-Action (VLA) models have emerged as a promising framework for end-to-end autonomous driving. However, existing VLAs typically rely on sparse action supervision, which underutilizes their powerful scene understanding and reasoning capabilities. Recent attempts to incorporate dense visual supervision via world modeling often overemphasize pixel-level image reconstruction, neglecting semantically meaningful scene representation learning. In this work, we propose LVDrive, a Latent Visual representation enhanced VLA framework for autonomous driving. LVDrive introduces a future scene prediction task into the VLA paradigm, where future representations are learned entirely in a high-level latent space under auxiliary supervision from a pretrained vision backbone. Departing from inefficient autoregressive generation, we jointly model future scene and motion prediction within a unified embedding space, processed in a single forward pass to conduct the future-aware reasoning. We further design a two-stage trajectory decoding strategy that explicitly leverages the learned latent future representations to refine trajectory generation. Extensive experiments on the challenging Bench2Drive benchmark demonstrate that LVDrive achieves significant improvements in closed-loop driving performance, outperforming both action supervised methods and image-reconstruction-based world model approaches.
OneVL: One-Step Latent Reasoning and Planning with Vision-Language Explanation
Apr 20, 2026Chain-of-Thought (CoT) reasoning has become a powerful driver of trajectory prediction in VLA-based autonomous driving, yet its autoregressive nature imposes a latency cost that is prohibitive for real-time deployment. Latent CoT methods attempt to close this gap by compressing reasoning into continuous hidden states, but consistently fall short of their explicit counterparts. We suggest that this is due to purely linguistic latent representations compressing a symbolic abstraction of the world, rather than the causal dynamics that actually govern driving. Thus, we present OneVL (One-step latent reasoning and planning with Vision-Language explanations), a unified VLA and World Model framework that routes reasoning through compact latent tokens supervised by dual auxiliary decoders. Alongside a language decoder that reconstructs text CoT, we introduce a visual world model decoder that predicts future-frame tokens, forcing the latent space to internalize the causal dynamics of road geometry, agent motion, and environmental change. A three-stage training pipeline progressively aligns these latents with trajectory, language, and visual objectives, ensuring stable joint optimization. At inference, the auxiliary decoders are discarded and all latent tokens are prefilled in a single parallel pass, matching the speed of answer-only prediction. Across four benchmarks, OneVL becomes the first latent CoT method to surpass explicit CoT, delivering state-of-the-art accuracy at answer-only latency, and providing direct evidence that tighter compression, when guided in both language and world-model supervision, produces more generalizable representations than verbose token-by-token reasoning. Project Page: https://xiaomi-embodied-intelligence.github.io/OneVL
DriveVA: Video Action Models are Zero-Shot Drivers
Apr 05, 2026Generalization is a central challenge in autonomous driving, as real-world deployment requires robust performance under unseen scenarios, sensor domains, and environmental conditions. Recent world-model-based planning methods have shown strong capabilities in scene understanding and multi-modal future prediction, yet their generalization across datasets and sensor configurations remains limited. In addition, their loosely coupled planning paradigm often leads to poor video-trajectory consistency during visual imagination. To overcome these limitations, we propose DriveVA, a novel autonomous driving world model that jointly decodes future visual forecasts and action sequences in a shared latent generative process. DriveVA inherits rich priors on motion dynamics and physical plausibility from well-pretrained large-scale video generation models to capture continuous spatiotemporal evolution and causal interaction patterns. To this end, DriveVA employs a DiT-based decoder to jointly predict future action sequences (trajectories) and videos, enabling tighter alignment between planning and scene evolution. We also introduce a video continuation strategy to strengthen long-duration rollout consistency. DriveVA achieves an impressive closed-loop performance of 90.9 PDM score on the challenge NAVSIM. Extensive experiments also demonstrate the zero-shot capability and cross-domain generalization of DriveVA, which reduces average L2 error and collision rate by 78.9% and 83.3% on nuScenes and 52.5% and 52.4% on the Bench2drive built on CARLA v2 compared with the state-of-the-art world-model-based planner.
UniDriveVLA: Unifying Understanding, Perception, and Action Planning for Autonomous Driving
Apr 02, 2026Vision-Language-Action (VLA) models have recently emerged in autonomous driving, with the promise of leveraging rich world knowledge to improve the cognitive capabilities of driving systems. However, adapting such models for driving tasks currently faces a critical dilemma between spatial perception and semantic reasoning. Consequently, existing VLA systems are forced into suboptimal compromises: directly adopting 2D Vision-Language Models yields limited spatial perception, whereas enhancing them with 3D spatial representations often impairs the native reasoning capacity of VLMs. We argue that this dilemma largely stems from the coupled optimization of spatial perception and semantic reasoning within shared model parameters. To overcome this, we propose UniDriveVLA, a Unified Driving Vision-Language-Action model based on Mixture-of-Transformers that addresses the perception-reasoning conflict via expert decoupling. Specifically, it comprises three experts for driving understanding, scene perception, and action planning, which are coordinated through masked joint attention. In addition, we combine a sparse perception paradigm with a three-stage progressive training strategy to improve spatial perception while maintaining semantic reasoning capability. Extensive experiments show that UniDriveVLA achieves state-of-the-art performance in open-loop evaluation on nuScenes and closed-loop evaluation on Bench2Drive. Moreover, it demonstrates strong performance across a broad range of perception, prediction, and understanding tasks, including 3D detection, online mapping, motion forecasting, and driving-oriented VQA, highlighting its broad applicability as a unified model for autonomous driving. Code and model have been released at https://github.com/xiaomi-research/unidrivevla
MindDrive: A Vision-Language-Action Model for Autonomous Driving via Online Reinforcement Learning
Dec 16, 2025



Current Vision-Language-Action (VLA) paradigms in autonomous driving primarily rely on Imitation Learning (IL), which introduces inherent challenges such as distribution shift and causal confusion. Online Reinforcement Learning offers a promising pathway to address these issues through trial-and-error learning. However, applying online reinforcement learning to VLA models in autonomous driving is hindered by inefficient exploration in continuous action spaces. To overcome this limitation, we propose MindDrive, a VLA framework comprising a large language model (LLM) with two distinct sets of LoRA parameters. The one LLM serves as a Decision Expert for scenario reasoning and driving decision-making, while the other acts as an Action Expert that dynamically maps linguistic decisions into feasible trajectories. By feeding trajectory-level rewards back into the reasoning space, MindDrive enables trial-and-error learning over a finite set of discrete linguistic driving decisions, instead of operating directly in a continuous action space. This approach effectively balances optimal decision-making in complex scenarios, human-like driving behavior, and efficient exploration in online reinforcement learning. Using the lightweight Qwen-0.5B LLM, MindDrive achieves Driving Score (DS) of 78.04 and Success Rate (SR) of 55.09% on the challenging Bench2Drive benchmark. To the best of our knowledge, this is the first work to demonstrate the effectiveness of online reinforcement learning for the VLA model in autonomous driving.
Extending Large Vision-Language Model for Diverse Interactive Tasks in Autonomous Driving
May 13, 2025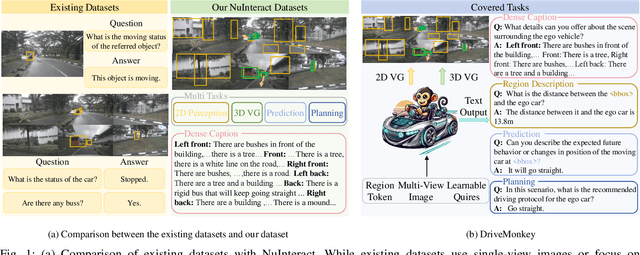

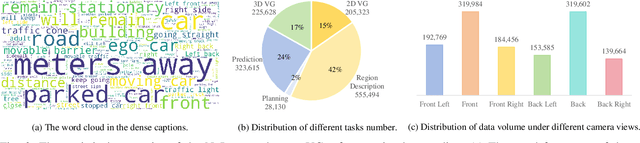
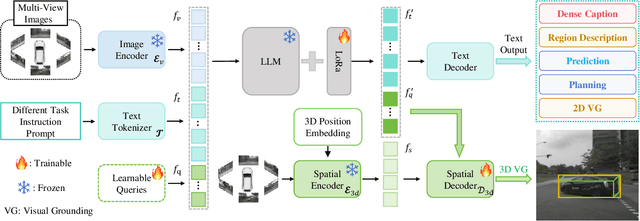
The Large Visual-Language Models (LVLMs) have significantly advanced image understanding. Their comprehension and reasoning capabilities enable promising applications in autonomous driving scenarios. However, existing research typically focuses on front-view perspectives and partial objects within scenes, struggling to achieve comprehensive scene understanding. Meanwhile, existing LVLMs suffer from the lack of mapping relationship between 2D and 3D and insufficient integration of 3D object localization and instruction understanding. To tackle these limitations, we first introduce NuInteract, a large-scale dataset with over 1.5M multi-view image language pairs spanning dense scene captions and diverse interactive tasks. Furthermore, we propose DriveMonkey, a simple yet effective framework that seamlessly integrates LVLMs with a spatial processor using a series of learnable queries. The spatial processor, designed as a plug-and-play component, can be initialized with pre-trained 3D detectors to improve 3D perception. Our experiments show that DriveMonkey outperforms general LVLMs, especially achieving a 9.86% notable improvement on the 3D visual grounding task. The dataset and code will be released at https://github.com/zc-zhao/DriveMonkey.