 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Semi-Supervised Learning
Dec 17, 2025



There has been significant recent interest in understanding the capacity of Transformers for in-context learning (ICL), yet most theory focuses on supervised settings with explicitly labeled pairs. In practice, Transformers often perform well even when labels are sparse or absent, suggesting crucial structure within unlabeled contextual demonstrations. We introduce and study in-context semi-supervised learning (IC-SSL), where a small set of labeled examples is accompanied by many unlabeled points, and show that Transformers can leverage the unlabeled context to learn a robust, context-dependent representation. This representation enables accurate predictions and markedly improves performance in low-label regimes, offering foundational insights into how Transformers exploit unlabeled context for representation learning within the ICL framework.
Quantum Machine Learning via Contrastive Training
Nov 17, 2025Quantum machine learning (QML) has attracted growing interest with the rapid parallel advances in large-scale classical machine learning and quantum technologies. Similar to classical machine learning, QML models also face challenges arising from the scarcity of labeled data, particularly as their scale and complexity increase. Here, we introduce self-supervised pretraining of quantum representations that reduces reliance on labeled data by learning invariances from unlabeled examples. We implement this paradigm on a programmable trapped-ion quantum computer, encoding images as quantum states. In situ contrastive pretraining on hardware yields a representation that, when fine-tuned, classifies image families with higher mean test accuracy and lower run-to-run variability than models trained from random initialization. Performance improvement is especially significant in regimes with limited labeled training data. We show that the learned invariances generalize beyond the pretraining image samples. Unlike prior work, our pipeline derives similarity from measured quantum overlaps and executes all training and classification stages on hardware. These results establish a label-efficient route to quantum representation learning, with direct relevance to quantum-native datasets and a clear path to larger classical inputs.
Graph Transformers Dream of Electric Flow
Oct 22, 2024



We show theoretically and empirically that the linear Transformer, when applied to graph data, can implement algorithms that solve canonical problems such as electric flow and eigenvector decomposition. The input to the Transformer is simply the graph incidence matrix; no other explicit positional encoding information is provided. We present explicit weight configurations for implementing each such graph algorithm, and we bound the errors of the constructed Transformers by the errors of the underlying algorithms. Our theoretical findings are corroborated by experiments on synthetic data. Additionally, on a real-world molecular regression task, we observe that the linear Transformer is capable of learning a more effective positional encoding than the default one based on Laplacian eigenvectors. Our work is an initial step towards elucidating the inner-workings of the Transformer for graph data.
Transformer In-Context Learning for Categorical Data
May 27, 2024



Recent research has sought to understand Transformers through the lens of in-context learning with functional data. We extend that line of work with the goal of moving closer to language models, considering categorical outcomes, nonlinear underlying models, and nonlinear attention. The contextual data are of the form $\textsf{C}=(x_1,c_1,\dots,x_N,c_{N})$ where each $c_i\in\{0,\dots,C-1\}$ is drawn from a categorical distribution that depends on covariates $x_i\in\mathbb{R}^d$. Contextual outcomes in the $m$th set of contextual data, $\textsf{C}_m$, are modeled in terms of latent function $f_m(x)\in\textsf{F}$, where $\textsf{F}$ is a functional class with $(C-1)$-dimensional vector output. The probability of observing class $c\in\{0,\dots,C-1\}$ is modeled in terms of the output components of $f_m(x)$ via the softmax. The Transformer parameters may be trained with $M$ contextual examples, $\{\textsf{C}_m\}_{m=1,M}$, and the trained model is then applied to new contextual data $\textsf{C}_{M+1}$ for new $f_{M+1}(x)\in\textsf{F}$. The goal is for the Transformer to constitute the probability of each category $c\in\{0,\dots,C-1\}$ for a new query $x_{N_{M+1}+1}$. We assume each component of $f_m(x)$ resides in a reproducing kernel Hilbert space (RKHS), specifying $\textsf{F}$. Analysis and an extensive set of experiments suggest that on its forward pass the Transformer (with attention defined by the RKHS kernel) implements a form of gradient descent of the underlying function, connected to the latent vector function associated with the softmax. We present what is believed to be the first real-world demonstration of this few-shot-learning methodology, using the ImageNet dataset.
Meta-Learned Attribute Self-Interaction Network for Continual and Generalized Zero-Shot Learning
Dec 02, 2023



Zero-shot learning (ZSL) is a promising approach to generalizing a model to categories unseen during training by leveraging class attributes, but challenges remain. Recently, methods using generative models to combat bias towards classes seen during training have pushed state of the art, but these generative models can be slow or computationally expensive to train. Also, these generative models assume that the attribute vector of each unseen class is available a priori at training, which is not always practical. Additionally, while many previous ZSL methods assume a one-time adaptation to unseen classes, in reality, the world is always changing, necessitating a constant adjustment of deployed models. Models unprepared to handle a sequential stream of data are likely to experience catastrophic forgetting. We propose a Meta-learned Attribute self-Interaction Network (MAIN) for continual ZSL. By pairing attribute self-interaction trained using meta-learning with inverse regularization of the attribute encoder, we are able to outperform state-of-the-art results without leveraging the unseen class attributes while also being able to train our models substantially faster (>100x) than expensive generative-based approaches. We demonstrate this with experiments on five standard ZSL datasets (CUB, aPY, AWA1, AWA2, and SUN) in the generalized zero-shot learning and continual (fixed/dynamic) zero-shot learning settings. Extensive ablations and analyses demonstrate the efficacy of various components proposed.
Open World Classification with Adaptive Negative Samples
Mar 09, 2023



Open world classification is a task in natural language processing with key practical relevance and impact. Since the open or {\em unknown} category data only manifests in the inference phase, finding a model with a suitable decision boundary accommodating for the identification of known classes and discrimination of the open category is challenging. The performance of existing models is limited by the lack of effective open category data during the training stage or the lack of a good mechanism to learn appropriate decision boundaries. We propose an approach based on \underline{a}daptive \underline{n}egative \underline{s}amples (ANS) designed to generate effective synthetic open category samples in the training stage and without requiring any prior knowledge or external datasets. Empirically, we find a significant advantage in using auxiliary one-versus-rest binary classifiers, which effectively utilize the generated negative samples and avoid the complex threshold-seeking stage in previous works. Extensive experiments on three benchmark datasets show that ANS achieves significant improvements over state-of-the-art methods.
Pushing the Efficiency Limit Using Structured Sparse Convolutions
Oct 23, 2022



Weight pruning is among the most popular approaches for compressing deep convolutional neural networks. Recent work suggests that in a randomly initialized deep neural network, there exist sparse subnetworks that achieve performance comparable to the original network. Unfortunately, finding these subnetworks involves iterative stages of training and pruning, which can be computationally expensive. We propose Structured Sparse Convolution (SSC), which leverages the inherent structure in images to reduce the parameters in the convolutional filter. This leads to improved efficiency of convolutional architectures compared to existing methods that perform pruning at initialization. We show that SSC is a generalization of commonly used layers (depthwise, groupwise and pointwise convolution) in ``efficient architectures.'' Extensive experiments on well-known CNN models and datasets show the effectiveness of the proposed method. Architectures based on SSC achieve state-of-the-art performance compared to baselines on CIFAR-10, CIFAR-100, Tiny-ImageNet, and ImageNet classification benchmarks.
Pseudo-OOD training for robust language models
Oct 17, 2022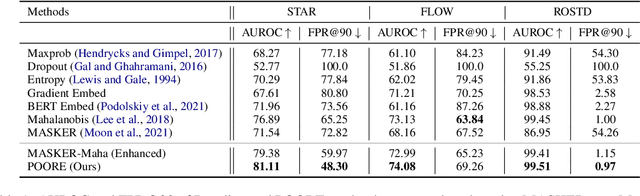

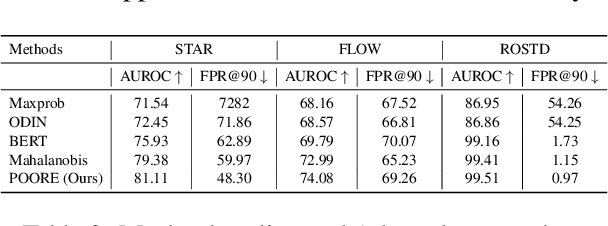

While pre-trained large-scale deep models have garnered attention as an important topic for many downstream natural language processing (NLP) tasks, such models often make unreliable predictions on out-of-distribution (OOD) inputs. As such, OOD detection is a key component of a reliable machine-learning model for any industry-scale application. Common approaches often assume access to additional OOD samples during the training stage, however, outlier distribution is often unknown in advance. Instead, we propose a post hoc framework called POORE - POsthoc pseudo-Ood REgularization, that generates pseudo-OOD samples using in-distribution (IND) data. The model is fine-tuned by introducing a new regularization loss that separates the embeddings of IND and OOD data, which leads to significant gains on the OOD prediction task during testing. We extensively evaluate our framework on three real-world dialogue systems, achieving new state-of-the-art in OOD detection.
Collaborative Anomaly Detection
Sep 20, 2022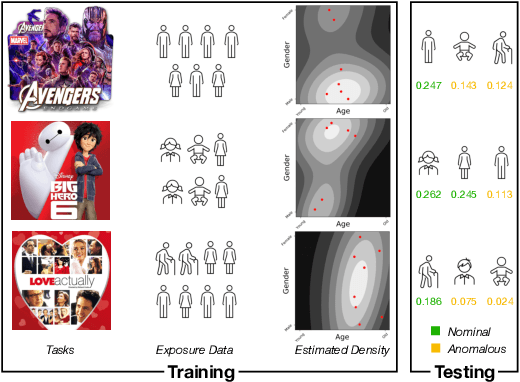
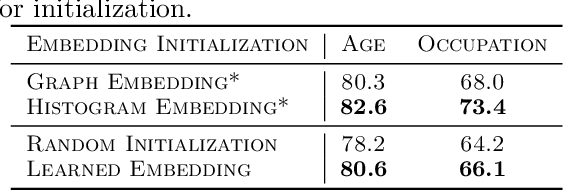
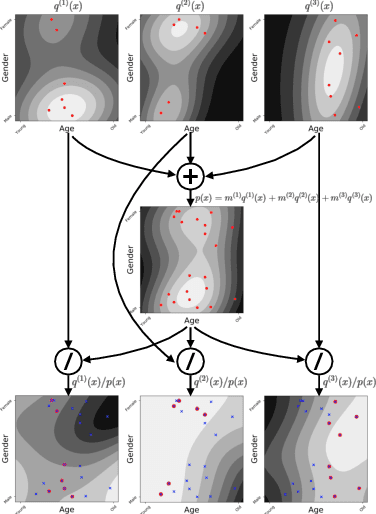

In recommendation systems, items are likely to be exposed to various users and we would like to learn about the familiarity of a new user with an existing item. This can be formulated as an anomaly detection (AD) problem distinguishing between "common users" (nominal) and "fresh users" (anomalous). Considering the sheer volume of items and the sparsity of user-item paired data, independently applying conventional single-task detection methods on each item quickly becomes difficult, while correlations between items are ignored. To address this multi-task anomaly detection problem, we propose collaborative anomaly detection (CAD) to jointly learn all tasks with an embedding encoding correlations among tasks. We explore CAD with conditional density estimation and conditional likelihood ratio estimation. We found that: $i$) estimating a likelihood ratio enjoys more efficient learning and yields better results than density estimation. $ii$) It is beneficial to select a small number of tasks in advance to learn a task embedding model, and then use it to warm-start all task embeddings. Consequently, these embeddings can capture correlations between tasks and generalize to new correlated tasks.
Number Entity Recognition
May 07, 2022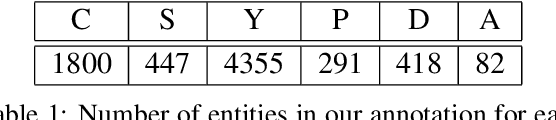
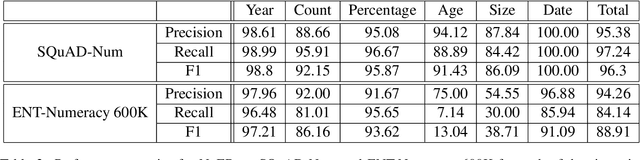

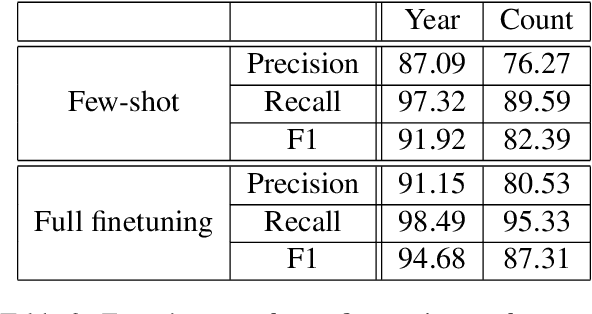
Numbers are essential components of text, like any other word tokens, from which natural language processing (NLP) models are built and deployed. Though numbers are typically not accounted for distinctly in most NLP tasks, there is still an underlying amount of numeracy already exhibited by NLP models. In this work, we attempt to tap this potential of state-of-the-art NLP models and transfer their ability to boost performance in related tasks. Our proposed classification of numbers into entities helps NLP models perform well on several tasks, including a handcrafted Fill-In-The-Blank (FITB) task and on question answering using joint embeddings, outperforming the BERT and RoBERTa baseline classification.