 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLLa: Video Reasoning Segmentation with Large Language Model
Jul 18, 2024Although video perception models have made remarkable advancements in recent years, they still heavily rely on explicit text descriptions or pre-defined categories to identify target instances before executing video perception tasks. These models, however, fail to proactively comprehend and reason the user's intentions via textual input. Even though previous works attempt to investigate solutions to incorporate reasoning with image segmentation, they fail to reason with videos due to the video's complexity in object motion. To bridge the gap between image and video, in this work, we propose a new video segmentation task - video reasoning segmentation. The task is designed to output tracklets of segmentation masks given a complex input text query. What's more, to promote research in this unexplored area, we construct a reasoning video segmentation benchmark. Finally, we present ViLLa: Video reasoning segmentation with a Large Language Model, which incorporates the language generation capabilities of multimodal Large Language Models (LLMs) while retaining the capabilities of detecting, segmenting, and tracking multiple instances. We use a temporal-aware context aggregation module to incorporate contextual visual cues to text embeddings and propose a video-frame decoder to build temporal correlations across segmentation tokens. Remarkably, our ViLLa demonstrates capability in handling complex reasoning and referring video segmentation. Also, our model shows impressive ability in different temporal understanding benchmarks. Both quantitative and qualitative experiments show our method effectively unlocks new video reasoning segmentation capabilities for multimodal LLMs. The code and dataset will be available at https://github.com/rkzheng99/ViLLa.
Deep Bag-of-Words Model: An Efficient and Interpretable Relevance Architecture for Chinese E-Commerce
Jul 12, 2024



Text relevance or text matching of query and product is an essential technique for the e-commerce search system to ensure that the displayed products can match the intent of the query. Many studies focus on improving the performance of the relevance model in search system. Recently, pre-trained language models like BERT have achieved promising performance on the text relevance task. While these models perform well on the offline test dataset, there are still obstacles to deploy the pre-trained language model to the online system as their high latency. The two-tower model is extensively employed in industrial scenarios, owing to its ability to harmonize performance with computational efficiency. Regrettably, such models present an opaque ``black box'' nature, which prevents developers from making special optimizations. In this paper, we raise deep Bag-of-Words (DeepBoW) model, an efficient and interpretable relevance architecture for Chinese e-commerce. Our approach proposes to encode the query and the product into the sparse BoW representation, which is a set of word-weight pairs. The weight means the important or the relevant score between the corresponding word and the raw text. The relevance score is measured by the accumulation of the matched word between the sparse BoW representation of the query and the product. Compared to popular dense distributed representation that usually suffers from the drawback of black-box, the most advantage of the proposed representation model is highly explainable and interventionable, which is a superior advantage to the deployment and operation of online search engines. Moreover, the online efficiency of the proposed model is even better than the most efficient inner product form of dense representation ...
PaliGemma: A versatile 3B VLM for transfer
Jul 10, 2024



PaliGemma is an open Vision-Language Model (VLM) that is based on the SigLIP-So400m vision encoder and the Gemma-2B language model. It is trained to be a versatile and broadly knowledgeable base model that is effective to transfer. It achieves strong performance on a wide variety of open-world tasks. We evaluate PaliGemma on almost 40 diverse tasks including standard VLM benchmarks, but also more specialized tasks such as remote-sensing and segmentation.
A Re-solving Heuristic for Dynamic Assortment Optimization with Knapsack Constraints
Jul 08, 2024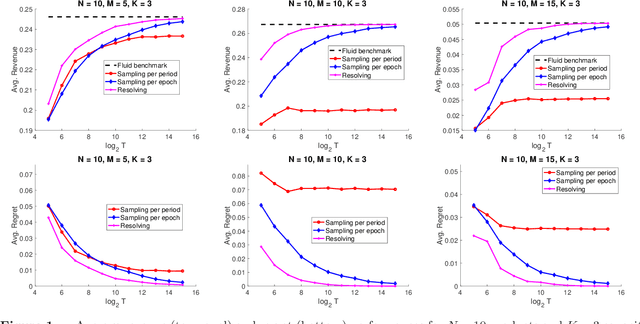
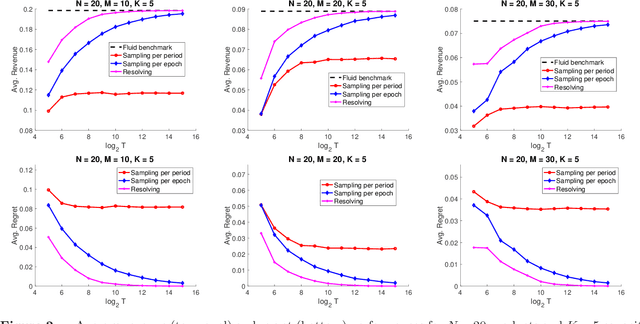
In this paper, we consider a multi-stage dynamic assortment optimization problem with multi-nomial choice modeling (MNL) under resource knapsack constraints. Given the current resource inventory levels, the retailer makes an assortment decision at each period, and the goal of the retailer is to maximize the total profit from purchases. With the exact optimal dynamic assortment solution being computationally intractable, a practical strategy is to adopt the re-solving technique that periodically re-optimizes deterministic linear programs (LP) arising from fluid approximation. However, the fractional structure of MNL makes the fluid approximation in assortment optimization highly non-linear, which brings new technical challenges. To address this challenge, we propose a new epoch-based re-solving algorithm that effectively transforms the denominator of the objective into the constraint. Theoretically, we prove that the regret (i.e., the gap between the resolving policy and the optimal objective of the fluid approximation) scales logarithmically with the length of time horizon and resource capacities.
2.4-THz Bandwidth Optical Coherent Receiver Based on a Photonic Crystal Microcomb
Jul 04, 2024



We demonstrate a spectrally-sliced single-polarization optical coherent receiver with a record 2.4-THz bandwidth, using a 200-GHz tantalum pentoxide photonic crystal microring resonator as the local oscillator frequency comb.
To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models
Jul 02, 2024
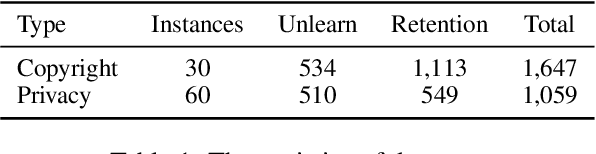
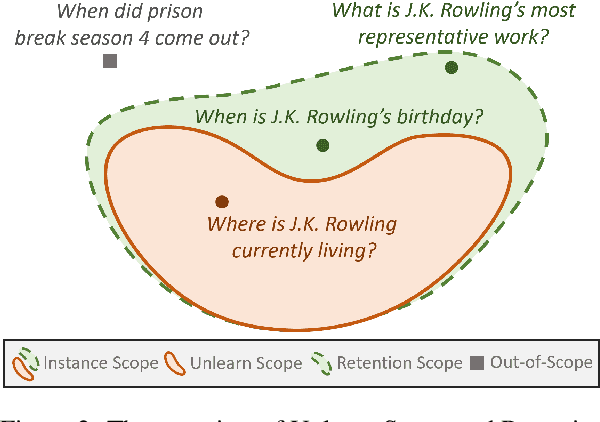
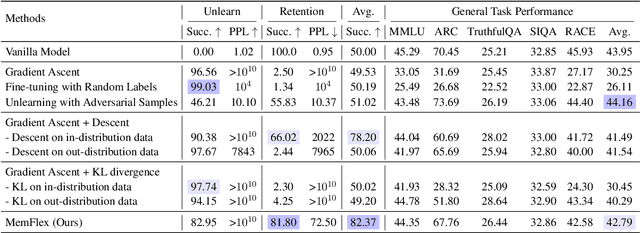
Large Language Models (LLMs) trained on extensive corpora inevitably retain sensitive data, such as personal privacy information and copyrighted material. Recent advancements in knowledge unlearning involve updating LLM parameters to erase specific knowledge. However, current unlearning paradigms are mired in vague forgetting boundaries, often erasing knowledge indiscriminately. In this work, we introduce KnowUnDo, a benchmark containing copyrighted content and user privacy domains to evaluate if the unlearning process inadvertently erases essential knowledge. Our findings indicate that existing unlearning methods often suffer from excessive unlearning. To address this, we propose a simple yet effective method, MemFlex, which utilizes gradient information to precisely target and unlearn sensitive parameters. Experimental results show that MemFlex is superior to existing methods in both precise knowledge unlearning and general knowledge retaining of LLMs. Code and dataset will be released at https://github.com/zjunlp/KnowUnDo.
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging
Jun 24, 2024While large language models (LLMs) excel in many domains, their complexity and scale challenge deployment in resource-limited environments. Current compression techniques, such as parameter pruning, often fail to effectively utilize the knowledge from pruned parameters. To address these challenges, we propose Manifold-Based Knowledge Alignment and Layer Merging Compression (MKA), a novel approach that uses manifold learning and the Normalized Pairwise Information Bottleneck (NPIB) measure to merge similar layers, reducing model size while preserving essential performance. We evaluate MKA on multiple benchmark datasets and various LLMs. Our findings show that MKA not only preserves model performance but also achieves substantial compression ratios, outperforming traditional pruning methods. Moreover, when coupled with quantization, MKA delivers even greater compression. Specifically, on the MMLU dataset using the Llama3-8B model, MKA achieves a compression ratio of 43.75% with a minimal performance decrease of only 2.82\%. The proposed MKA method offers a resource-efficient and performance-preserving model compression technique for LLMs.
An Active Search Strategy with Multiple Unmanned Aerial Systems for Multiple Targets
Jun 24, 2024



The challenge of efficient target searching in vast natural environments has driven the need for advanced multi-UAV active search strategies. This paper introduces a novel method in which global and local information is adeptly merged to avoid issues such as myopia and redundant back-and-forth movements. In addition, a trajectory generation method is used to ensure the search pattern within continuous space. To further optimize multi-agent cooperation, the Voronoi partition technique is employed, ensuring a reduction in repetitive flight patterns and making the control of multiple agents in a decentralized way. Through a series of experiments, the evaluation and comparison results demonstrate the efficiency of our approach in various environments. The primary application of this innovative approach is demonstrated in the search for horseshoe crabs within their wild habitats, showcasing its potential to revolutionize ecological survey and conservation efforts.
Job-SDF: A Multi-Granularity Dataset for Job Skill Demand Forecasting and Benchmarking
Jun 17, 2024In a rapidly evolving job market, skill demand forecasting is crucial as it enables policymakers and businesses to anticipate and adapt to changes, ensuring that workforce skills align with market needs, thereby enhancing productivity and competitiveness. Additionally, by identifying emerging skill requirements, it directs individuals towards relevant training and education opportunities, promoting continuous self-learning and development. However, the absence of comprehensive datasets presents a significant challenge, impeding research and the advancement of this field. To bridge this gap, we present Job-SDF, a dataset designed to train and benchmark job-skill demand forecasting models. Based on 10.35 million public job advertisements collected from major online recruitment platforms in China between 2021 and 2023, this dataset encompasses monthly recruitment demand for 2,324 types of skills across 521 companies. Our dataset uniquely enables evaluating skill demand forecasting models at various granularities, including occupation, company, and regional levels. We benchmark a range of models on this dataset, evaluating their performance in standard scenarios, in predictions focused on lower value ranges, and in the presence of structural breaks, providing new insights for further research. Our code and dataset are publicly accessible via the https://github.com/Job-SDF/benchmark.
Towards Adaptive Neighborhood for Advancing Temporal Interaction Graph Modeling
Jun 14, 2024



Temporal Graph Networks (TGNs) have demonstrated their remarkable performance in modeling temporal interaction graphs. These works can generate temporal node representations by encoding the surrounding neighborhoods for the target node. However, an inherent limitation of existing TGNs is their reliance on fixed, hand-crafted rules for neighborhood encoding, overlooking the necessity for an adaptive and learnable neighborhood that can accommodate both personalization and temporal evolution across different timestamps. In this paper, we aim to enhance existing TGNs by introducing an adaptive neighborhood encoding mechanism. We present SEAN, a flexible plug-and-play model that can be seamlessly integrated with existing TGNs, effectively boosting their performance. To achieve this, we decompose the adaptive neighborhood encoding process into two phases: (i) representative neighbor selection, and (ii) temporal-aware neighborhood information aggregation. Specifically, we propose the Representative Neighbor Selector component, which automatically pinpoints the most important neighbors for the target node. It offers a tailored understanding of each node's unique surrounding context, facilitating personalization. Subsequently, we propose a Temporal-aware Aggregator, which synthesizes neighborhood aggregation by selectively determining the utilization of aggregation routes and decaying the outdated information, allowing our model to adaptively leverage both the contextually significant and current information during aggregation. We conduct extensive experiments by integrating SEAN into three representative TGNs, evaluating their performance on four public datasets and one financial benchmark dataset introduced in this paper. The results demonstrate that SEAN consistently leads to performance improvements across all models, achieving SOTA performance and exceptional robustness.