 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming the Thinker: Conditional Entropy Shaping for Adaptive LLM Reasoning
May 19, 2026Entropy-based deep reasoning has emerged as a promising direction for improving the reasoning capabilities of Large Language Models (LLMs), but existing methods often either increase response length indiscriminately or shorten responses at the cost of accuracy. To better balance this trade-off, we introduce Conditional Entropy Shaping (CES), a framework that dynamically controls token-level response entropy, enabling LLMs to produce concise solutions on simple problems while encouraging deeper exploration on hard ones. Built on DAPO, CES uses token-level entropy as an uncertainty signal and applies a conditional bidirectional policy: it penalizes high-entropy "forking point" tokens on correct reasoning paths to improve conciseness, and rewards them on incorrect paths to encourage exploration and error correction. We implement CES on DeepSeek-R1-Distill-7B and evaluate it on 12 mathematical benchmarks. CES consistently improves average accuracy while reducing response length relative to DAPO, and supplementary experiments show similar trends on a smaller 1.5B backbone and on out-of-domain benchmarks.
TRACER: Verifiable Generative Provenance for Multimodal Tool-Using Agents
May 11, 2026Multimodal large language models increasingly solve vision-centric tasks by calling external tools for visual inspection, OCR, retrieval, calculation, and multi-step reasoning. Current tool-using agents usually expose the executed tool trajectory and the final answer, but they rarely specify which tool observation supports each generated claim. We call this missing claim-level dependency structure the provenance gap. The gap makes tool use hard to verify and hard to optimize, because useful evidence, redundant exploration, and unsupported reasoning are mixed in the same trajectory. We introduce TRACER, a framework for verifiable generative provenance in multimodal tool-using agents. Instead of adding citations after generation, TRACER generates each answer sentence together with a structured provenance record that identifies the supporting tool turn, evidence unit, and semantic support relation. Its relation space contains Quotation, Compression, and Inference, covering direct reuse, faithful condensation, and grounded derivation. TRACER verifies each record through schema checking, tool-turn alignment, source authenticity, and relation rationality, and then converts verified provenance into traceability constraints and provenance-derived local credit for reinforcement learning. We further construct TRACE-Bench, a benchmark for sentence-level provenance reconstruction from coarse multimodal tool trajectories. On TRACE-Bench, simply adding tools often introduces noise. With Qwen3-VL-8B, TRACER reaches 78.23% answer accuracy and 95.72% summary accuracy, outperforming the strongest closed-source tool-augmented baseline by 23.80 percentage points. Compared with tool-only supervised fine-tuning, it also reduces total test-set tool calls from 4949 to 3486. These results show that reliable multimodal tool reasoning depends on provenance-aware use of observations, not on more tool calls alone.
Exact Finite-Sample Variance Decomposition of Subagging: A Spectral Filtering Perspective
Apr 12, 2026Standard resampling ratios (e.g., $α\approx 0.632$) are widely used as default baselines in ensemble learning for three decades. However, how these ratios interact with a base learner's intrinsic functional complexity in finite samples lacks a exact mathematical characterization. We leverage the Hoeffding-ANOVA decomposition to derive the first exact, finite-sample variance decomposition for subagging, applicable to any symmetric base learner without requiring asymptotic limits or smoothness assumptions. We establish that subagging operates as a deterministic low-pass spectral filter: it preserves low-order structural signals while attenuating $c$-th order interaction variance by a geometric factor approaching $α^c$. This decoupling reveals why default baselines often under-regularize high-capacity interpolators, which instead require smaller $α$ to exponentially suppress spurious high-order noise. To operationalize these insights, we propose a complexity-guided adaptive subsampling algorithm, empirically demonstrating that dynamically calibrating $α$ to the learner's complexity spectrum consistently improves generalization over static baselines.
Parser-Oriented Structural Refinement for a Stable Layout Interface in Document Parsing
Apr 03, 2026Accurate document parsing requires both robust content recognition and a stable parser interface. In explicit Document Layout Analysis (DLA) pipelines, downstream parsers do not consume the full detector output. Instead, they operate on a retained and serialized set of layout instances. However, on dense pages with overlapping regions and ambiguous boundaries, unstable layout hypotheses can make the retained instance set inconsistent with its parser input order, leading to severe downstream parsing errors. To address this issue, we introduce a lightweight structural refinement stage between a DETR-style detector and the parser to stabilize the parser interface. Treating raw detector outputs as a compact hypothesis pool, the proposed module performs set-level reasoning over query features, semantic cues, box geometry, and visual evidence. From a shared refined structural state, it jointly determines instance retention, refines box localization, and predicts parser input order before handoff. We further introduce retention-oriented supervision and a difficulty-aware ordering objective to better align the retained instance set and its order with the final parser input, especially on structurally complex pages. Extensive experiments on public benchmarks show that our method consistently improves page-level layout quality. When integrated into a standard end-to-end parsing pipeline, the stabilized parser interface also substantially reduces sequence mismatch, achieving a Reading Order Edit of 0.024 on OmniDocBench.
BeamCKMDiff: Beam-Aware Channel Knowledge Map Construction via Diffusion Transformer
Jan 15, 2026Channel knowledge map (CKM) is emerging as a critical enabler for environment-aware 6G networks, offering a site-specific database to significantly reduce pilot overhead. However, existing CKM construction methods typically rely on sparse sampling measurements and are restricted to either omnidirectional maps or discrete codebooks, hindering the exploitation of beamforming gain. To address these limitations, we propose BeamCKMDiff, a generative framework for constructing high-fidelity CKMs conditioned on arbitrary continuous beamforming vectors without site-specific sampling. Specifically, we incorporate a novel adaptive layer normalization (adaLN) mechanism into the noise prediction network of the Diffusion Transformer (DiT). This mechanism injects continuous beam embeddings as {global control parameters}, effectively steering the generative process to capture the complex coupling between beam patterns and environmental geometries. Simulation results demonstrate that BeamCKMDiff significantly outperforms state-of-the-art baselines, achieving superior reconstruction accuracy in capturing main lobes and side lobes.
BayesRAG: Probabilistic Mutual Evidence Corroboration for Multimodal Retrieval-Augmented Generation
Jan 12, 2026Retrieval-Augmented Generation (RAG) has become a pivotal paradigm for Large Language Models (LLMs), yet current approaches struggle with visually rich documents by treating text and images as isolated retrieval targets. Existing methods relying solely on cosine similarity often fail to capture the semantic reinforcement provided by cross-modal alignment and layout-induced coherence. To address these limitations, we propose BayesRAG, a novel multimodal retrieval framework grounded in Bayesian inference and Dempster-Shafer evidence theory. Unlike traditional approaches that rank candidates strictly by similarity, BayesRAG models the intrinsic consistency of retrieved candidates across modalities as probabilistic evidence to refine retrieval confidence. Specifically, our method computes the posterior association probability for combinations of multimodal retrieval results, prioritizing text-image pairs that mutually corroborate each other in terms of both semantics and layout. Extensive experiments demonstrate that BayesRAG significantly outperforms state-of-the-art (SOTA) methods on challenging multimodal benchmarks. This study establishes a new paradigm for multimodal retrieval fusion that effectively resolves the isolation of heterogeneous modalities through an evidence fusion mechanism and enhances the robustness of retrieval outcomes. Our code is available at https://github.com/TioeAre/BayesRAG.
FocalOrder: Focal Preference Optimization for Reading Order Detection
Jan 12, 2026Reading order detection is the foundation of document understanding. Most existing methods rely on uniform supervision, implicitly assuming a constant difficulty distribution across layout regions. In this work, we challenge this assumption by revealing a critical flaw: \textbf{Positional Disparity}, a phenomenon where models demonstrate mastery over the deterministic start and end regions but suffer a performance collapse in the complex intermediate sections. This degradation arises because standard training allows the massive volume of easy patterns to drown out the learning signals from difficult layouts. To address this, we propose \textbf{FocalOrder}, a framework driven by \textbf{Focal Preference Optimization (FPO)}. Specifically, FocalOrder employs adaptive difficulty discovery with exponential moving average mechanism to dynamically pinpoint hard-to-learn transitions, while introducing a difficulty-calibrated pairwise ranking objective to enforce global logical consistency. Extensive experiments demonstrate that FocalOrder establishes new state-of-the-art results on OmniDocBench v1.0 and Comp-HRDoc. Our compact model not only outperforms competitive specialized baselines but also significantly surpasses large-scale general VLMs. These results demonstrate that aligning the optimization with intrinsic structural ambiguity of documents is critical for mastering complex document structures.
PARL: Position-Aware Relation Learning Network for Document Layout Analysis
Jan 12, 2026Document layout analysis aims to detect and categorize structural elements (e.g., titles, tables, figures) in scanned or digital documents. Popular methods often rely on high-quality Optical Character Recognition (OCR) to merge visual features with extracted text. This dependency introduces two major drawbacks: propagation of text recognition errors and substantial computational overhead, limiting the robustness and practical applicability of multimodal approaches. In contrast to the prevailing multimodal trend, we argue that effective layout analysis depends not on text-visual fusion, but on a deep understanding of documents' intrinsic visual structure. To this end, we propose PARL (Position-Aware Relation Learning Network), a novel OCR-free, vision-only framework that models layout through positional sensitivity and relational structure. Specifically, we first introduce a Bidirectional Spatial Position-Guided Deformable Attention module to embed explicit positional dependencies among layout elements directly into visual features. Second, we design a Graph Refinement Classifier (GRC) to refine predictions by modeling contextual relationships through a dynamically constructed layout graph. Extensive experiments show PARL achieves state-of-the-art results. It establishes a new benchmark for vision-only methods on DocLayNet and, notably, surpasses even strong multimodal models on M6Doc. Crucially, PARL (65M) is highly efficient, using roughly four times fewer parameters than large multimodal models (256M), demonstrating that sophisticated visual structure modeling can be both more efficient and robust than multimodal fusion.
$λ$-GRPO: Unifying the GRPO Frameworks with Learnable Token Preferences
Oct 08, 2025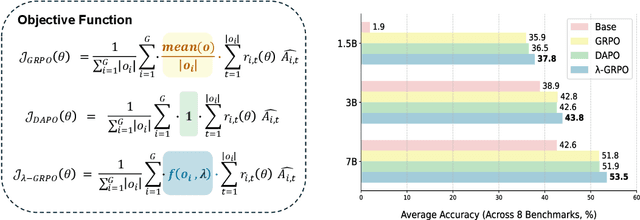
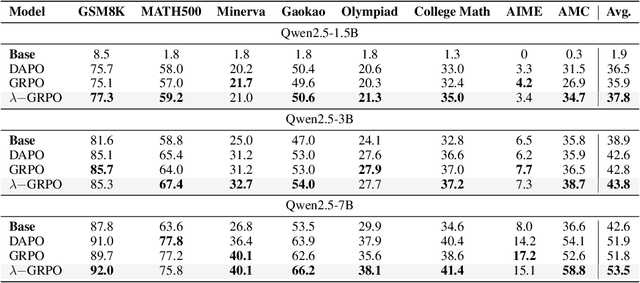
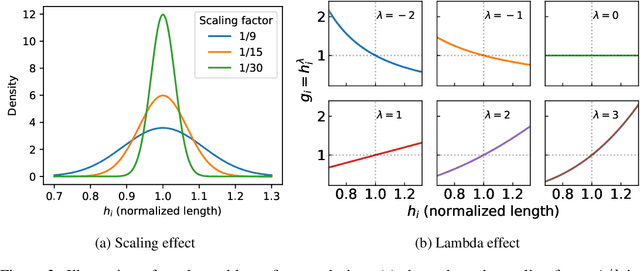

Reinforcement Learning with Human Feedback (RLHF) has been the dominant approach for improving the reasoning capabilities of Large Language Models (LLMs). Recently, Reinforcement Learning with Verifiable Rewards (RLVR) has simplified this paradigm by replacing the reward and value models with rule-based verifiers. A prominent example is Group Relative Policy Optimization (GRPO). However, GRPO inherently suffers from a length bias, since the same advantage is uniformly assigned to all tokens of a response. As a result, longer responses distribute the reward over more tokens and thus contribute disproportionately to gradient updates. Several variants, such as DAPO and Dr. GRPO, modify the token-level aggregation of the loss, yet these methods remain heuristic and offer limited interpretability regarding their implicit token preferences. In this work, we explore the possibility of allowing the model to learn its own token preference during optimization. We unify existing frameworks under a single formulation and introduce a learnable parameter $\lambda$ that adaptively controls token-level weighting. We use $\lambda$-GRPO to denote our method, and we find that $\lambda$-GRPO achieves consistent improvements over vanilla GRPO and DAPO on multiple mathematical reasoning benchmarks. On Qwen2.5 models with 1.5B, 3B, and 7B parameters, $\lambda$-GRPO improves average accuracy by $+1.9\%$, $+1.0\%$, and $+1.7\%$ compared to GRPO, respectively. Importantly, these gains come without any modifications to the training data or additional computational cost, highlighting the effectiveness and practicality of learning token preferences.
ReasoningGuard: Safeguarding Large Reasoning Models with Inference-time Safety Aha Moments
Aug 06, 2025Large Reasoning Models (LRMs) have demonstrated impressive performance in reasoning-intensive tasks, but they remain vulnerable to harmful content generation, particularly in the mid-to-late steps of their reasoning processes. Existing defense mechanisms, however, rely on costly fine-tuning and additional expert knowledge, which restricts their scalability. In this work, we propose ReasoningGuard, an inference-time safeguard for LRMs, which injects timely safety aha moments to steer harmless while helpful reasoning processes. Leveraging the model's internal attention behavior, our approach accurately identifies critical points in the reasoning path, and triggers spontaneous, safety-oriented reflection. To safeguard both the subsequent reasoning steps and the final answers, we further implement a scaling sampling strategy during the decoding phase, selecting the optimal reasoning path. Inducing minimal extra inference cost, ReasoningGuard effectively mitigates three types of jailbreak attacks, including the latest ones targeting the reasoning process of LRMs. Our approach outperforms seven existing safeguards, achieving state-of-the-art safety defenses while effectively avoiding the common exaggerated safety issues.