 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiLDEdit: Reasoning-Based Multi-Layer Design Document Editing
Jan 08, 2026Real-world design documents (e.g., posters) are inherently multi-layered, combining decoration, text, and images. Editing them from natural-language instructions requires fine-grained, layer-aware reasoning to identify relevant layers and coordinate modifications. Prior work largely overlooks multi-layer design document editing, focusing instead on single-layer image editing or multi-layer generation, which assume a flat canvas and lack the reasoning needed to determine what and where to modify. To address this gap, we introduce the Multi-Layer Document Editing Agent (MiLDEAgent), a reasoning-based framework that combines an RL-trained multimodal reasoner for layer-wise understanding with an image editor for targeted modifications. To systematically benchmark this setting, we introduce the MiLDEBench, a human-in-the-loop corpus of over 20K design documents paired with diverse editing instructions. The benchmark is complemented by a task-specific evaluation protocol, MiLDEEval, which spans four dimensions including instruction following, layout consistency, aesthetics, and text rendering. Extensive experiments on 14 open-source and 2 closed-source models reveal that existing approaches fail to generalize: open-source models often cannot complete multi-layer document editing tasks, while closed-source models suffer from format violations. In contrast, MiLDEAgent achieves strong layer-aware reasoning and precise editing, significantly outperforming all open-source baselines and attaining performance comparable to closed-source models, thereby establishing the first strong baseline for multi-layer document editing.
Text-Conditioned Background Generation for Editable Multi-Layer Documents
Dec 19, 2025



We present a framework for document-centric background generation with multi-page editing and thematic continuity. To ensure text regions remain readable, we employ a \emph{latent masking} formulation that softly attenuates updates in the diffusion space, inspired by smooth barrier functions in physics and numerical optimization. In addition, we introduce \emph{Automated Readability Optimization (ARO)}, which automatically places semi-transparent, rounded backing shapes behind text regions. ARO determines the minimal opacity needed to satisfy perceptual contrast standards (WCAG 2.2) relative to the underlying background, ensuring readability while maintaining aesthetic harmony without human intervention. Multi-page consistency is maintained through a summarization-and-instruction process, where each page is distilled into a compact representation that recursively guides subsequent generations. This design reflects how humans build continuity by retaining prior context, ensuring that visual motifs evolve coherently across an entire document. Our method further treats a document as a structured composition in which text, figures, and backgrounds are preserved or regenerated as separate layers, allowing targeted background editing without compromising readability. Finally, user-provided prompts allow stylistic adjustments in color and texture, balancing automated consistency with flexible customization. Our training-free framework produces visually coherent, text-preserving, and thematically aligned documents, bridging generative modeling with natural design workflows.
OIDA-QA: A Multimodal Benchmark for Analyzing the Opioid Industry Documents Archive
Nov 14, 2025The opioid crisis represents a significant moment in public health that reveals systemic shortcomings across regulatory systems, healthcare practices, corporate governance, and public policy. Analyzing how these interconnected systems simultaneously failed to protect public health requires innovative analytic approaches for exploring the vast amounts of data and documents disclosed in the UCSF-JHU Opioid Industry Documents Archive (OIDA). The complexity, multimodal nature, and specialized characteristics of these healthcare-related legal and corporate documents necessitate more advanced methods and models tailored to specific data types and detailed annotations, ensuring the precision and professionalism in the analysis. In this paper, we tackle this challenge by organizing the original dataset according to document attributes and constructing a benchmark with 400k training documents and 10k for testing. From each document, we extract rich multimodal information-including textual content, visual elements, and layout structures-to capture a comprehensive range of features. Using multiple AI models, we then generate a large-scale dataset comprising 360k training QA pairs and 10k testing QA pairs. Building on this foundation, we develop domain-specific multimodal Large Language Models (LLMs) and explore the impact of multimodal inputs on task performance. To further enhance response accuracy, we incorporate historical QA pairs as contextual grounding for answering current queries. Additionally, we incorporate page references within the answers and introduce an importance-based page classifier, further improving the precision and relevance of the information provided. Preliminary results indicate the improvements with our AI assistant in document information extraction and question-answering tasks. The dataset is available at: https://huggingface.co/datasets/opioidarchive/oida-qa
Online Statistical Inference of Constrained Stochastic Optimization via Random Scaling
May 23, 2025Constrained stochastic nonlinear optimization problems have attracted significant attention for their ability to model complex real-world scenarios in physics, economics, and biology. As datasets continue to grow, online inference methods have become crucial for enabling real-time decision-making without the need to store historical data. In this work, we develop an online inference procedure for constrained stochastic optimization by leveraging a method called Sketched Stochastic Sequential Quadratic Programming (SSQP). As a direct generalization of sketched Newton methods, SSQP approximates the objective with a quadratic model and the constraints with a linear model at each step, then applies a sketching solver to inexactly solve the resulting subproblem. Building on this design, we propose a new online inference procedure called random scaling. In particular, we construct a test statistic based on SSQP iterates whose limiting distribution is free of any unknown parameters. Compared to existing online inference procedures, our approach offers two key advantages: (i) it enables the construction of asymptotically valid confidence intervals; and (ii) it is matrix-free, i.e. the computation involves only primal-dual SSQP iterates $(\boldsymbol{x}_t, \boldsymbol{\lambda}_t)$ without requiring any matrix inversions. We validate our theory through numerical experiments on nonlinearly constrained regression problems and demonstrate the superior performance of our random scaling method over existing inference procedures.
Towards Visual Text Grounding of Multimodal Large Language Model
Apr 07, 2025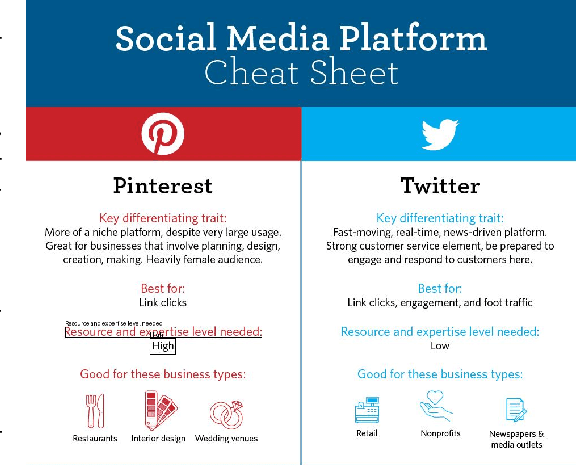


Despite the existing evolution of Multimodal Large Language Models (MLLMs), a non-neglectable limitation remains in their struggle with visual text grounding, especially in text-rich images of documents. Document images, such as scanned forms and infographics, highlight critical challenges due to their complex layouts and textual content. However, current benchmarks do not fully address these challenges, as they mostly focus on visual grounding on natural images, rather than text-rich document images. Thus, to bridge this gap, we introduce TRIG, a novel task with a newly designed instruction dataset for benchmarking and improving the Text-Rich Image Grounding capabilities of MLLMs in document question-answering. Specifically, we propose an OCR-LLM-human interaction pipeline to create 800 manually annotated question-answer pairs as a benchmark and a large-scale training set of 90$ synthetic data based on four diverse datasets. A comprehensive evaluation of various MLLMs on our proposed benchmark exposes substantial limitations in their grounding capability on text-rich images. In addition, we propose two simple and effective TRIG methods based on general instruction tuning and plug-and-play efficient embedding, respectively. By finetuning MLLMs on our synthetic dataset, they promisingly improve spatial reasoning and grounding capabilities.
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Jul 06, 2024The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.
MMWorld: Towards Multi-discipline Multi-faceted World Model Evaluation in Videos
Jun 12, 2024



Multimodal Language Language Models (MLLMs) demonstrate the emerging abilities of "world models" -- interpreting and reasoning about complex real-world dynamics. To assess these abilities, we posit videos are the ideal medium, as they encapsulate rich representations of real-world dynamics and causalities. To this end, we introduce MMWorld, a new benchmark for multi-discipline, multi-faceted multimodal video understanding. MMWorld distinguishes itself from previous video understanding benchmarks with two unique advantages: (1) multi-discipline, covering various disciplines that often require domain expertise for comprehensive understanding; (2) multi-faceted reasoning, including explanation, counterfactual thinking, future prediction, etc. MMWorld consists of a human-annotated dataset to evaluate MLLMs with questions about the whole videos and a synthetic dataset to analyze MLLMs within a single modality of perception. Together, MMWorld encompasses 1,910 videos across seven broad disciplines and 69 subdisciplines, complete with 6,627 question-answer pairs and associated captions. The evaluation includes 2 proprietary and 10 open-source MLLMs, which struggle on MMWorld (e.g., GPT-4V performs the best with only 52.3\% accuracy), showing large room for improvement. Further ablation studies reveal other interesting findings such as models' different skill sets from humans. We hope MMWorld can serve as an essential step towards world model evaluation in videos.
List Items One by One: A New Data Source and Learning Paradigm for Multimodal LLMs
Apr 25, 2024Set-of-Mark (SoM) Prompting unleashes the visual grounding capability of GPT-4V, by enabling the model to associate visual objects with tags inserted on the image. These tags, marked with alphanumerics, can be indexed via text tokens for easy reference. Despite the extraordinary performance from GPT-4V, we observe that other Multimodal Large Language Models (MLLMs) struggle to understand these visual tags. To promote the learning of SoM prompting for open-source models, we propose a new learning paradigm: "list items one by one," which asks the model to enumerate and describe all visual tags placed on the image following the alphanumeric orders of tags. By integrating our curated dataset with other visual instruction tuning datasets, we are able to equip existing MLLMs with the SoM prompting ability. Furthermore, we evaluate our finetuned SoM models on five MLLM benchmarks. We find that this new dataset, even in a relatively small size (10k-30k images with tags), significantly enhances visual reasoning capabilities and reduces hallucinations for MLLMs. Perhaps surprisingly, these improvements persist even when the visual tags are omitted from input images during inference. This suggests the potential of "list items one by one" as a new paradigm for training MLLMs, which strengthens the object-text alignment through the use of visual tags in the training stage. Finally, we conduct analyses by probing trained models to understand the working mechanism of SoM. Our code and data are available at \url{https://github.com/zzxslp/SoM-LLaVA}.
Automatic Layout Planning for Visually-Rich Documents with Instruction-Following Models
Apr 23, 2024



Recent advancements in instruction-following models have made user interactions with models more user-friendly and efficient, broadening their applicability. In graphic design, non-professional users often struggle to create visually appealing layouts due to limited skills and resources. In this work, we introduce a novel multimodal instruction-following framework for layout planning, allowing users to easily arrange visual elements into tailored layouts by specifying canvas size and design purpose, such as for book covers, posters, brochures, or menus. We developed three layout reasoning tasks to train the model in understanding and executing layout instructions. Experiments on two benchmarks show that our method not only simplifies the design process for non-professionals but also surpasses the performance of few-shot GPT-4V models, with mIoU higher by 12% on Crello. This progress highlights the potential of multimodal instruction-following models to automate and simplify the design process, providing an approachable solution for a wide range of design tasks on visually-rich documents.
High Confidence Level Inference is Almost Free using Parallel Stochastic Optimization
Jan 17, 2024Uncertainty quantification for estimation through stochastic optimization solutions in an online setting has gained popularity recently. This paper introduces a novel inference method focused on constructing confidence intervals with efficient computation and fast convergence to the nominal level. Specifically, we propose to use a small number of independent multi-runs to acquire distribution information and construct a t-based confidence interval. Our method requires minimal additional computation and memory beyond the standard updating of estimates, making the inference process almost cost-free. We provide a rigorous theoretical guarantee for the confidence interval, demonstrating that the coverage is approximately exact with an explicit convergence rate and allowing for high confidence level inference. In particular, a new Gaussian approximation result is developed for the online estimators to characterize the coverage properties of our confidence intervals in terms of relative errors. Additionally, our method also allows for leveraging parallel computing to further accelerate calculations using multiple cores. It is easy to implement and can be integrated with existing stochastic algorithms without the need for complicated modifications.