 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Dimensionality for Local and Global Attention
Jun 17, 2026Decoder-only Transformers compute attention over the KV cache of preceding tokens. Keys (and Values) are typically represented with the same dimensionality, regardless of its distance from the prediction target. In natural language, however, the next word is most strongly influenced by the immediately preceding tokens. We hypothesize that local and distant tokens impose asymmetric demands on representational capacity: local tokens are more critical for predicting immediate outputs and thus require richer representations, whereas distant tokens primarily serve as long-range memory, for which lower-dimensional representations may suffice. We formalize this idea as Distance-Adaptive Representation (DAR), implemented in a controlled setting that preserves full-dimensional representations within a local context window while assigning reduced-dimensional representations (e.g. 1/4 of the original dimensionality) to tokens beyond that window. Across multiple pretraining scales (70M to 410M parameters), as well as continued supervised fine-tuning on a 1B-scale model, this approach closely matches the performance of full-dimensional baselines. In contrast, uniformly reducing dimensionality across all token positions leads to worse performance. These results challenge the common assumption that key and value dimensionality should be uniform across token positions. Our findings suggest a new direction for designing attention architectures that adaptively allocate representational capacity across sequences, enabling further reductions in KV cache during inference.
Learning When Not to Attend Globally
Dec 27, 2025When reading books, humans focus primarily on the current page, flipping back to recap prior context only when necessary. Similarly, we demonstrate that Large Language Models (LLMs) can learn to dynamically determine when to attend to global context. We propose All-or-Here Attention (AHA), which utilizes a binary router per attention head to dynamically toggle between full attention and local sliding window attention for each token. Our results indicate that with a window size of 256 tokens, up to 93\% of the original full attention operations can be replaced by sliding window attention without performance loss. Furthermore, by evaluating AHA across various window sizes, we identify a long-tail distribution in context dependency, where the necessity for full attention decays rapidly as the local window expands. By decoupling local processing from global access, AHA reveals that full attention is largely redundant, and that efficient inference requires only on-demand access to the global context.
Context-Aware Language Models for Forecasting Market Impact from Sequences of Financial News
Sep 15, 2025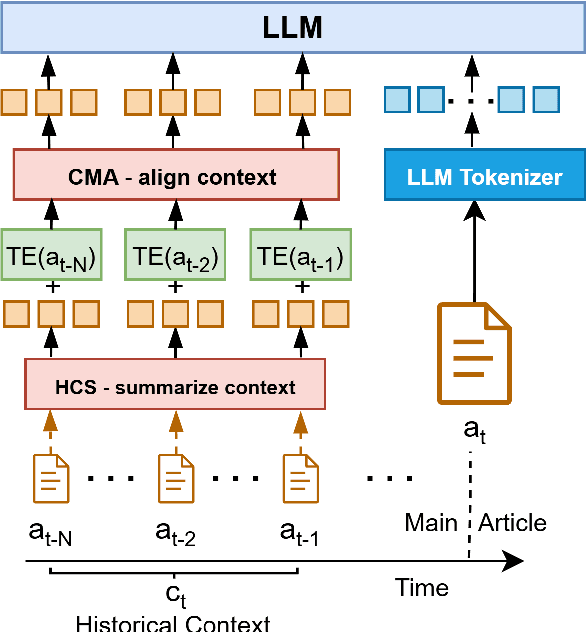
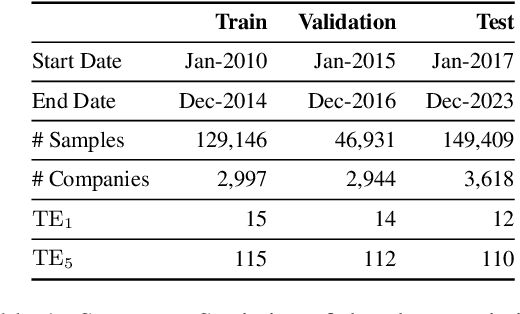
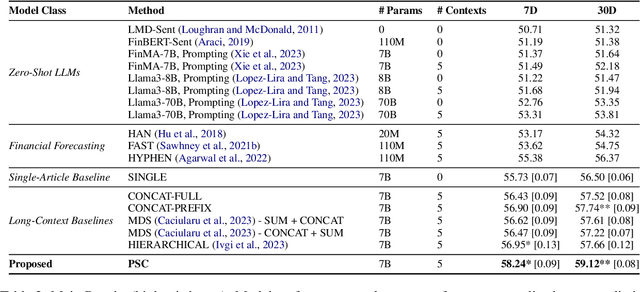

Financial news plays a critical role in the information diffusion process in financial markets and is a known driver of stock prices. However, the information in each news article is not necessarily self-contained, often requiring a broader understanding of the historical news coverage for accurate interpretation. Further, identifying and incorporating the most relevant contextual information presents significant challenges. In this work, we explore the value of historical context in the ability of large language models to understand the market impact of financial news. We find that historical context provides a consistent and significant improvement in performance across methods and time horizons. To this end, we propose an efficient and effective contextualization method that uses a large LM to process the main article, while a small LM encodes the historical context into concise summary embeddings that are then aligned with the large model's representation space. We explore the behavior of the model through multiple qualitative and quantitative interpretability tests and reveal insights into the value of contextualization. Finally, we demonstrate that the value of historical context in model predictions has real-world applications, translating to substantial improvements in simulated investment performance.
Open-Qwen2VL: Compute-Efficient Pre-Training of Fully-Open Multimodal LLMs on Academic Resources
Apr 02, 2025The reproduction of state-of-the-art multimodal LLM pre-training faces barriers at every stage of the pipeline, including high-quality data filtering, multimodal data mixture strategies, sequence packing techniques, and training frameworks. We introduce Open-Qwen2VL, a fully open-source 2B-parameter Multimodal Large Language Model pre-trained efficiently on 29M image-text pairs using only 220 A100-40G GPU hours. Our approach employs low-to-high dynamic image resolution and multimodal sequence packing to significantly enhance pre-training efficiency. The training dataset was carefully curated using both MLLM-based filtering techniques (e.g., MLM-Filter) and conventional CLIP-based filtering methods, substantially improving data quality and training efficiency. The Open-Qwen2VL pre-training is conducted on academic level 8xA100-40G GPUs at UCSB on 5B packed multimodal tokens, which is 0.36% of 1.4T multimodal pre-training tokens of Qwen2-VL. The final instruction-tuned Open-Qwen2VL outperforms partially-open state-of-the-art MLLM Qwen2-VL-2B on various multimodal benchmarks of MMBench, SEEDBench, MMstar, and MathVista, indicating the remarkable training efficiency of Open-Qwen2VL. We open-source all aspects of our work, including compute-efficient and data-efficient training details, data filtering methods, sequence packing scripts, pre-training data in WebDataset format, FSDP-based training codebase, and both base and instruction-tuned model checkpoints. We redefine "fully open" for multimodal LLMs as the complete release of: 1) the training codebase, 2) detailed data filtering techniques, and 3) all pre-training and supervised fine-tuning data used to develop the model.
Adaptive Layer-skipping in Pre-trained LLMs
Mar 31, 2025
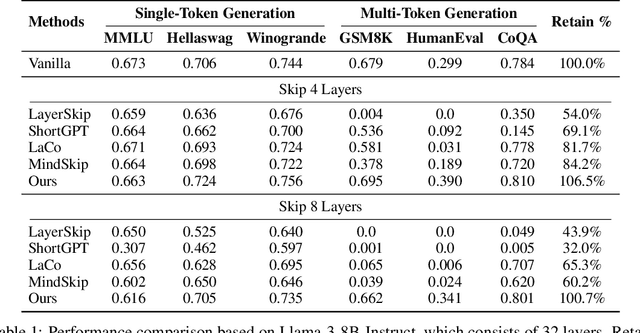
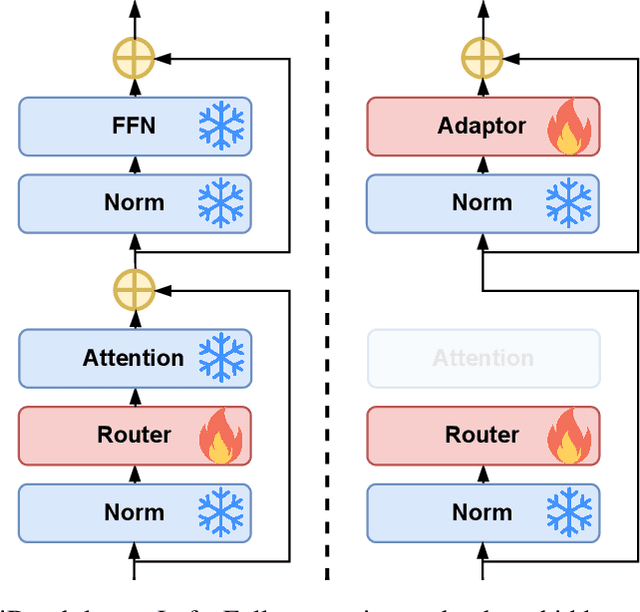
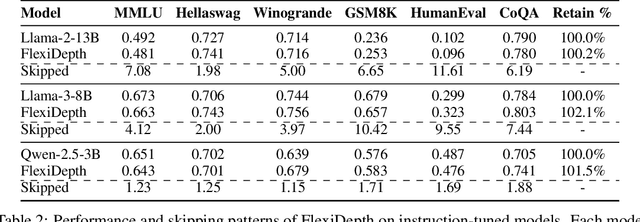
Various layer-skipping methods have been proposed to accelerate token generation in large language models (LLMs). However, they have overlooked a fundamental question: How do computational demands vary across the generation of different tokens? In this work, we introduce FlexiDepth, a method that dynamically adjusts the number of Transformer layers used in text generation. By incorporating a plug-in router and adapter, FlexiDepth enables adaptive layer-skipping in LLMs without modifying their original parameters. Introducing FlexiDepth to Llama-3-8B model achieves layer skipping of 8 layers out of 32, and meanwhile maintains the full 100\% benchmark performance. Experimental results with FlexiDepth demonstrate that computational demands in LLMs significantly vary based on token type. Specifically, generating repetitive tokens or fixed phrases requires fewer layers, whereas producing tokens involving computation or high uncertainty requires more layers. Interestingly, this adaptive allocation pattern aligns with human intuition. To advance research in this area, we open sourced FlexiDepth and a dataset documenting FlexiDepth's layer allocation patterns for future exploration.
AgentOrca: A Dual-System Framework to Evaluate Language Agents on Operational Routine and Constraint Adherence
Mar 11, 2025



As language agents progressively automate critical tasks across domains, their ability to operate within operational constraints and safety protocols becomes essential. While extensive research has demonstrated these agents' effectiveness in downstream task completion, their reliability in following operational procedures and constraints remains largely unexplored. To this end, we present AgentOrca, a dual-system framework for evaluating language agents' compliance with operational constraints and routines. Our framework encodes action constraints and routines through both natural language prompts for agents and corresponding executable code serving as ground truth for automated verification. Through an automated pipeline of test case generation and evaluation across five real-world domains, we quantitatively assess current language agents' adherence to operational constraints. Our findings reveal notable performance gaps among state-of-the-art models, with large reasoning models like o1 demonstrating superior compliance while others show significantly lower performance, particularly when encountering complex constraints or user persuasion attempts.
Creative and Context-Aware Translation of East Asian Idioms with GPT-4
Oct 01, 2024As a type of figurative language, an East Asian idiom condenses rich cultural background into only a few characters. Translating such idioms is challenging for human translators, who often resort to choosing a context-aware translation from an existing list of candidates. However, compiling a dictionary of candidate translations demands much time and creativity even for expert translators. To alleviate such burden, we evaluate if GPT-4 can help generate high-quality translations. Based on automatic evaluations of faithfulness and creativity, we first identify Pareto-optimal prompting strategies that can outperform translation engines from Google and DeepL. Then, at a low cost, our context-aware translations can achieve far more high-quality translations per idiom than the human baseline. We open-source all code and data to facilitate further research.
Can Editing LLMs Inject Harm?
Jul 29, 2024



Knowledge editing techniques have been increasingly adopted to efficiently correct the false or outdated knowledge in Large Language Models (LLMs), due to the high cost of retraining from scratch. Meanwhile, one critical but under-explored question is: can knowledge editing be used to inject harm into LLMs? In this paper, we propose to reformulate knowledge editing as a new type of safety threat for LLMs, namely Editing Attack, and conduct a systematic investigation with a newly constructed dataset EditAttack. Specifically, we focus on two typical safety risks of Editing Attack including Misinformation Injection and Bias Injection. For the risk of misinformation injection, we first categorize it into commonsense misinformation injection and long-tail misinformation injection. Then, we find that editing attacks can inject both types of misinformation into LLMs, and the effectiveness is particularly high for commonsense misinformation injection. For the risk of bias injection, we discover that not only can biased sentences be injected into LLMs with high effectiveness, but also one single biased sentence injection can cause a high bias increase in general outputs of LLMs, which are even highly irrelevant to the injected sentence, indicating a catastrophic impact on the overall fairness of LLMs. Then, we further illustrate the high stealthiness of editing attacks, measured by their impact on the general knowledge and reasoning capacities of LLMs, and show the hardness of defending editing attacks with empirical evidence. Our discoveries demonstrate the emerging misuse risks of knowledge editing techniques on compromising the safety alignment of LLMs.
MMSci: A Multimodal Multi-Discipline Dataset for PhD-Level Scientific Comprehension
Jul 06, 2024The rapid advancement of Large Language Models (LLMs) and Large Multimodal Models (LMMs) has heightened the demand for AI-based scientific assistants capable of understanding scientific articles and figures. Despite progress, there remains a significant gap in evaluating models' comprehension of professional, graduate-level, and even PhD-level scientific content. Current datasets and benchmarks primarily focus on relatively simple scientific tasks and figures, lacking comprehensive assessments across diverse advanced scientific disciplines. To bridge this gap, we collected a multimodal, multidisciplinary dataset from open-access scientific articles published in Nature Communications journals. This dataset spans 72 scientific disciplines, ensuring both diversity and quality. We created benchmarks with various tasks and settings to comprehensively evaluate LMMs' capabilities in understanding scientific figures and content. Our evaluation revealed that these tasks are highly challenging: many open-source models struggled significantly, and even GPT-4V and GPT-4o faced difficulties. We also explored using our dataset as training resources by constructing visual instruction-following data, enabling the 7B LLaVA model to achieve performance comparable to GPT-4V/o on our benchmark. Additionally, we investigated the use of our interleaved article texts and figure images for pre-training LMMs, resulting in improvements on the material generation task. The source dataset, including articles, figures, constructed benchmarks, and visual instruction-following data, is open-sourced.
Finetuned Multimodal Language Models Are High-Quality Image-Text Data Filters
Mar 05, 2024



We propose a novel framework for filtering image-text data by leveraging fine-tuned Multimodal Language Models (MLMs). Our approach outperforms predominant filtering methods (e.g., CLIPScore) via integrating the recent advances in MLMs. We design four distinct yet complementary metrics to holistically measure the quality of image-text data. A new pipeline is established to construct high-quality instruction data for fine-tuning MLMs as data filters. Comparing with CLIPScore, our MLM filters produce more precise and comprehensive scores that directly improve the quality of filtered data and boost the performance of pre-trained models. We achieve significant improvements over CLIPScore on popular foundation models (i.e., CLIP and BLIP2) and various downstream tasks. Our MLM filter can generalize to different models and tasks, and be used as a drop-in replacement for CLIPScore. An additional ablation study is provided to verify our design choices for the MLM filter.