 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniTemp: Unlocking Video Generation in Any Temporal Order via Bidirectional Distillation
Jun 17, 2026Autoregressive video diffusion models have emerged as a promising approach for long video generation, achieving strong performance in streaming settings. However, existing methods are restricted to forward temporal generation, whereas practical video creation often requires flexible generation order, e.g., conditioning on future context to extend backward, or on both past and future context for inbetween generation. We bridge this gap by training an autoregressive model that supports generation in arbitrary temporal directions. A key technical challenge arises from the Causal 3D VAE widely used in video diffusion models, which encodes latents strictly conditioned on past context. While suited for forward generation, this causal structure causes inter-block discontinuities when generation proceeds backward. To address this, we introduce blockwise anchor latents, a set of auxiliary latents that restore the missing past context at block boundaries during backward generation. Built on this design, we propose UniTemp, a bidirectional distillation framework that trains a single autoregressive student model for any-direction video generation. At inference time, UniTemp conditions on arbitrary past and/or future frames, improving controllability for both bidirectional and inbetween generation. Experiments show that UniTemp maintains competitive performance on short and long video generation compared to forward-only methods, while enabling diverse workflows such as bidirectional video extension, inbetween generation, looping video generation, scene transition, and visual story generation. Project website: https://lzhangbj.github.io/projects/unitemp/
A Survey on LLM-based Conversational User Simulation
Apr 27, 2026User simulation has long played a vital role in computer science due to its potential to support a wide range of applications. Language, as the primary medium of human communication, forms the foundation of social interaction and behavior. Consequently, simulating conversational behavior has become a key area of study. Recent advancements in large language models (LLMs) have significantly catalyzed progress in this domain by enabling high-fidelity generation of synthetic user conversation. In this paper, we survey recent advancements in LLM-based conversational user simulation. We introduce a novel taxonomy covering user granularity and simulation objectives. Additionally, we systematically analyze core techniques and evaluation methodologies. We aim to keep the research community informed of the latest advancements in conversational user simulation and to further facilitate future research by identifying open challenges and organizing existing work under a unified framework.
Think, Act, Build: An Agentic Framework with Vision Language Models for Zero-Shot 3D Visual Grounding
Apr 02, 20263D Visual Grounding (3D-VG) aims to localize objects in 3D scenes via natural language descriptions. While recent advancements leveraging Vision-Language Models (VLMs) have explored zero-shot possibilities, they typically suffer from a static workflow relying on preprocessed 3D point clouds, essentially degrading grounding into proposal matching. To bypass this reliance, our core motivation is to decouple the task: leveraging 2D VLMs to resolve complex spatial semantics, while relying on deterministic multi-view geometry to instantiate the 3D structure. Driven by this insight, we propose "Think, Act, Build (TAB)", a dynamic agentic framework that reformulates 3D-VG tasks as a generative 2D-to-3D reconstruction paradigm operating directly on raw RGB-D streams. Specifically, guided by a specialized 3D-VG skill, our VLM agent dynamically invokes visual tools to track and reconstruct the target across 2D frames. Crucially, to overcome the multi-view coverage deficit caused by strict VLM semantic tracking, we introduce the Semantic-Anchored Geometric Expansion, a mechanism that first anchors the target in a reference video clip and then leverages multi-view geometry to propagate its spatial location across unobserved frames. This enables the agent to "Build" the target's 3D representation by aggregating these multi-view features via camera parameters, directly mapping 2D visual cues to 3D coordinates. Furthermore, to ensure rigorous assessment, we identify flaws such as reference ambiguity and category errors in existing benchmarks and manually refine the incorrect queries. Extensive experiments on ScanRefer and Nr3D demonstrate that our framework, relying entirely on open-source models, significantly outperforms previous zero-shot methods and even surpasses fully supervised baselines.
MiLDEdit: Reasoning-Based Multi-Layer Design Document Editing
Jan 08, 2026Real-world design documents (e.g., posters) are inherently multi-layered, combining decoration, text, and images. Editing them from natural-language instructions requires fine-grained, layer-aware reasoning to identify relevant layers and coordinate modifications. Prior work largely overlooks multi-layer design document editing, focusing instead on single-layer image editing or multi-layer generation, which assume a flat canvas and lack the reasoning needed to determine what and where to modify. To address this gap, we introduce the Multi-Layer Document Editing Agent (MiLDEAgent), a reasoning-based framework that combines an RL-trained multimodal reasoner for layer-wise understanding with an image editor for targeted modifications. To systematically benchmark this setting, we introduce the MiLDEBench, a human-in-the-loop corpus of over 20K design documents paired with diverse editing instructions. The benchmark is complemented by a task-specific evaluation protocol, MiLDEEval, which spans four dimensions including instruction following, layout consistency, aesthetics, and text rendering. Extensive experiments on 14 open-source and 2 closed-source models reveal that existing approaches fail to generalize: open-source models often cannot complete multi-layer document editing tasks, while closed-source models suffer from format violations. In contrast, MiLDEAgent achieves strong layer-aware reasoning and precise editing, significantly outperforming all open-source baselines and attaining performance comparable to closed-source models, thereby establishing the first strong baseline for multi-layer document editing.
SuperFlow: Training Flow Matching Models with RL on the Fly
Dec 17, 2025Recent progress in flow-based generative models and reinforcement learning (RL) has improved text-image alignment and visual quality. However, current RL training for flow models still has two main problems: (i) GRPO-style fixed per-prompt group sizes ignore variation in sampling importance across prompts, which leads to inefficient sampling and slower training; and (ii) trajectory-level advantages are reused as per-step estimates, which biases credit assignment along the flow. We propose SuperFlow, an RL training framework for flow-based models that adjusts group sizes with variance-aware sampling and computes step-level advantages in a way that is consistent with continuous-time flow dynamics. Empirically, SuperFlow reaches promising performance while using only 5.4% to 56.3% of the original training steps and reduces training time by 5.2% to 16.7% without any architectural changes. On standard text-to-image (T2I) tasks, including text rendering, compositional image generation, and human preference alignment, SuperFlow improves over SD3.5-M by 4.6% to 47.2%, and over Flow-GRPO by 1.7% to 16.0%.
Simple Lines, Big Ideas: Towards Interpretable Assessment of Human Creativity from Drawings
Nov 17, 2025Assessing human creativity through visual outputs, such as drawings, plays a critical role in fields including psychology, education, and cognitive science. However, current assessment practices still rely heavily on expert-based subjective scoring, which is both labor-intensive and inherently subjective. In this paper, we propose a data-driven framework for automatic and interpretable creativity assessment from drawings. Motivated by the cognitive understanding that creativity can emerge from both what is drawn (content) and how it is drawn (style), we reinterpret the creativity score as a function of these two complementary dimensions.Specifically, we first augment an existing creativity labeled dataset with additional annotations targeting content categories. Based on the enriched dataset, we further propose a multi-modal, multi-task learning framework that simultaneously predicts creativity scores, categorizes content types, and extracts stylistic features. In particular, we introduce a conditional learning mechanism that enables the model to adapt its visual feature extraction by dynamically tuning it to creativity-relevant signals conditioned on the drawing's stylistic and semantic cues.Experimental results demonstrate that our model achieves state-of-the-art performance compared to existing regression-based approaches and offers interpretable visualizations that align well with human judgments. The code and annotations will be made publicly available at https://github.com/WonderOfU9/CSCA_PRCV_2025
R2I-Bench: Benchmarking Reasoning-Driven Text-to-Image Generation
May 29, 2025

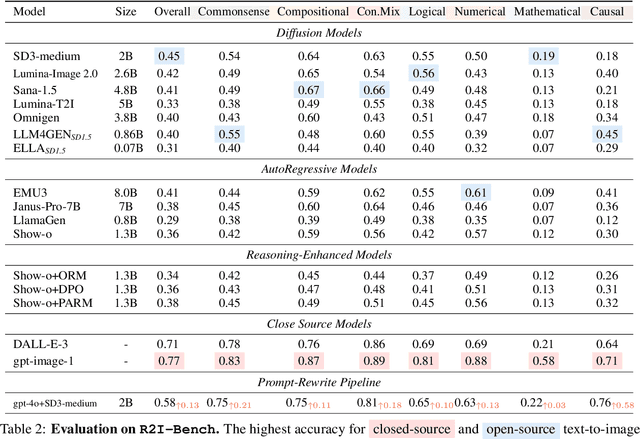

Reasoning is a fundamental capability often required in real-world text-to-image (T2I) generation, e.g., generating ``a bitten apple that has been left in the air for more than a week`` necessitates understanding temporal decay and commonsense concepts. While recent T2I models have made impressive progress in producing photorealistic images, their reasoning capability remains underdeveloped and insufficiently evaluated. To bridge this gap, we introduce R2I-Bench, a comprehensive benchmark specifically designed to rigorously assess reasoning-driven T2I generation. R2I-Bench comprises meticulously curated data instances, spanning core reasoning categories, including commonsense, mathematical, logical, compositional, numerical, causal, and concept mixing. To facilitate fine-grained evaluation, we design R2IScore, a QA-style metric based on instance-specific, reasoning-oriented evaluation questions that assess three critical dimensions: text-image alignment, reasoning accuracy, and image quality. Extensive experiments with 16 representative T2I models, including a strong pipeline-based framework that decouples reasoning and generation using the state-of-the-art language and image generation models, demonstrate consistently limited reasoning performance, highlighting the need for more robust, reasoning-aware architectures in the next generation of T2I systems. Project Page: https://r2i-bench.github.io
Localizing Knowledge in Diffusion Transformers
May 24, 2025Understanding how knowledge is distributed across the layers of generative models is crucial for improving interpretability, controllability, and adaptation. While prior work has explored knowledge localization in UNet-based architectures, Diffusion Transformer (DiT)-based models remain underexplored in this context. In this paper, we propose a model- and knowledge-agnostic method to localize where specific types of knowledge are encoded within the DiT blocks. We evaluate our method on state-of-the-art DiT-based models, including PixArt-alpha, FLUX, and SANA, across six diverse knowledge categories. We show that the identified blocks are both interpretable and causally linked to the expression of knowledge in generated outputs. Building on these insights, we apply our localization framework to two key applications: model personalization and knowledge unlearning. In both settings, our localized fine-tuning approach enables efficient and targeted updates, reducing computational cost, improving task-specific performance, and better preserving general model behavior with minimal interference to unrelated or surrounding content. Overall, our findings offer new insights into the internal structure of DiTs and introduce a practical pathway for more interpretable, efficient, and controllable model editing.
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.
Knowing When to Stop: Dynamic Context Cutoff for Large Language Models
Feb 03, 2025



Large language models (LLMs) process entire input contexts indiscriminately, which is inefficient in cases where the information required to answer a query is localized within the context. We present dynamic context cutoff, a human-inspired method enabling LLMs to self-terminate processing upon acquiring sufficient task-relevant information. Through analysis of model internals, we discover that specific attention heads inherently encode "sufficiency signals" - detectable through lightweight classifiers - that predict when critical information has been processed. This reveals a new efficiency paradigm: models' internal understanding naturally dictates processing needs rather than external compression heuristics. Comprehensive experiments across six QA datasets (up to 40K tokens) with three model families (LLaMA/Qwen/Mistral, 1B0-70B) demonstrate 1.33x average token reduction while improving accuracy by 1.3%. Furthermore, our method demonstrates better performance with the same rate of token reduction compared to other context efficiency methods. Additionally, we observe an emergent scaling phenomenon: while smaller models require require probing for sufficiency detection, larger models exhibit intrinsic self-assessment capabilities through prompting.